 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRange of Motion Sensors for Monitoring Recovery of Total Knee Arthroplasty
Jul 01, 2022
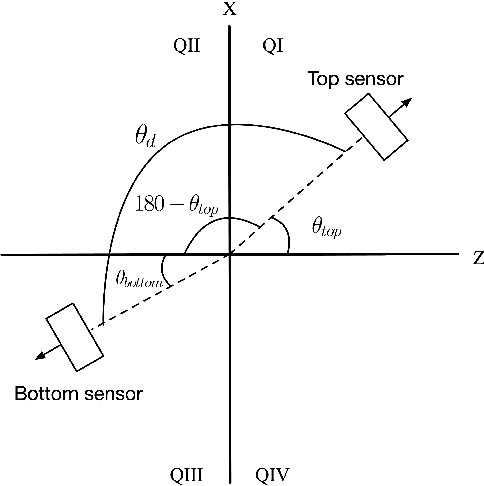

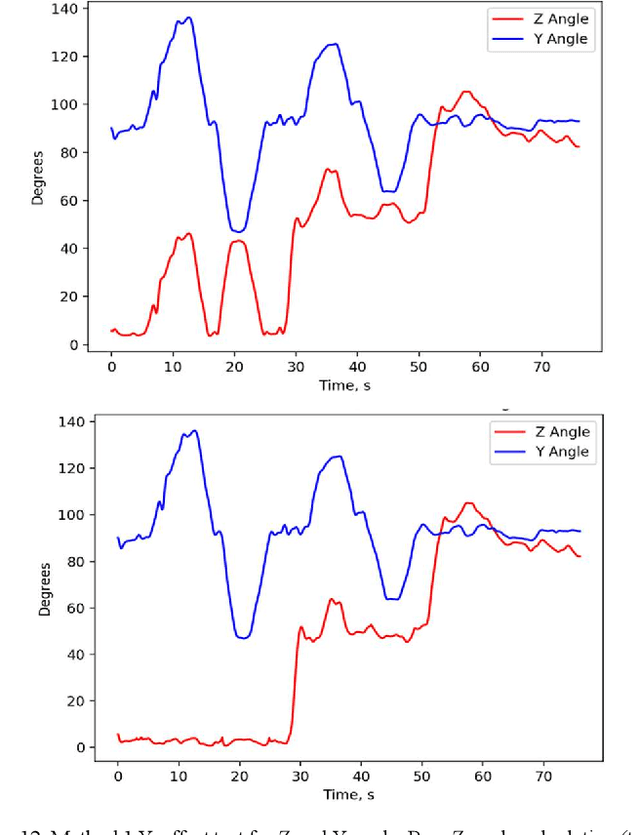
A low-cost, accurate device to measure and record knee range of motion (ROM) is of the essential need to improve confidence in at-home rehabilitation. It is to reduce hospital stay duration and overall medical cost after Total Knee Arthroplasty (TKA) procedures. The shift in Medicare funding from pay-as-you-go to the Bundled Payments for Care Improvement (BPCI) has created a push towards at-home care over extended hospital stays. It has heavily affected TKA patients, who typically undergo physical therapy at the clinic after the procedure to ensure full recovery of ROM. In this paper, we use accelerometers to create a ROM sensor that can be integrated into the post-operative surgical dressing, so that the cost of the sensors can be included in the bundled payments. In this paper, we demonstrate the efficacy of our method in comparison to the baseline computer vision method. Our results suggest that calculating angular displacement from accelerometer sensors demonstrates accurate ROM recordings under both stationary and walking conditions. The device would keep track of angle measurements and alert the patient when certain angle thresholds have been crossed, allowing patients to recover safely at home instead of going to multiple physical therapy sessions. The affordability of our sensor makes it more accessible to patients in need.
An introduction to causal reasoning in health analytics
May 18, 2021
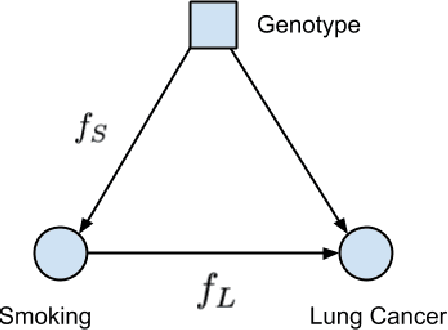
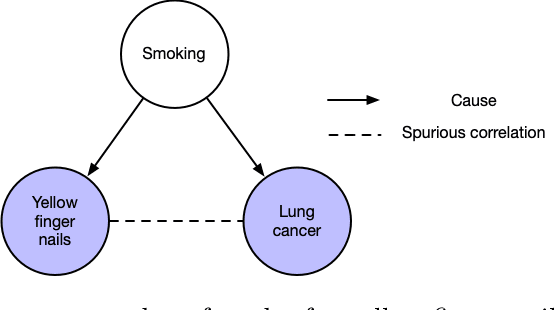
A data science task can be deemed as making sense of the data and/or testing a hypothesis about it. The conclusions inferred from data can greatly guide us to make informative decisions. Big data has enabled us to carry out countless prediction tasks in conjunction with machine learning, such as identifying high risk patients suffering from a certain disease and taking preventable measures. However, healthcare practitioners are not content with mere predictions - they are also interested in the cause-effect relation between input features and clinical outcomes. Understanding such relations will help doctors treat patients and reduce the risk effectively. Causality is typically identified by randomized controlled trials. Often such trials are not feasible when scientists and researchers turn to observational studies and attempt to draw inferences. However, observational studies may also be affected by selection and/or confounding biases that can result in wrong causal conclusions. In this chapter, we will try to highlight some of the drawbacks that may arise in traditional machine learning and statistical approaches to analyze the observational data, particularly in the healthcare data analytics domain. We will discuss causal inference and ways to discover the cause-effect from observational studies in healthcare domain. Moreover, we will demonstrate the applications of causal inference in tackling some common machine learning issues such as missing data and model transportability. Finally, we will discuss the possibility of integrating reinforcement learning with causality as a way to counter confounding bias.
WOTBoost: Weighted Oversampling Technique in Boosting for imbalanced learning
Nov 12, 2019
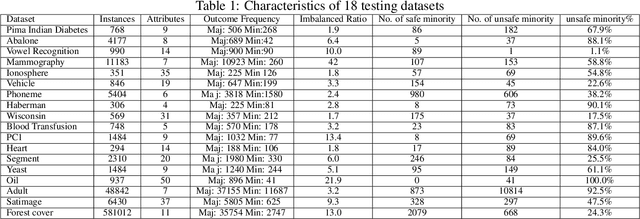
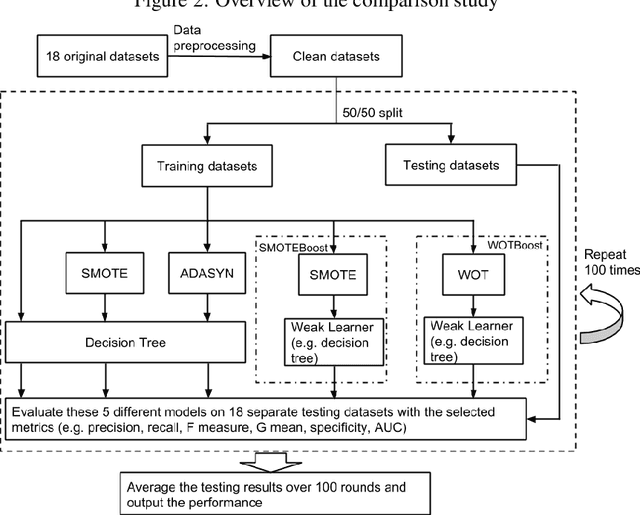
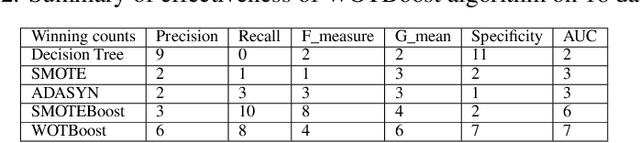
Machine learning classifiers often stumble over imbalanced datasets where classes are not equally represented. This inherent bias towards the majority class may result in low accuracy in labeling minority class. Imbalanced learning is prevalent in many real-world applications, such as medical research, network intrusion detection, and fraud detection in credit card transactions, etc. A good number of research works have been reported to tackle this challenging problem. For example, Synthetic Minority Over-sampling TEchnique (SMOTE) and ADAptive SYNthetic sampling approach (ADASYN) use oversampling techniques to balance the skewed datasets. In this paper, we propose a novel method that combines a Weighted Oversampling Technique and ensemble Boosting method (WOTBoost) to improve the classification accuracy of minority data without sacrificing the accuracy of the majority class. WOTBoost adjusts its oversampling strategy at each round of boosting to synthesize more targeted minority data samples. The adjustment is enforced using a weighted distribution. We compare WOTBoost with other four classification models (i.e., decision tree, SMOTE + decision tree, ADASYN + decision tree, SMOTEBoost) extensively on 18 public accessible imbalanced datasets. WOTBoost achieves the best G mean on 6 datasets and highest AUC score on 7 datasets.
GenSample: A Genetic Algorithm for Oversampling in Imbalanced Datasets
Oct 23, 2019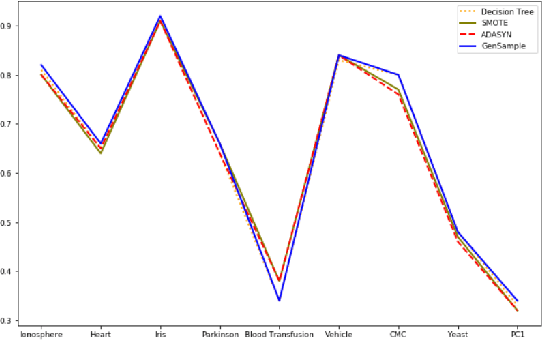
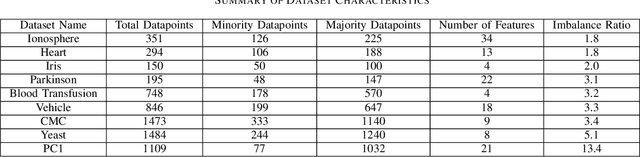
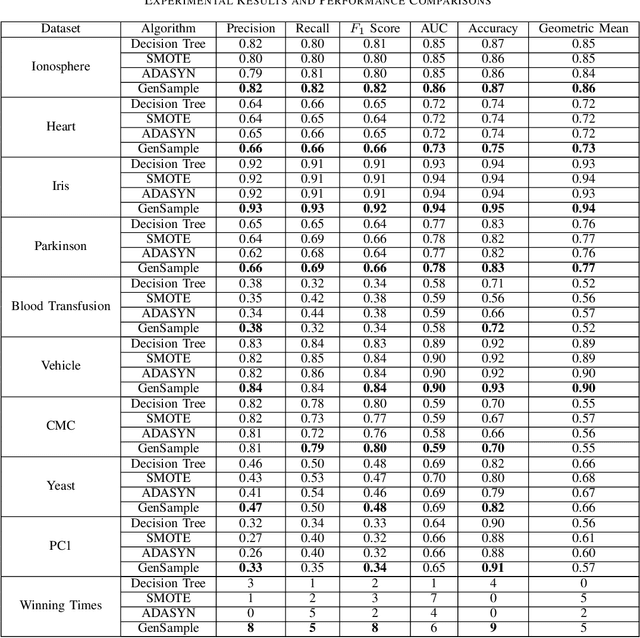
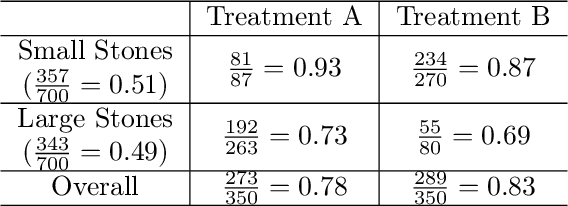
Imbalanced datasets are ubiquitous. Classification performance on imbalanced datasets is generally poor for the minority class as the classifier cannot learn decision boundaries well. However, in sensitive applications like fraud detection, medical diagnosis, and spam identification, it is extremely important to classify the minority instances correctly. In this paper, we present a novel technique based on genetic algorithms, GenSample, for oversampling the minority class in imbalanced datasets. GenSample decides the rate of oversampling a minority example by taking into account the difficulty in learning that example, along with the performance improvement achieved by oversampling it. This technique terminates the oversampling process when the performance of the classifier begins to deteriorate. Consequently, it produces synthetic data only as long as a performance boost is obtained. The algorithm was tested on 9 real-world imbalanced datasets of varying sizes and imbalance ratios. It achieved the highest F-Score on 8 out of 9 datasets, confirming its ability to better handle imbalanced data compared to other existing methodologies.