 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Overlapping Asymmetric Datasets -- A Twice Penalized P-Spline Approach
Nov 20, 2023


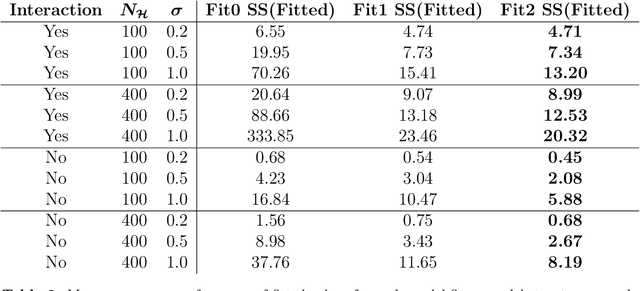
Overlapping asymmetric datasets are common in data science and pose questions of how they can be incorporated together into a predictive analysis. In healthcare datasets there is often a small amount of information that is available for a larger number of patients such as an electronic health record, however a small number of patients may have had extensive further testing. Common solutions such as missing imputation can often be unwise if the smaller cohort is significantly different in scale to the larger sample, therefore the aim of this research is to develop a new method which can model the smaller cohort against a particular response, whilst considering the larger cohort also. Motivated by non-parametric models, and specifically flexible smoothing techniques via generalized additive models, we model a twice penalized P-Spline approximation method to firstly prevent over/under-fitting of the smaller cohort and secondly to consider the larger cohort. This second penalty is created through discrepancies in the marginal value of covariates that exist in both the smaller and larger cohorts. Through data simulations, parameter tunings and model adaptations to consider a continuous and binary response, we find our twice penalized approach offers an enhanced fit over a linear B-Spline and once penalized P-Spline approximation. Applying to a real-life dataset relating to a person's risk of developing Non-Alcoholic Steatohepatitis, we see an improved model fit performance of over 65%. Areas for future work within this space include adapting our method to not require dimensionality reduction and also consider parametric modelling methods. However, to our knowledge this is the first work to propose additional marginal penalties in a flexible regression of which we can report a vastly improved model fit that is able to consider asymmetric datasets, without the need for missing data imputation.
ConvBoost: Boosting ConvNets for Sensor-based Activity Recognition
May 22, 2023
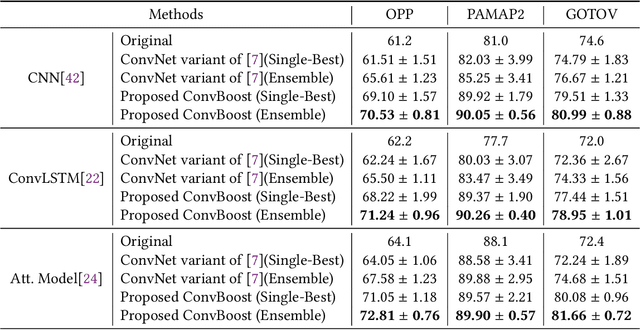
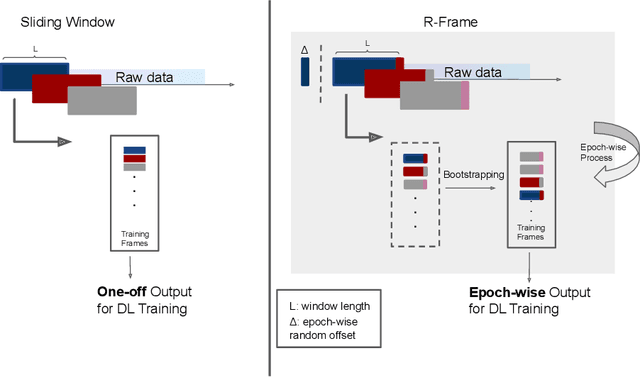
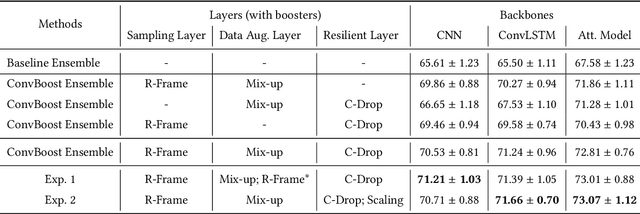
Human activity recognition (HAR) is one of the core research themes in ubiquitous and wearable computing. With the shift to deep learning (DL) based analysis approaches, it has become possible to extract high-level features and perform classification in an end-to-end manner. Despite their promising overall capabilities, DL-based HAR may suffer from overfitting due to the notoriously small, often inadequate, amounts of labeled sample data that are available for typical HAR applications. In response to such challenges, we propose ConvBoost -- a novel, three-layer, structured model architecture and boosting framework for convolutional network based HAR. Our framework generates additional training data from three different perspectives for improved HAR, aiming to alleviate the shortness of labeled training data in the field. Specifically, with the introduction of three conceptual layers--Sampling Layer, Data Augmentation Layer, and Resilient Layer -- we develop three "boosters" -- R-Frame, Mix-up, and C-Drop -- to enrich the per-epoch training data by dense-sampling, synthesizing, and simulating, respectively. These new conceptual layers and boosters, that are universally applicable for any kind of convolutional network, have been designed based on the characteristics of the sensor data and the concept of frame-wise HAR. In our experimental evaluation on three standard benchmarks (Opportunity, PAMAP2, GOTOV) we demonstrate the effectiveness of our ConvBoost framework for HAR applications based on variants of convolutional networks: vanilla CNN, ConvLSTM, and Attention Models. We achieved substantial performance gains for all of them, which suggests that the proposed approach is generic and can serve as a practical solution for boosting the performance of existing ConvNet-based HAR models. This is an open-source project, and the code can be found at https://github.com/sshao2013/ConvBoost
* 21 pages
Simple Yet Surprisingly Effective Training Strategies for LSTMs in Sensor-Based Human Activity Recognition
Dec 23, 2022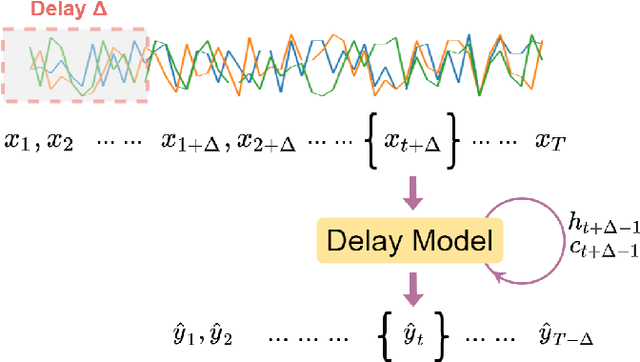
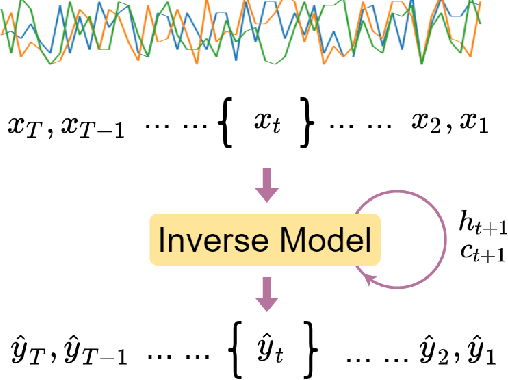
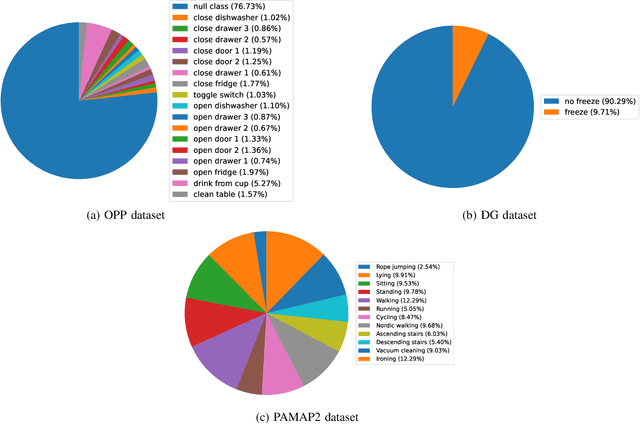
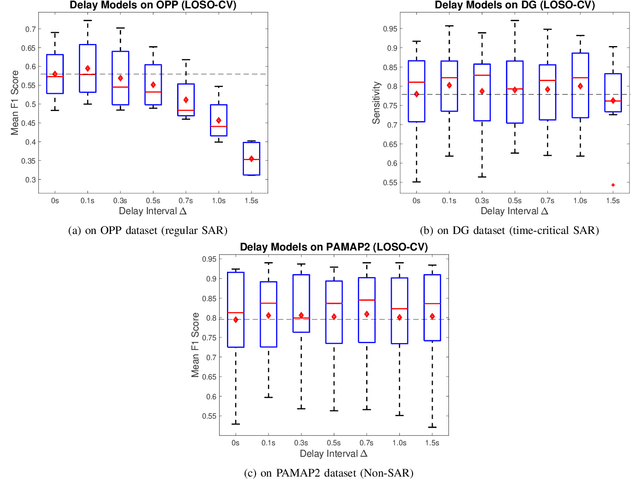
Human Activity Recognition (HAR) is one of the core research areas in mobile and wearable computing. With the application of deep learning (DL) techniques such as CNN, recognizing periodic or static activities (e.g, walking, lying, cycling, etc.) has become a well studied problem. What remains a major challenge though is the sporadic activity recognition (SAR) problem, where activities of interest tend to be non periodic, and occur less frequently when compared with the often large amount of irrelevant background activities. Recent works suggested that sequential DL models (such as LSTMs) have great potential for modeling nonperiodic behaviours, and in this paper we studied some LSTM training strategies for SAR. Specifically, we proposed two simple yet effective LSTM variants, namely delay model and inverse model, for two SAR scenarios (with and without time critical requirement). For time critical SAR, the delay model can effectively exploit predefined delay intervals (within tolerance) in form of contextual information for improved performance. For regular SAR task, the second proposed, inverse model can learn patterns from the time series in an inverse manner, which can be complementary to the forward model (i.e.,LSTM), and combining both can boost the performance. These two LSTM variants are very practical, and they can be deemed as training strategies without alteration of the LSTM fundamentals. We also studied some additional LSTM training strategies, which can further improve the accuracy. We evaluated our models on two SAR and one non-SAR datasets, and the promising results demonstrated the effectiveness of our approaches in HAR applications.
Benchmark time series data sets for PyTorch -- the torchtime package
Aug 01, 2022The development of models for Electronic Health Record data is an area of active research featuring a small number of public benchmark data sets. Researchers typically write custom data processing code but this hinders reproducibility and can introduce errors. The Python package torchtime provides reproducible implementations of commonly used PhysioNet and UEA & UCR time series classification repository data sets for PyTorch. Features are provided for working with irregularly sampled and partially observed time series of unequal length. It aims to simplify access to PhysioNet data and enable fair comparisons of models in this exciting area of research.
Technologies for Trustworthy Machine Learning: A Survey in a Socio-Technical Context
Jul 17, 2020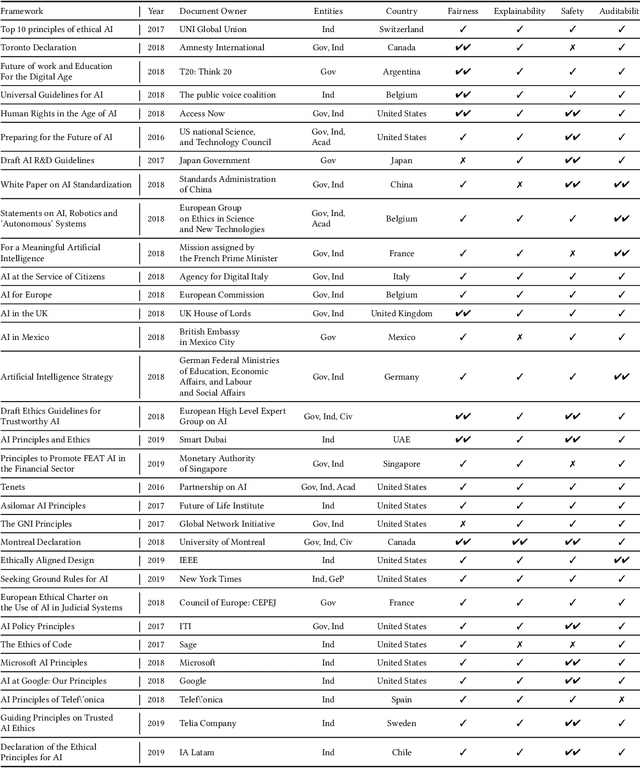
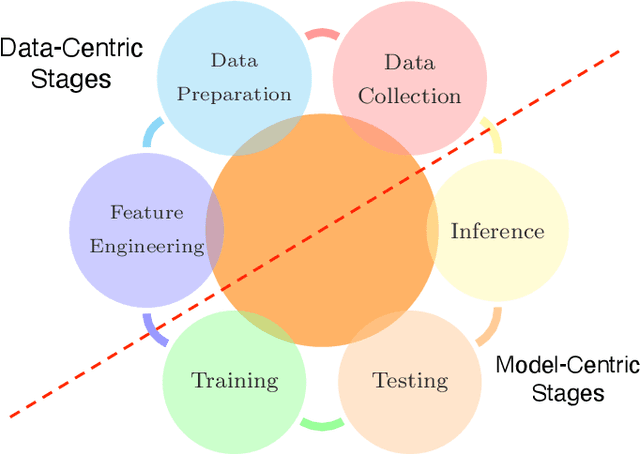
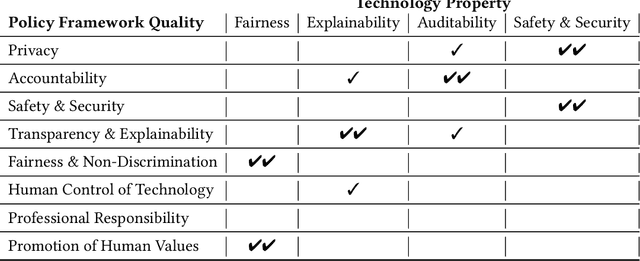
Concerns about the societal impact of AI-based services and systems has encouraged governments and other organisations around the world to propose AI policy frameworks to address fairness, accountability, transparency and related topics. To achieve the objectives of these frameworks, the data and software engineers who build machine-learning systems require knowledge about a variety of relevant supporting tools and techniques. In this paper we provide an overview of technologies that support building trustworthy machine learning systems, i.e., systems whose properties justify that people place trust in them. We argue that four categories of system properties are instrumental in achieving the policy objectives, namely fairness, explainability, auditability and safety & security (FEAS). We discuss how these properties need to be considered across all stages of the machine learning life cycle, from data collection through run-time model inference. As a consequence, we survey in this paper the main technologies with respect to all four of the FEAS properties, for data-centric as well as model-centric stages of the machine learning system life cycle. We conclude with an identification of open research problems, with a particular focus on the connection between trustworthy machine learning technologies and their implications for individuals and society.
Building Rule Hierarchies for Efficient Logical Rule Learning from Knowledge Graphs
Jun 30, 2020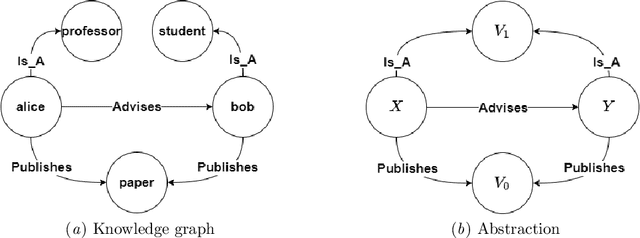
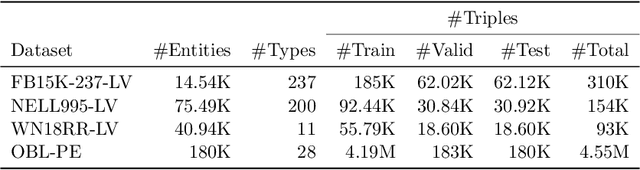
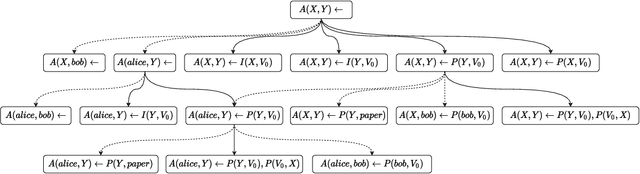
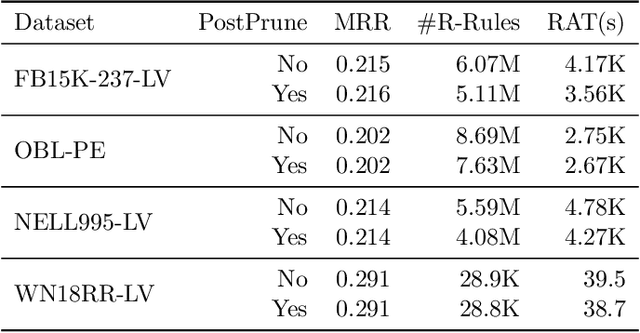
Many systems have been developed in recent years to mine logical rules from large-scale Knowledge Graphs (KGs), on the grounds that representing regularities as rules enables both the interpretable inference of new facts, and the explanation of known facts. Among these systems, the walk-based methods that generate the instantiated rules containing constants by abstracting sampled paths in KGs demonstrate strong predictive performance and expressivity. However, due to the large volume of possible rules, these systems do not scale well where computational resources are often wasted on generating and evaluating unpromising rules. In this work, we address such scalability issues by proposing new methods for pruning unpromising rules using rule hierarchies. The approach consists of two phases. Firstly, since rule hierarchies are not readily available in walk-based methods, we have built a Rule Hierarchy Framework (RHF), which leverages a collection of subsumption frameworks to build a proper rule hierarchy from a set of learned rules. And secondly, we adapt RHF to an existing rule learner where we design and implement two methods for Hierarchical Pruning (HPMs), which utilize the generated hierarchies to remove irrelevant and redundant rules. Through experiments over four public benchmark datasets, we show that the application of HPMs is effective in removing unpromising rules, which leads to significant reductions in the runtime as well as in the number of learned rules, without compromising the predictive performance.
Efficient Rule Learning with Template Saturation for Knowledge Graph Completion
Mar 13, 2020
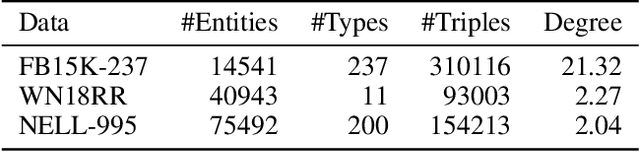
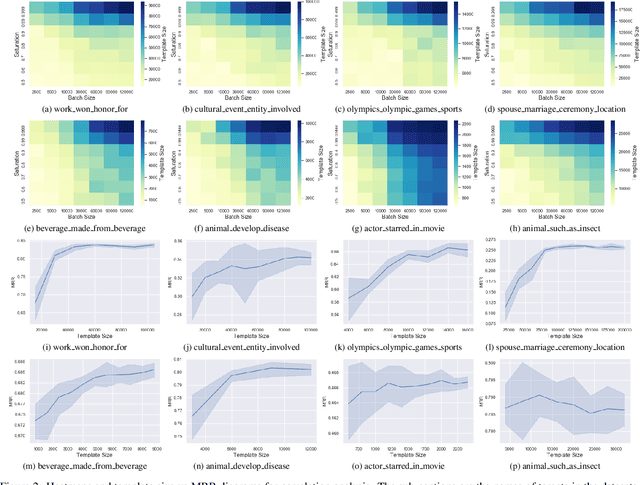
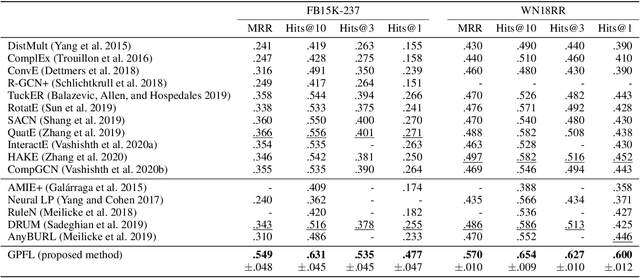
The logic-based methods that learn first-order rules from knowledge graphs (KGs) for knowledge graph completion (KGC) task are desirable in that the learnt models are inductive, interpretable and transferable. The challenge in such rule learners is that the expressive rules are often buried in vast rule space, and the procedure of identifying expressive rules by measuring rule quality is costly to execute. Therefore, optimizations on rule generation and evaluation are in need. In this work, we propose a novel bottom-up probabilistic rule learner that features: 1.) a two-stage procedure for optimized rule generation where the system first generalizes paths sampled from a KG into template rules that contain no constants until a certain degree of template saturation is achieved and then specializes template rules into instantiated rules that contain constants; 2.) a grouping technique for optimized rule evaluation where structurally similar instantiated rules derived from the same template rules are put into the same groups and evaluated collectively over the groundings of the deriving template rules. Through extensive experiments over large benchmark datasets on KGC task, our algorithm demonstrates consistent and substantial performance improvements over all of the state-of-the-art baselines.
Recruiting from the network: discovering Twitter users who can help combat Zika epidemics
Mar 11, 2017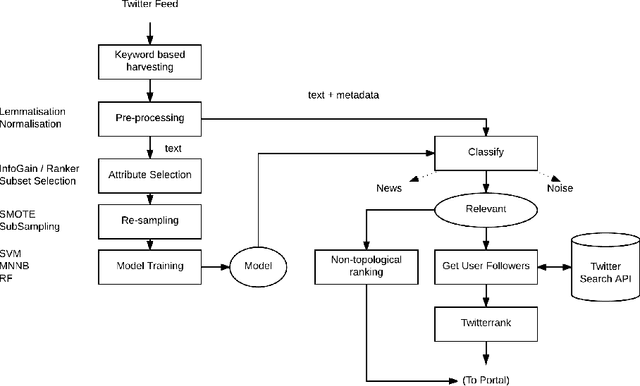
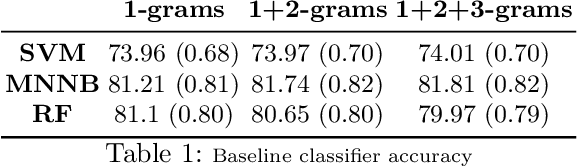

Tropical diseases like \textit{Chikungunya} and \textit{Zika} have come to prominence in recent years as the cause of serious, long-lasting, population-wide health problems. In large countries like Brasil, traditional disease prevention programs led by health authorities have not been particularly effective. We explore the hypothesis that monitoring and analysis of social media content streams may effectively complement such efforts. Specifically, we aim to identify selected members of the public who are likely to be sensitive to virus combat initiatives that are organised in local communities. Focusing on Twitter and on the topic of Zika, our approach involves (i) training a classifier to select topic-relevant tweets from the Twitter feed, and (ii) discovering the top users who are actively posting relevant content about the topic. We may then recommend these users as the prime candidates for direct engagement within their community. In this short paper we describe our analytical approach and prototype architecture, discuss the challenges of dealing with noisy and sparse signal, and present encouraging preliminary results.