 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment analysis in tweets: an assessment study from classical to modern text representation models
May 29, 2021


With the growth of social medias, such as Twitter, plenty of user-generated data emerge daily. The short texts published on Twitter -- the tweets -- have earned significant attention as a rich source of information to guide many decision-making processes. However, their inherent characteristics, such as the informal, and noisy linguistic style, remain challenging to many natural language processing (NLP) tasks, including sentiment analysis. Sentiment classification is tackled mainly by machine learning-based classifiers. The literature has adopted word representations from distinct natures to transform tweets to vector-based inputs to feed sentiment classifiers. The representations come from simple count-based methods, such as bag-of-words, to more sophisticated ones, such as BERTweet, built upon the trendy BERT architecture. Nevertheless, most studies mainly focus on evaluating those models using only a small number of datasets. Despite the progress made in recent years in language modelling, there is still a gap regarding a robust evaluation of induced embeddings applied to sentiment analysis on tweets. Furthermore, while fine-tuning the model from downstream tasks is prominent nowadays, less attention has been given to adjustments based on the specific linguistic style of the data. In this context, this study fulfils an assessment of existing language models in distinguishing the sentiment expressed in tweets by using a rich collection of 22 datasets from distinct domains and five classification algorithms. The evaluation includes static and contextualized representations. Contexts are assembled from Transformer-based autoencoder models that are also fine-tuned based on the masked language model task, using a plethora of strategies.
MineReduce: an approach based on data mining for problem size reduction
May 22, 2020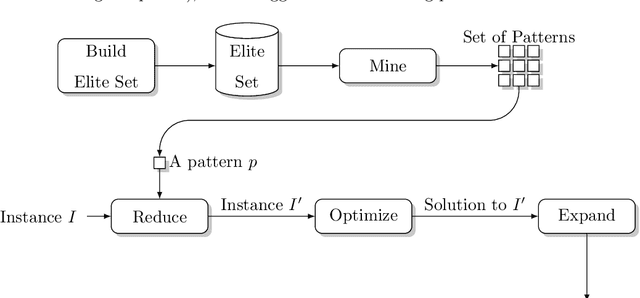
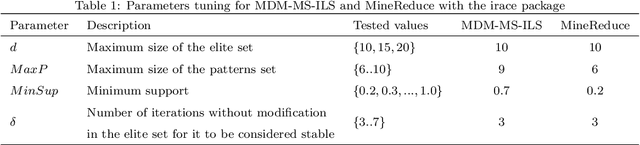
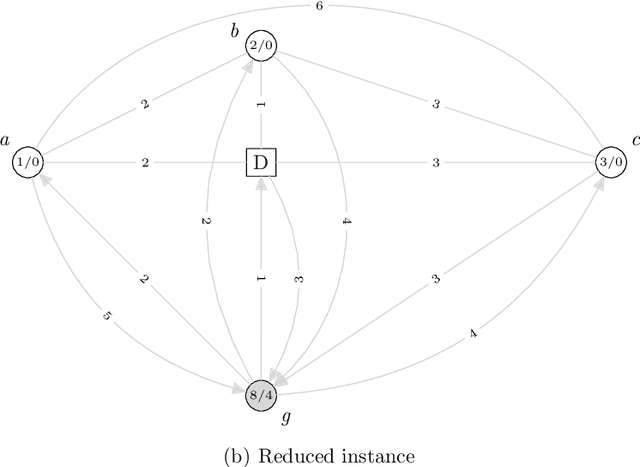
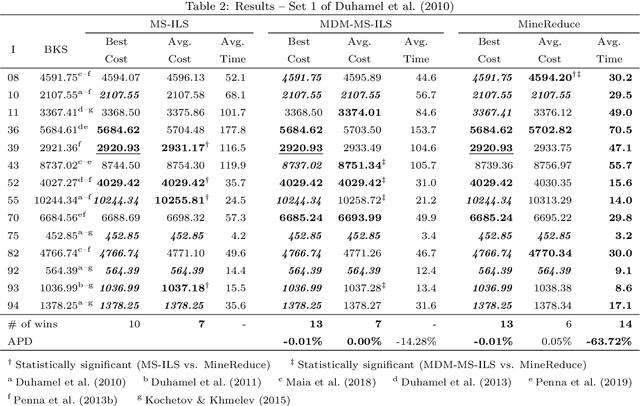
Hybrid variations of metaheuristics that include data mining strategies have been utilized to solve a variety of combinatorial optimization problems, with superior and encouraging results. Previous hybrid strategies applied mined patterns to guide the construction of initial solutions, leading to more effective exploration of the solution space. Solving a combinatorial optimization problem is usually a hard task because its solution space grows exponentially with its size. Therefore, problem size reduction is also a useful strategy in this context, especially in the case of large-scale problems. In this paper, we build upon these ideas by presenting an approach named MineReduce, which uses mined patterns to perform problem size reduction. We present an application of MineReduce to improve a heuristic for the heterogeneous fleet vehicle routing problem. The results obtained in computational experiments show that this proposed heuristic demonstrates superior performance compared to the original heuristic and other state-of-the-art heuristics, achieving better solution costs with shorter run times.
Recruiting from the network: discovering Twitter users who can help combat Zika epidemics
Mar 11, 2017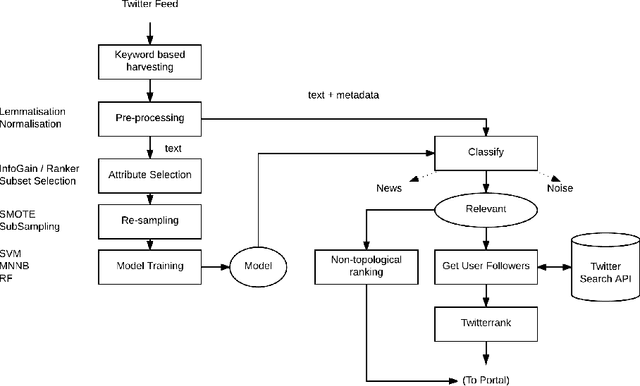
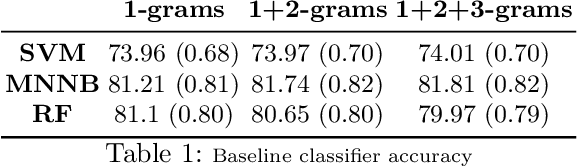

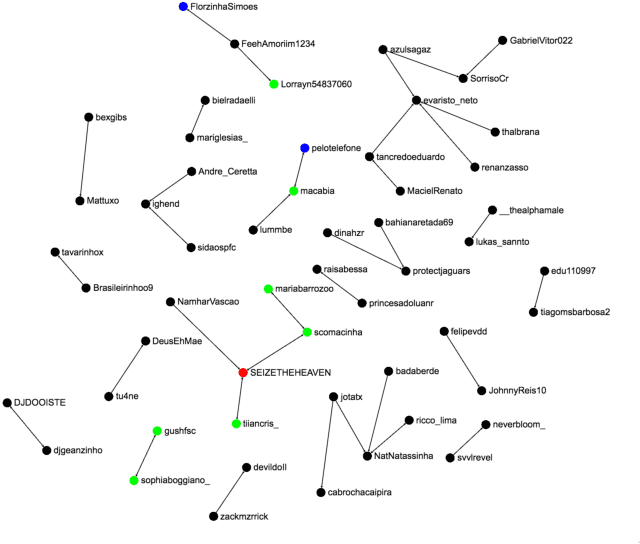
Tropical diseases like \textit{Chikungunya} and \textit{Zika} have come to prominence in recent years as the cause of serious, long-lasting, population-wide health problems. In large countries like Brasil, traditional disease prevention programs led by health authorities have not been particularly effective. We explore the hypothesis that monitoring and analysis of social media content streams may effectively complement such efforts. Specifically, we aim to identify selected members of the public who are likely to be sensitive to virus combat initiatives that are organised in local communities. Focusing on Twitter and on the topic of Zika, our approach involves (i) training a classifier to select topic-relevant tweets from the Twitter feed, and (ii) discovering the top users who are actively posting relevant content about the topic. We may then recommend these users as the prime candidates for direct engagement within their community. In this short paper we describe our analytical approach and prototype architecture, discuss the challenges of dealing with noisy and sparse signal, and present encouraging preliminary results.