 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structured Review of Literature on Uncertainty in Machine Learning & Deep Learning
Jun 01, 2024
The adaptation and use of Machine Learning (ML) in our daily lives has led to concerns in lack of transparency, privacy, reliability, among others. As a result, we are seeing research in niche areas such as interpretability, causality, bias and fairness, and reliability. In this survey paper, we focus on a critical concern for adaptation of ML in risk-sensitive applications, namely understanding and quantifying uncertainty. Our paper approaches this topic in a structured way, providing a review of the literature in the various facets that uncertainty is enveloped in the ML process. We begin by defining uncertainty and its categories (e.g., aleatoric and epistemic), understanding sources of uncertainty (e.g., data and model), and how uncertainty can be assessed in terms of uncertainty quantification techniques (Ensembles, Bayesian Neural Networks, etc.). As part of our assessment and understanding of uncertainty in the ML realm, we cover metrics for uncertainty quantification for a single sample, dataset, and metrics for accuracy of the uncertainty estimation itself. This is followed by discussions on calibration (model and uncertainty), and decision making under uncertainty. Thus, we provide a more complete treatment of uncertainty: from the sources of uncertainty to the decision-making process. We have focused the review of uncertainty quantification methods on Deep Learning (DL), while providing the necessary background for uncertainty discussion within ML in general. Key contributions in this review are broadening the scope of uncertainty discussion, as well as an updated review of uncertainty quantification methods in DL.
Factors Shaping Financial Success: A Deep Dive into Influencing Variables
May 13, 2024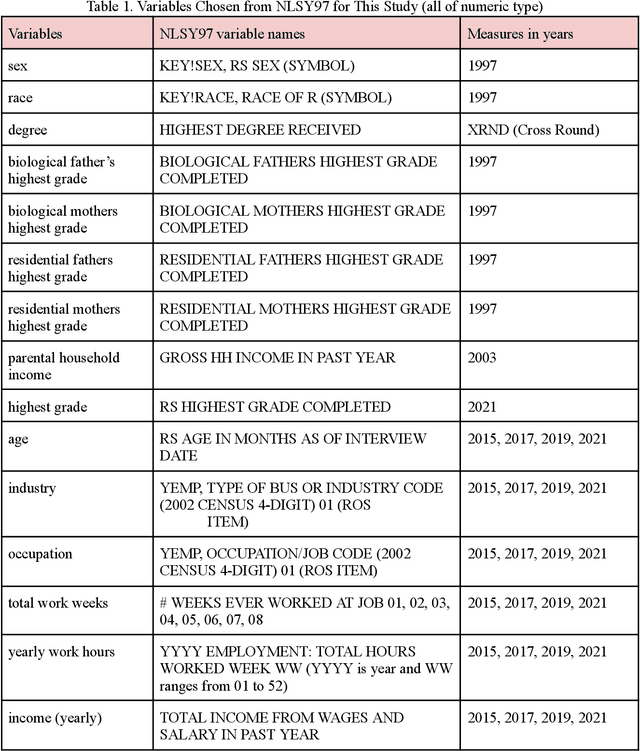
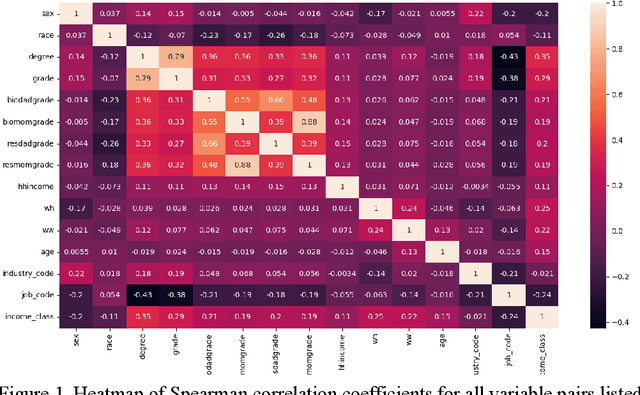
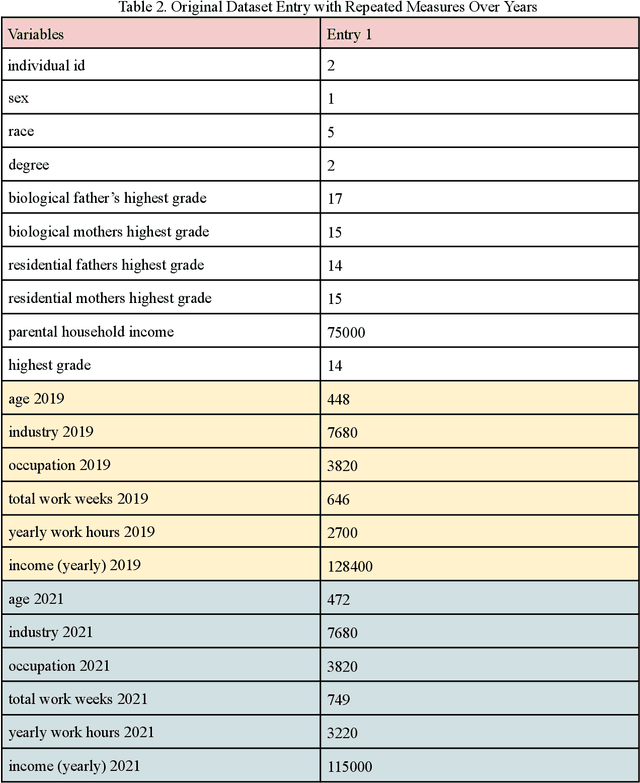
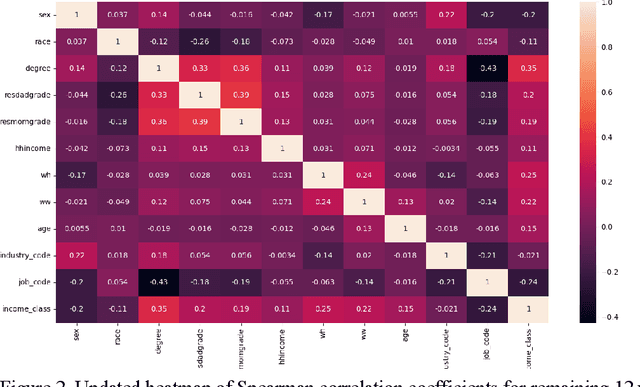
This paper explores various socioeconomic factors that contribute to individual financial success using machine learning algorithms and approaches. Financial success, a critical aspect of all individual's well-being, is a complex concept influenced by a plethora of different factors. This study aims to understand the true determinants of financial success. It examines the survey data from the National Longitudinal Survey of Youth 1997 by the Bureau of Labor Statistics [1], consisting of a sample of 8,984 individuals's longitudinal data over years. The dataset comprises income variables and a large set of socioeconomic variables of individuals. An in-depth analysis demonstrates the effectiveness of machine learning algorithms in financial success research, highlights the potential of leveraging longitudinal data to enhance prediction accuracy, and provides valuable insights into how various socioeconomic factors influence financial success. The findings underscore the significant influence of highest education degree, occupation and gender as the top three determinants of individual income among socioeconomic factors examined. Yearly working hours, age and work tenure emerge as three secondary influencing factors, and all other factors including parental household income, industry, parents' highest grade and others are identified as tertiary factors. These insights allow researchers to better understand the complex nature of financial success and enable policymakers to grasp the underlying dynamics shaping aspirations, decision-making, and the broader socio-economic fabric of society. This comprehension is crucial for fostering financial success among individuals and advancing broader societal well-being.
Transformer models classify random numbers
May 06, 2024



Random numbers are incredibly important in a variety of fields, and the need for their validation remains important. A Quantum Random Number Generator (QRNG) can theoretically generate truly random numbers however this does not remove the need to thoroughly test their randomness. Generally, the task of validating random numbers has been delegated to different statistical tests such as the tests from the NIST Statistical Test Suite (STS) which are often slow and only perform one task at a time. Our work presents a deep learning model that utilizes the transformer architecture to encode some of the tests from the NIST STS in a single model that also runs much faster. This model performs multi-label classification on these tests and outputs the probability of passing each statistical test that it encodes. We perform a thorough hyper-parameter optimization to converge on the best possible model and as a result, achieve a high degree of accuracy with a sample f1 score of above 0.9.
ECG Heartbeat classification using deep transfer learning with Convolutional Neural Network and STFT technique
Jul 05, 2022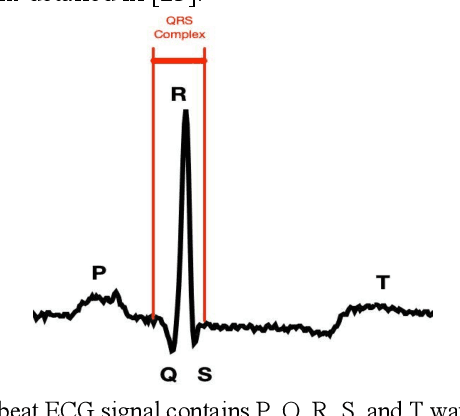
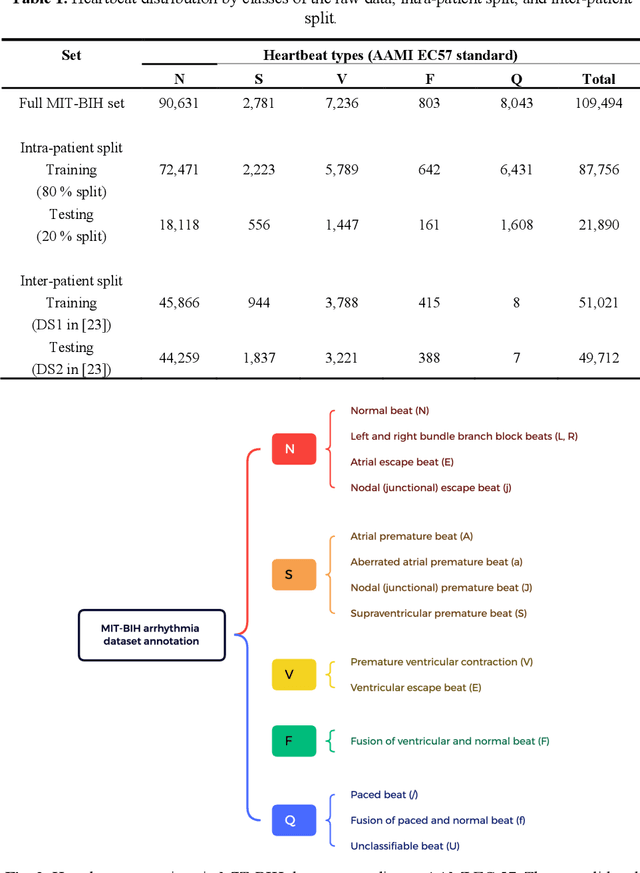
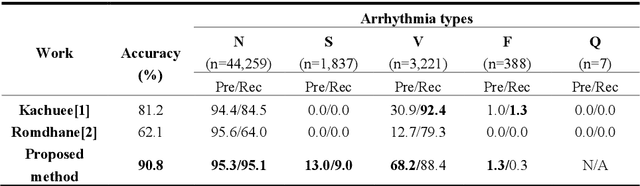
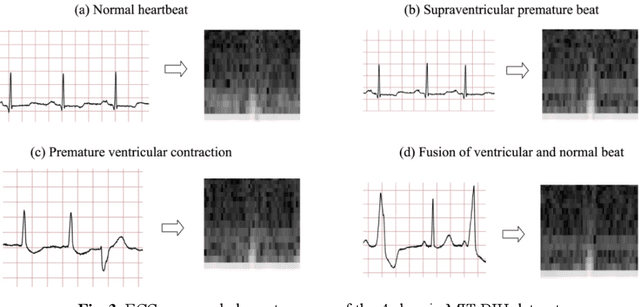
Electrocardiogram (ECG) is a simple non-invasive measure to identify heart-related issues such as irregular heartbeats known as arrhythmias. While artificial intelligence and machine learning is being utilized in a wide range of healthcare related applications and datasets, many arrhythmia classifiers using deep learning methods have been proposed in recent years. However, sizes of the available datasets from which to build and assess machine learning models is often very small and the lack of well-annotated public ECG datasets is evident. In this paper, we propose a deep transfer learning framework that is aimed to perform classification on a small size training dataset. The proposed method is to fine-tune a general-purpose image classifier ResNet-18 with MIT-BIH arrhythmia dataset in accordance with the AAMI EC57 standard. This paper further investigates many existing deep learning models that have failed to avoid data leakage against AAMI recommendations. We compare how different data split methods impact the model performance. This comparison study implies that future work in arrhythmia classification should follow the AAMI EC57 standard when using any including MIT-BIH arrhythmia dataset.
Data generation using simulation technology to improve perception mechanism of autonomous vehicles
Jul 01, 2022



Recent advancements in computer graphics technology allow more realistic ren-dering of car driving environments. They have enabled self-driving car simulators such as DeepGTA-V and CARLA (Car Learning to Act) to generate large amounts of synthetic data that can complement the existing real-world dataset in training autonomous car perception. Furthermore, since self-driving car simulators allow full control of the environment, they can generate dangerous driving scenarios that the real-world dataset lacks such as bad weather and accident scenarios. In this paper, we will demonstrate the effectiveness of combining data gathered from the real world with data generated in the simulated world to train perception systems on object detection and localization task. We will also propose a multi-level deep learning perception framework that aims to emulate a human learning experience in which a series of tasks from the simple to more difficult ones are learned in a certain domain. The autonomous car perceptron can learn from easy-to-drive scenarios to more challenging ones customized by simulation software.
Range of Motion Sensors for Monitoring Recovery of Total Knee Arthroplasty
Jul 01, 2022
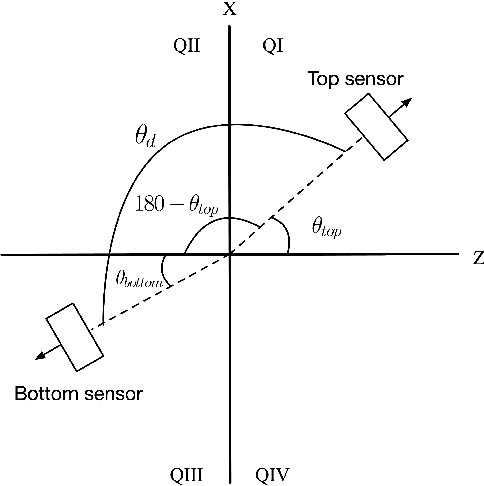

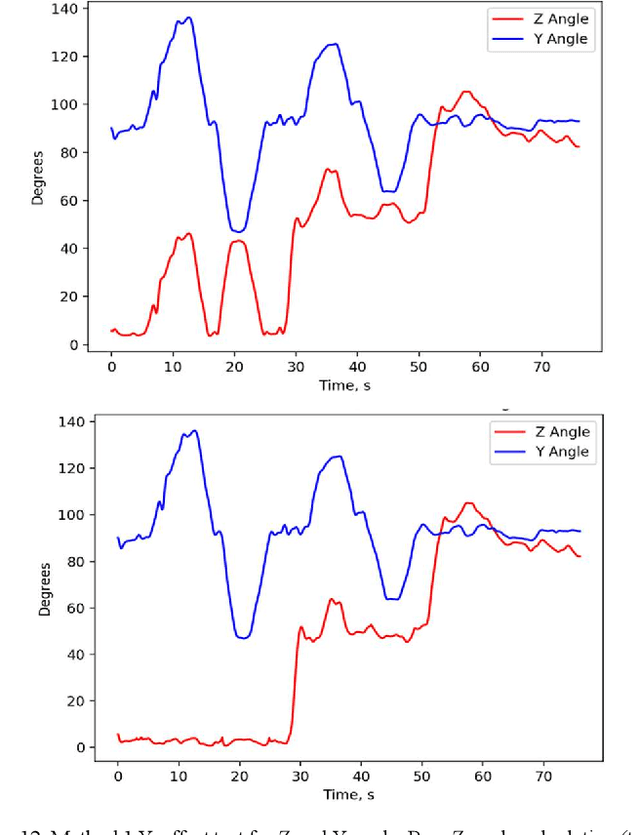
A low-cost, accurate device to measure and record knee range of motion (ROM) is of the essential need to improve confidence in at-home rehabilitation. It is to reduce hospital stay duration and overall medical cost after Total Knee Arthroplasty (TKA) procedures. The shift in Medicare funding from pay-as-you-go to the Bundled Payments for Care Improvement (BPCI) has created a push towards at-home care over extended hospital stays. It has heavily affected TKA patients, who typically undergo physical therapy at the clinic after the procedure to ensure full recovery of ROM. In this paper, we use accelerometers to create a ROM sensor that can be integrated into the post-operative surgical dressing, so that the cost of the sensors can be included in the bundled payments. In this paper, we demonstrate the efficacy of our method in comparison to the baseline computer vision method. Our results suggest that calculating angular displacement from accelerometer sensors demonstrates accurate ROM recordings under both stationary and walking conditions. The device would keep track of angle measurements and alert the patient when certain angle thresholds have been crossed, allowing patients to recover safely at home instead of going to multiple physical therapy sessions. The affordability of our sensor makes it more accessible to patients in need.
An introduction to causal reasoning in health analytics
May 18, 2021
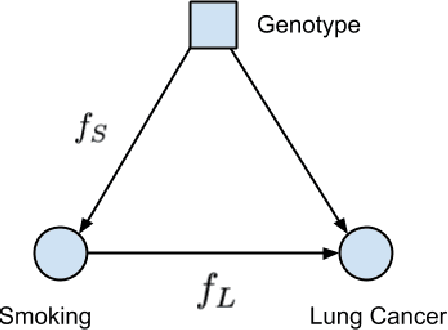
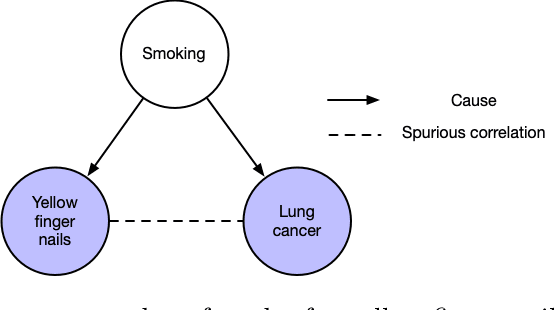
A data science task can be deemed as making sense of the data and/or testing a hypothesis about it. The conclusions inferred from data can greatly guide us to make informative decisions. Big data has enabled us to carry out countless prediction tasks in conjunction with machine learning, such as identifying high risk patients suffering from a certain disease and taking preventable measures. However, healthcare practitioners are not content with mere predictions - they are also interested in the cause-effect relation between input features and clinical outcomes. Understanding such relations will help doctors treat patients and reduce the risk effectively. Causality is typically identified by randomized controlled trials. Often such trials are not feasible when scientists and researchers turn to observational studies and attempt to draw inferences. However, observational studies may also be affected by selection and/or confounding biases that can result in wrong causal conclusions. In this chapter, we will try to highlight some of the drawbacks that may arise in traditional machine learning and statistical approaches to analyze the observational data, particularly in the healthcare data analytics domain. We will discuss causal inference and ways to discover the cause-effect from observational studies in healthcare domain. Moreover, we will demonstrate the applications of causal inference in tackling some common machine learning issues such as missing data and model transportability. Finally, we will discuss the possibility of integrating reinforcement learning with causality as a way to counter confounding bias.
WOTBoost: Weighted Oversampling Technique in Boosting for imbalanced learning
Nov 12, 2019
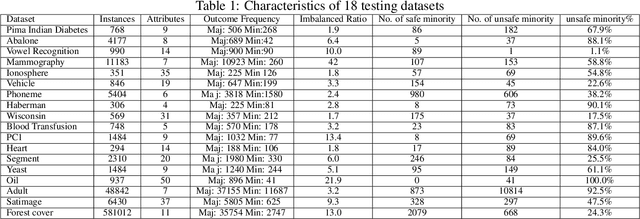
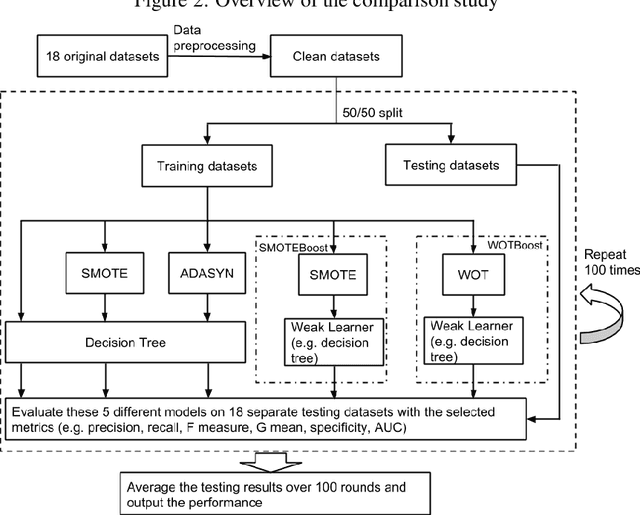
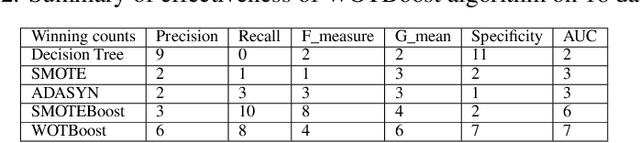
Machine learning classifiers often stumble over imbalanced datasets where classes are not equally represented. This inherent bias towards the majority class may result in low accuracy in labeling minority class. Imbalanced learning is prevalent in many real-world applications, such as medical research, network intrusion detection, and fraud detection in credit card transactions, etc. A good number of research works have been reported to tackle this challenging problem. For example, Synthetic Minority Over-sampling TEchnique (SMOTE) and ADAptive SYNthetic sampling approach (ADASYN) use oversampling techniques to balance the skewed datasets. In this paper, we propose a novel method that combines a Weighted Oversampling Technique and ensemble Boosting method (WOTBoost) to improve the classification accuracy of minority data without sacrificing the accuracy of the majority class. WOTBoost adjusts its oversampling strategy at each round of boosting to synthesize more targeted minority data samples. The adjustment is enforced using a weighted distribution. We compare WOTBoost with other four classification models (i.e., decision tree, SMOTE + decision tree, ADASYN + decision tree, SMOTEBoost) extensively on 18 public accessible imbalanced datasets. WOTBoost achieves the best G mean on 6 datasets and highest AUC score on 7 datasets.
GenSample: A Genetic Algorithm for Oversampling in Imbalanced Datasets
Oct 23, 2019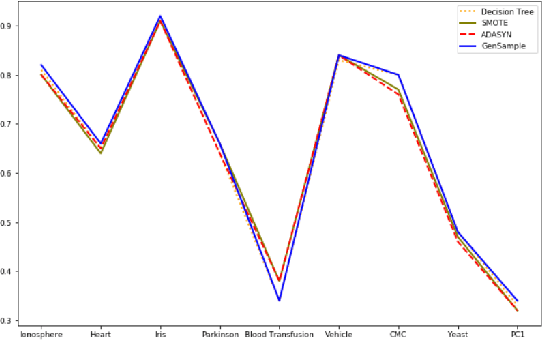
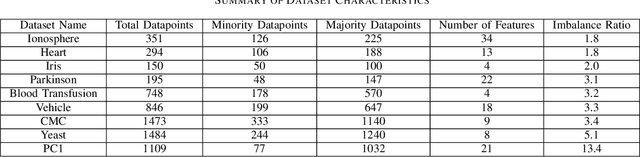
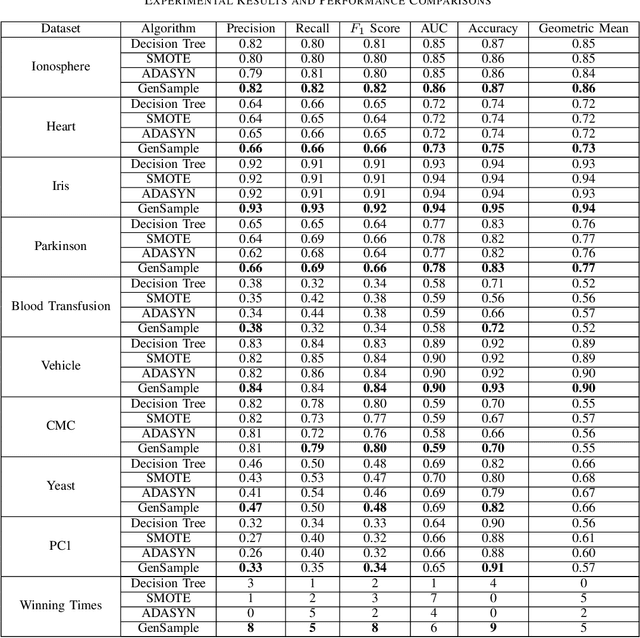
Imbalanced datasets are ubiquitous. Classification performance on imbalanced datasets is generally poor for the minority class as the classifier cannot learn decision boundaries well. However, in sensitive applications like fraud detection, medical diagnosis, and spam identification, it is extremely important to classify the minority instances correctly. In this paper, we present a novel technique based on genetic algorithms, GenSample, for oversampling the minority class in imbalanced datasets. GenSample decides the rate of oversampling a minority example by taking into account the difficulty in learning that example, along with the performance improvement achieved by oversampling it. This technique terminates the oversampling process when the performance of the classifier begins to deteriorate. Consequently, it produces synthetic data only as long as a performance boost is obtained. The algorithm was tested on 9 real-world imbalanced datasets of varying sizes and imbalance ratios. It achieved the highest F-Score on 8 out of 9 datasets, confirming its ability to better handle imbalanced data compared to other existing methodologies.
A Causal Perspective to Unbiased Conversion Rate Estimation on Data Missing Not at Random
Oct 16, 2019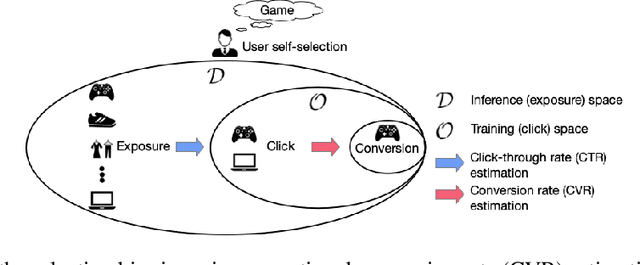
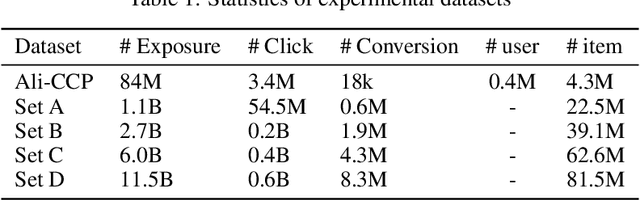
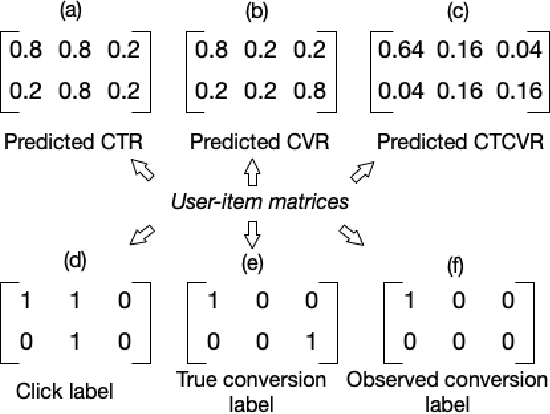
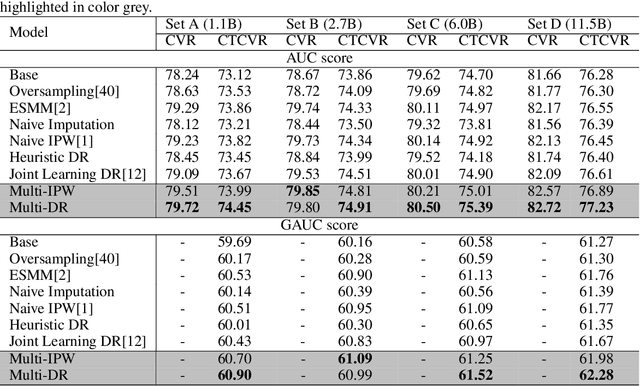
In modern e-commerce and advertising recommender systems, ongoing research works attempt to optimize conversion rate (CVR) estimation, and increase the gross merchandise volume. Even though the state-of-the-art CVR estimators adopt deep learning methods, their model performances are still subject to sample selection bias and data sparsity issues. Conversion labels of exposed items in training dataset are typically missing not at random due to selection bias. Empirically, data sparsity issue causes the performance degradation of model with large parameter space. In this paper, we proposed two causal estimators combined with multi-task learning, and aim to solve sample selection bias (SSB) and data sparsity (DS) issues in conversion rate estimation. The proposed estimators adjust for the MNAR mechanism as if they are trained on a "do dataset" where users are forced to click on all exposed items. We evaluate the causal estimators with billion data samples. Experiment results demonstrate that the proposed CVR estimators outperform other state-of-the-art CVR estimators. In addition, empirical study shows that our methods are cost-effective with large scale dataset.