 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn introduction to causal reasoning in health analytics
Paper and Code
May 18, 2021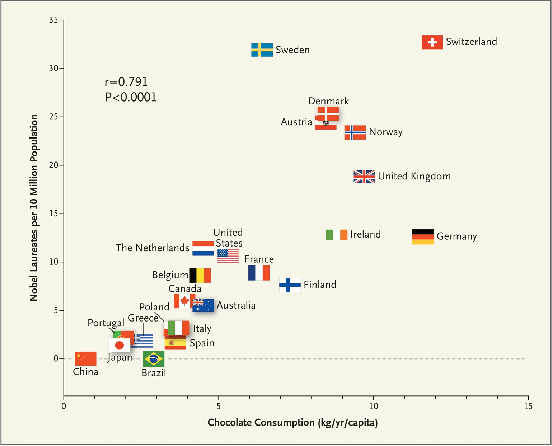
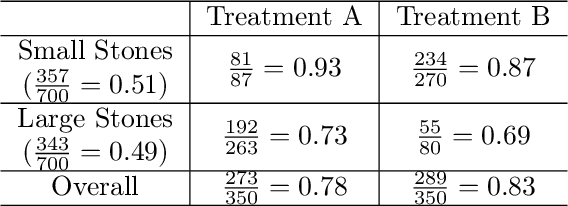
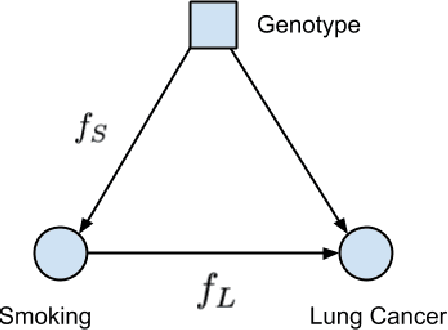
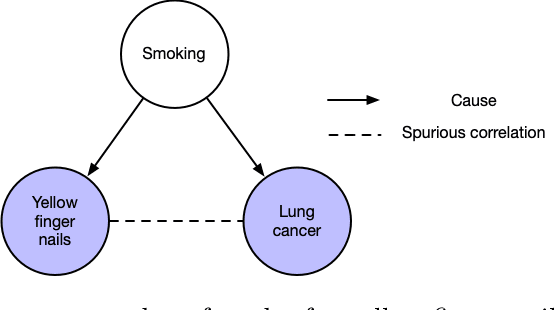
A data science task can be deemed as making sense of the data and/or testing a hypothesis about it. The conclusions inferred from data can greatly guide us to make informative decisions. Big data has enabled us to carry out countless prediction tasks in conjunction with machine learning, such as identifying high risk patients suffering from a certain disease and taking preventable measures. However, healthcare practitioners are not content with mere predictions - they are also interested in the cause-effect relation between input features and clinical outcomes. Understanding such relations will help doctors treat patients and reduce the risk effectively. Causality is typically identified by randomized controlled trials. Often such trials are not feasible when scientists and researchers turn to observational studies and attempt to draw inferences. However, observational studies may also be affected by selection and/or confounding biases that can result in wrong causal conclusions. In this chapter, we will try to highlight some of the drawbacks that may arise in traditional machine learning and statistical approaches to analyze the observational data, particularly in the healthcare data analytics domain. We will discuss causal inference and ways to discover the cause-effect from observational studies in healthcare domain. Moreover, we will demonstrate the applications of causal inference in tackling some common machine learning issues such as missing data and model transportability. Finally, we will discuss the possibility of integrating reinforcement learning with causality as a way to counter confounding bias.