 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenSample: A Genetic Algorithm for Oversampling in Imbalanced Datasets
Oct 23, 2019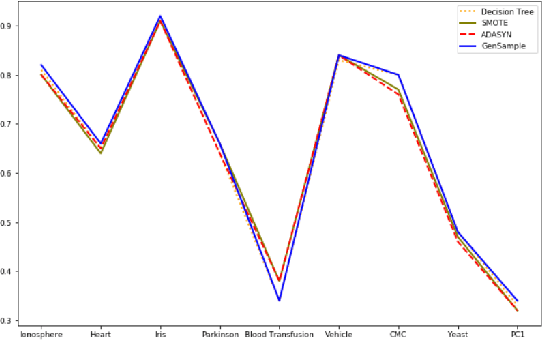
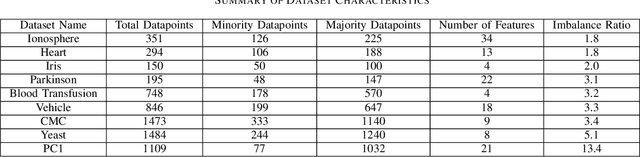
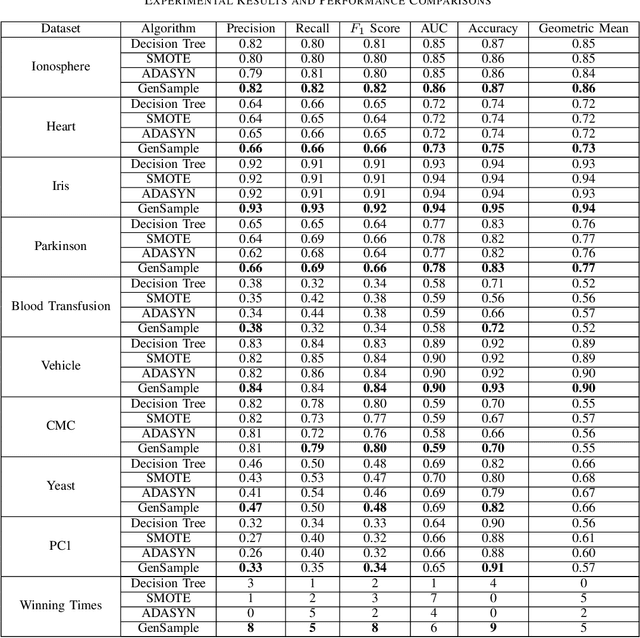
Imbalanced datasets are ubiquitous. Classification performance on imbalanced datasets is generally poor for the minority class as the classifier cannot learn decision boundaries well. However, in sensitive applications like fraud detection, medical diagnosis, and spam identification, it is extremely important to classify the minority instances correctly. In this paper, we present a novel technique based on genetic algorithms, GenSample, for oversampling the minority class in imbalanced datasets. GenSample decides the rate of oversampling a minority example by taking into account the difficulty in learning that example, along with the performance improvement achieved by oversampling it. This technique terminates the oversampling process when the performance of the classifier begins to deteriorate. Consequently, it produces synthetic data only as long as a performance boost is obtained. The algorithm was tested on 9 real-world imbalanced datasets of varying sizes and imbalance ratios. It achieved the highest F-Score on 8 out of 9 datasets, confirming its ability to better handle imbalanced data compared to other existing methodologies.