 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-CRAFT: Knowledge Graph-based Contrastive Reasoning with LLMs for Enhancing Automated Fact-checking
Jan 27, 2026Claim verification is a core component of automated fact-checking systems, aimed at determining the truthfulness of a statement by assessing it against reliable evidence sources such as documents or knowledge bases. This work presents KG-CRAFT, a method that improves automatic claim verification by leveraging large language models (LLMs) augmented with contrastive questions grounded in a knowledge graph. KG-CRAFT first constructs a knowledge graph from claims and associated reports, then formulates contextually relevant contrastive questions based on the knowledge graph structure. These questions guide the distillation of evidence-based reports, which are synthesised into a concise summary that is used for veracity assessment by LLMs. Extensive evaluations on two real-world datasets (LIAR-RAW and RAWFC) demonstrate that our method achieves a new state-of-the-art in predictive performance. Comprehensive analyses validate in detail the effectiveness of our knowledge graph-based contrastive reasoning approach in improving LLMs' fact-checking capabilities.
Datasets for Portuguese Legal Semantic Textual Similarity: Comparing weak supervision and an annotation process approaches
May 29, 2023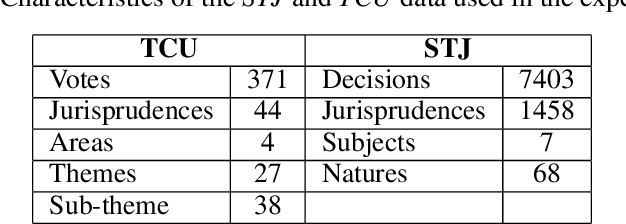
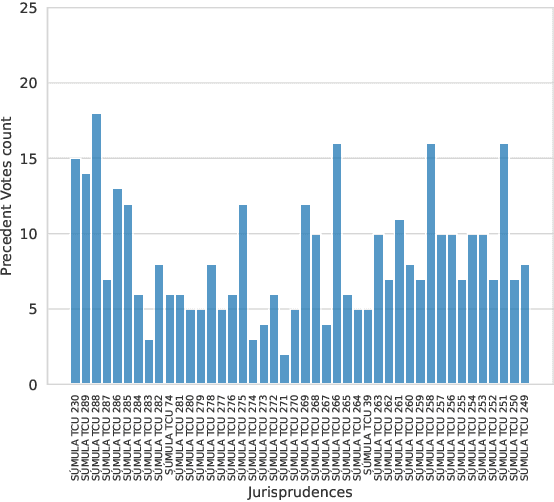
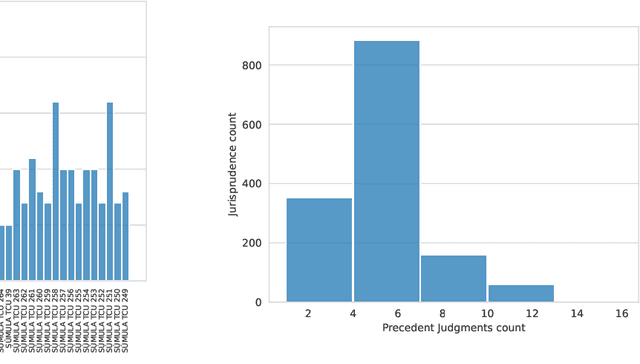

The Brazilian judiciary has a large workload, resulting in a long time to finish legal proceedings. Brazilian National Council of Justice has established in Resolution 469/2022 formal guidance for document and process digitalization opening up the possibility of using automatic techniques to help with everyday tasks in the legal field, particularly in a large number of texts yielded on the routine of law procedures. Notably, Artificial Intelligence (AI) techniques allow for processing and extracting useful information from textual data, potentially speeding up the process. However, datasets from the legal domain required by several AI techniques are scarce and difficult to obtain as they need labels from experts. To address this challenge, this article contributes with four datasets from the legal domain, two with documents and metadata but unlabeled, and another two labeled with a heuristic aiming at its use in textual semantic similarity tasks. Also, to evaluate the effectiveness of the proposed heuristic label process, this article presents a small ground truth dataset generated from domain expert annotations. The analysis of ground truth labels highlights that semantic analysis of domain text can be challenging even for domain experts. Also, the comparison between ground truth and heuristic labels shows that heuristic labels are useful.
A Modality-level Explainable Framework for Misinformation Checking in Social Networks
Dec 08, 2022


The widespread of false information is a rising concern worldwide with critical social impact, inspiring the emergence of fact-checking organizations to mitigate misinformation dissemination. However, human-driven verification leads to a time-consuming task and a bottleneck to have checked trustworthy information at the same pace they emerge. Since misinformation relates not only to the content itself but also to other social features, this paper addresses automatic misinformation checking in social networks from a multimodal perspective. Moreover, as simply naming a piece of news as incorrect may not convince the citizen and, even worse, strengthen confirmation bias, the proposal is a modality-level explainable-prone misinformation classifier framework. Our framework comprises a misinformation classifier assisted by explainable methods to generate modality-oriented explainable inferences. Preliminary findings show that the misinformation classifier does benefit from multimodal information encoding and the modality-oriented explainable mechanism increases both inferences' interpretability and completeness.
Learning Attention-based Representations from Multiple Patterns for Relation Prediction in Knowledge Graphs
Jun 07, 2022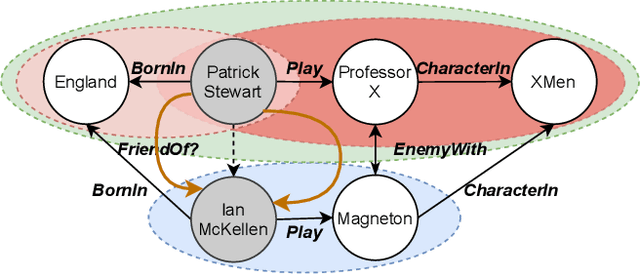
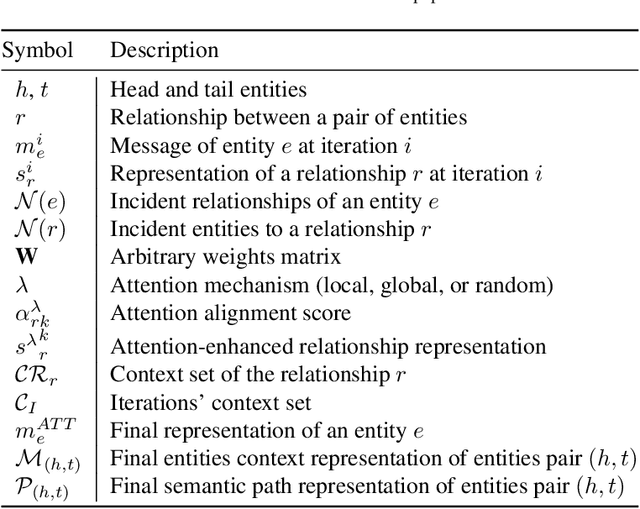
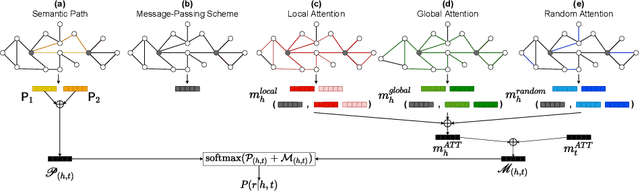

Knowledge bases, and their representations in the form of knowledge graphs (KGs), are naturally incomplete. Since scientific and industrial applications have extensively adopted them, there is a high demand for solutions that complete their information. Several recent works tackle this challenge by learning embeddings for entities and relations, then employing them to predict new relations among the entities. Despite their aggrandizement, most of those methods focus only on the local neighbors of a relation to learn the embeddings. As a result, they may fail to capture the KGs' context information by neglecting long-term dependencies and the propagation of entities' semantics. In this manuscript, we propose {\AE}MP (Attention-based Embeddings from Multiple Patterns), a novel model for learning contextualized representations by: (i) acquiring entities' context information through an attention-enhanced message-passing scheme, which captures the entities' local semantics while focusing on different aspects of their neighborhood; and (ii) capturing the semantic context, by leveraging the paths and their relationships between entities. Our empirical findings draw insights into how attention mechanisms can improve entities' context representation and how combining entities and semantic path contexts improves the general representation of entities and the relation predictions. Experimental results on several large and small knowledge graph benchmarks show that {\AE}MP either outperforms or competes with state-of-the-art relation prediction methods.
Sentiment analysis in tweets: an assessment study from classical to modern text representation models
May 29, 2021
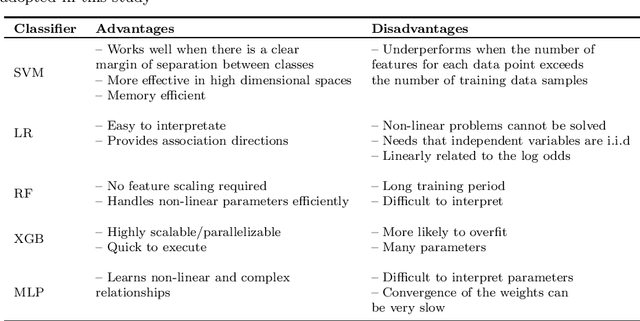


With the growth of social medias, such as Twitter, plenty of user-generated data emerge daily. The short texts published on Twitter -- the tweets -- have earned significant attention as a rich source of information to guide many decision-making processes. However, their inherent characteristics, such as the informal, and noisy linguistic style, remain challenging to many natural language processing (NLP) tasks, including sentiment analysis. Sentiment classification is tackled mainly by machine learning-based classifiers. The literature has adopted word representations from distinct natures to transform tweets to vector-based inputs to feed sentiment classifiers. The representations come from simple count-based methods, such as bag-of-words, to more sophisticated ones, such as BERTweet, built upon the trendy BERT architecture. Nevertheless, most studies mainly focus on evaluating those models using only a small number of datasets. Despite the progress made in recent years in language modelling, there is still a gap regarding a robust evaluation of induced embeddings applied to sentiment analysis on tweets. Furthermore, while fine-tuning the model from downstream tasks is prominent nowadays, less attention has been given to adjustments based on the specific linguistic style of the data. In this context, this study fulfils an assessment of existing language models in distinguishing the sentiment expressed in tweets by using a rich collection of 22 datasets from distinct domains and five classification algorithms. The evaluation includes static and contextualized representations. Contexts are assembled from Transformer-based autoencoder models that are also fine-tuned based on the masked language model task, using a plethora of strategies.
See and Read: Detecting Depression Symptoms in Higher Education Students Using Multimodal Social Media Data
Dec 03, 2019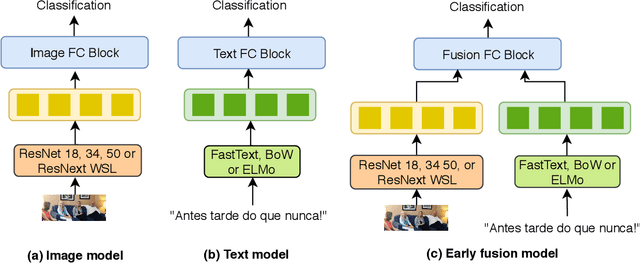
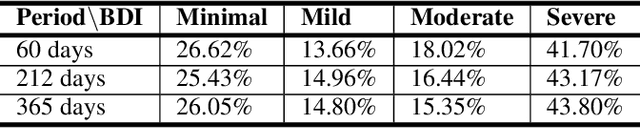

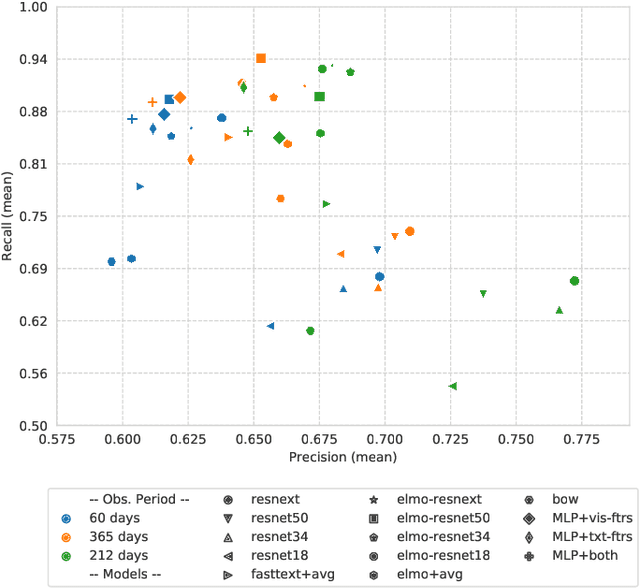
Mental disorders such as depression and anxiety have been increasing at alarming rates in the worldwide population. Notably, the major depressive disorder has become a common problem among higher education students, aggravated, and maybe even occasioned, by the academic pressures they must face. While the reasons for this alarming situation remain unclear (although widely investigated), the student already facing this problem must receive treatment. To that, it is first necessary to screen the symptoms. The traditional way for that is relying on clinical consultations or answering questionnaires. However, nowadays, the data shared at social media is a ubiquitous source that can be used to detect the depression symptoms even when the student is not able to afford or search for professional care. Previous works have already relied on social media data to detect depression on the general population, usually focusing on either posted images or texts or relying on metadata. In this work, we focus on detecting the severity of the depression symptoms in higher education students, by comparing deep learning to feature engineering models induced from both the pictures and their captions posted on Instagram. The experimental results show that students presenting a BDI score higher than 20 can be detected with 0.92 of recall and 0.69 of precision in the best case, reached by a fusion model. Our findings show a potential of help on further investigation of depression, by bringing students at-risk to light, to guide them to access adequate treatment.