 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaRetarget: Dynamically-Feasible Retargeting using Sampling-Based Trajectory Optimization
Feb 06, 2026In this paper, we introduce DynaRetarget, a complete pipeline for retargeting human motions to humanoid control policies. The core component of DynaRetarget is a novel Sampling-Based Trajectory Optimization (SBTO) framework that refines imperfect kinematic trajectories into dynamically feasible motions. SBTO incrementally advances the optimization horizon, enabling optimization over the entire trajectory for long-horizon tasks. We validate DynaRetarget by successfully retargeting hundreds of humanoid-object demonstrations and achieving higher success rates than the state of the art. The framework also generalizes across varying object properties, such as mass, size, and geometry, using the same tracking objective. This ability to robustly retarget diverse demonstrations opens the door to generating large-scale synthetic datasets of humanoid loco-manipulation trajectories, addressing a major bottleneck in real-world data collection.
Feature Aggregation in Zero-Shot Cross-Lingual Transfer Using Multilingual BERT
May 17, 2022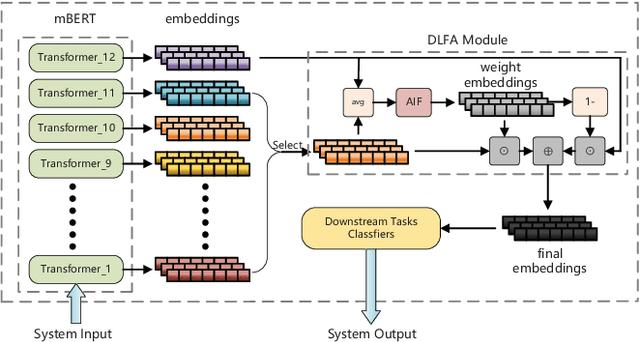
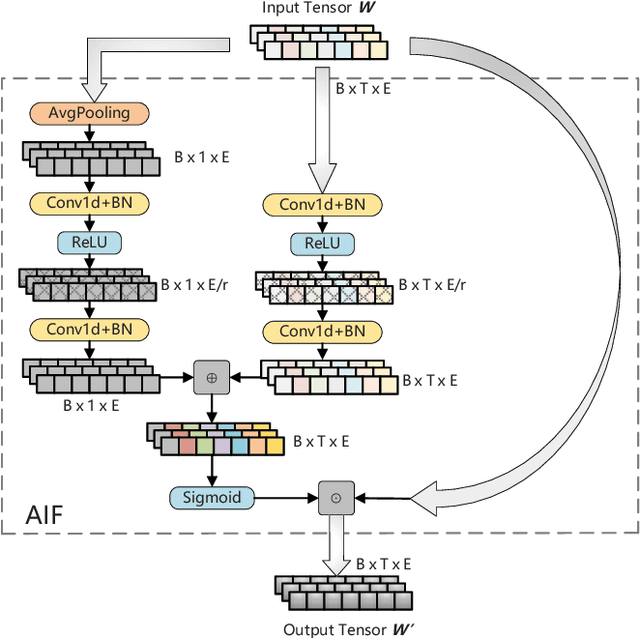
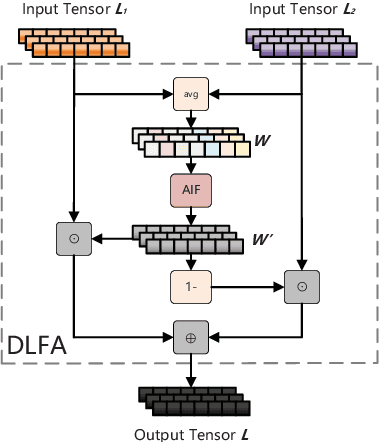
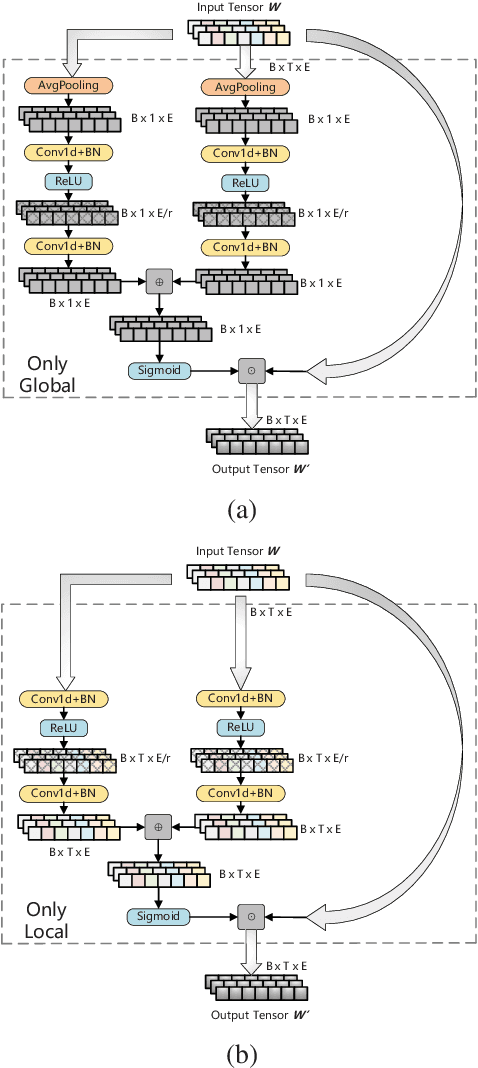
Multilingual BERT (mBERT), a language model pre-trained on large multilingual corpora, has impressive zero-shot cross-lingual transfer capabilities and performs surprisingly well on zero-shot POS tagging and Named Entity Recognition (NER), as well as on cross-lingual model transfer. At present, the mainstream methods to solve the cross-lingual downstream tasks are always using the last transformer layer's output of mBERT as the representation of linguistic information. In this work, we explore the complementary property of lower layers to the last transformer layer of mBERT. A feature aggregation module based on an attention mechanism is proposed to fuse the information contained in different layers of mBERT. The experiments are conducted on four zero-shot cross-lingual transfer datasets, and the proposed method obtains performance improvements on key multilingual benchmark tasks XNLI (+1.5 %), PAWS-X (+2.4 %), NER (+1.2 F1), and POS (+1.5 F1). Through the analysis of the experimental results, we prove that the layers before the last layer of mBERT can provide extra useful information for cross-lingual downstream tasks and explore the interpretability of mBERT empirically.
Synonym Knowledge Enhanced Reader for Chinese Idiom Reading Comprehension
Nov 09, 2020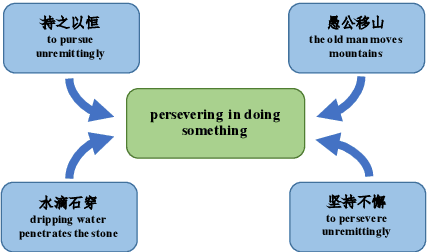

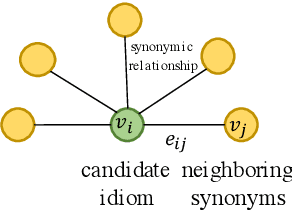
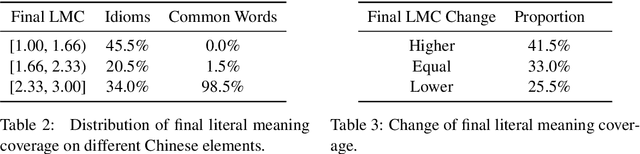
Machine reading comprehension (MRC) is the task that asks a machine to answer questions based on a given context. For Chinese MRC, due to the non-literal and non-compositional semantic characteristics, Chinese idioms pose unique challenges for machines to understand. Previous studies tend to treat idioms separately without fully exploiting the relationship among them. In this paper, we first define the concept of literal meaning coverage to measure the consistency between semantics and literal meanings for Chinese idioms. With the definition, we prove that the literal meanings of many idioms are far from their semantics, and we also verify that the synonymic relationship can mitigate this inconsistency, which would be beneficial for idiom comprehension. Furthermore, to fully utilize the synonymic relationship, we propose the synonym knowledge enhanced reader. Specifically, for each idiom, we first construct a synonym graph according to the annotations from a high-quality synonym dictionary or the cosine similarity between the pre-trained idiom embeddings and then incorporate the graph attention network and gate mechanism to encode the graph. Experimental results on ChID, a large-scale Chinese idiom reading comprehension dataset, show that our model achieves state-of-the-art performance.
R3: A Reading Comprehension Benchmark Requiring Reasoning Processes
Apr 02, 2020
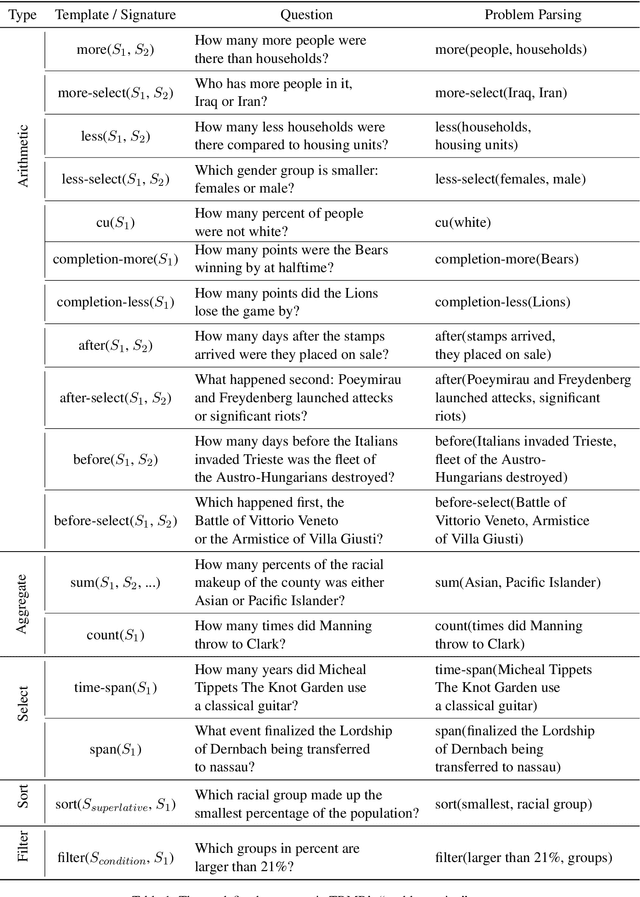
Existing question answering systems can only predict answers without explicit reasoning processes, which hinder their explainability and make us overestimate their ability of understanding and reasoning over natural language. In this work, we propose a novel task of reading comprehension, in which a model is required to provide final answers and reasoning processes. To this end, we introduce a formalism for reasoning over unstructured text, namely Text Reasoning Meaning Representation (TRMR). TRMR consists of three phrases, which is expressive enough to characterize the reasoning process to answer reading comprehension questions. We develop an annotation platform to facilitate TRMR's annotation, and release the R3 dataset, a \textbf{R}eading comprehension benchmark \textbf{R}equiring \textbf{R}easoning processes. R3 contains over 60K pairs of question-answer pairs and their TRMRs. Our dataset is available at: \url{http://anonymous}.