 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
Apr 14, 2025Automating the synthesis of coordinated bimanual piano performances poses significant challenges, particularly in capturing the intricate choreography between the hands while preserving their distinct kinematic signatures. In this paper, we propose a dual-stream neural framework designed to generate synchronized hand gestures for piano playing from audio input, addressing the critical challenge of modeling both hand independence and coordination. Our framework introduces two key innovations: (i) a decoupled diffusion-based generation framework that independently models each hand's motion via dual-noise initialization, sampling distinct latent noise for each while leveraging a shared positional condition, and (ii) a Hand-Coordinated Asymmetric Attention (HCAA) mechanism suppresses symmetric (common-mode) noise to highlight asymmetric hand-specific features, while adaptively enhancing inter-hand coordination during denoising. The system operates hierarchically: it first predicts 3D hand positions from audio features and then generates joint angles through position-aware diffusion models, where parallel denoising streams interact via HCAA. Comprehensive evaluations demonstrate that our framework outperforms existing state-of-the-art methods across multiple metrics.
Densely Connected Parameter-Efficient Tuning for Referring Image Segmentation
Jan 15, 2025In the domain of computer vision, Parameter-Efficient Tuning (PET) is increasingly replacing the traditional paradigm of pre-training followed by full fine-tuning. PET is particularly favored for its effectiveness in large foundation models, as it streamlines transfer learning costs and optimizes hardware utilization. However, the current PET methods are mainly designed for single-modal optimization. While some pioneering studies have undertaken preliminary explorations, they still remain at the level of aligned encoders (e.g., CLIP) and lack exploration of misaligned encoders. These methods show sub-optimal performance with misaligned encoders, as they fail to effectively align the multimodal features during fine-tuning. In this paper, we introduce DETRIS, a parameter-efficient tuning framework designed to enhance low-rank visual feature propagation by establishing dense interconnections between each layer and all preceding layers, which enables effective cross-modal feature interaction and adaptation to misaligned encoders. We also suggest using text adapters to improve textual features. Our simple yet efficient approach greatly surpasses state-of-the-art methods with 0.9% to 1.8% backbone parameter updates, evaluated on challenging benchmarks. Our project is available at \url{https://github.com/jiaqihuang01/DETRIS}.
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Nov 27, 2024



Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
REPARO: Compositional 3D Assets Generation with Differentiable 3D Layout Alignment
May 28, 2024



Traditional image-to-3D models often struggle with scenes containing multiple objects due to biases and occlusion complexities. To address this challenge, we present REPARO, a novel approach for compositional 3D asset generation from single images. REPARO employs a two-step process: first, it extracts individual objects from the scene and reconstructs their 3D meshes using off-the-shelf image-to-3D models; then, it optimizes the layout of these meshes through differentiable rendering techniques, ensuring coherent scene composition. By integrating optimal transport-based long-range appearance loss term and high-level semantic loss term in the differentiable rendering, REPARO can effectively recover the layout of 3D assets. The proposed method can significantly enhance object independence, detail accuracy, and overall scene coherence. Extensive evaluation of multi-object scenes demonstrates that our REPARO offers a comprehensive approach to address the complexities of multi-object 3D scene generation from single images.
MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
Mar 14, 2024


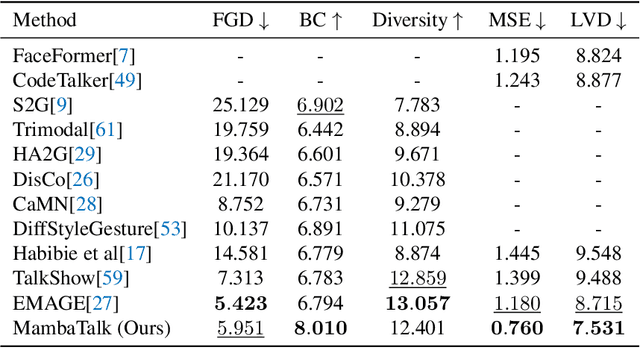
Gesture synthesis is a vital realm of human-computer interaction, with wide-ranging applications across various fields like film, robotics, and virtual reality. Recent advancements have utilized the diffusion model and attention mechanisms to improve gesture synthesis. However, due to the high computational complexity of these techniques, generating long and diverse sequences with low latency remains a challenge. We explore the potential of state space models (SSMs) to address the challenge, implementing a two-stage modeling strategy with discrete motion priors to enhance the quality of gestures. Leveraging the foundational Mamba block, we introduce MambaTalk, enhancing gesture diversity and rhythm through multimodal integration. Extensive experiments demonstrate that our method matches or exceeds the performance of state-of-the-art models.
BATON: Aligning Text-to-Audio Model with Human Preference Feedback
Feb 01, 2024



With the development of AI-Generated Content (AIGC), text-to-audio models are gaining widespread attention. However, it is challenging for these models to generate audio aligned with human preference due to the inherent information density of natural language and limited model understanding ability. To alleviate this issue, we formulate the BATON, a framework designed to enhance the alignment between generated audio and text prompt using human preference feedback. Our BATON comprises three key stages: Firstly, we curated a dataset containing both prompts and the corresponding generated audio, which was then annotated based on human feedback. Secondly, we introduced a reward model using the constructed dataset, which can mimic human preference by assigning rewards to input text-audio pairs. Finally, we employed the reward model to fine-tune an off-the-shelf text-to-audio model. The experiment results demonstrate that our BATON can significantly improve the generation quality of the original text-to-audio models, concerning audio integrity, temporal relationship, and alignment with human preference.
Consistent123: One Image to Highly Consistent 3D Asset Using Case-Aware Diffusion Priors
Sep 29, 2023Reconstructing 3D objects from a single image guided by pretrained diffusion models has demonstrated promising outcomes. However, due to utilizing the case-agnostic rigid strategy, their generalization ability to arbitrary cases and the 3D consistency of reconstruction are still poor. In this work, we propose Consistent123, a case-aware two-stage method for highly consistent 3D asset reconstruction from one image with both 2D and 3D diffusion priors. In the first stage, Consistent123 utilizes only 3D structural priors for sufficient geometry exploitation, with a CLIP-based case-aware adaptive detection mechanism embedded within this process. In the second stage, 2D texture priors are introduced and progressively take on a dominant guiding role, delicately sculpting the details of the 3D model. Consistent123 aligns more closely with the evolving trends in guidance requirements, adaptively providing adequate 3D geometric initialization and suitable 2D texture refinement for different objects. Consistent123 can obtain highly 3D-consistent reconstruction and exhibits strong generalization ability across various objects. Qualitative and quantitative experiments show that our method significantly outperforms state-of-the-art image-to-3D methods. See https://Consistent123.github.io for a more comprehensive exploration of our generated 3D assets.
SSGD: A smartphone screen glass dataset for defect detection
Mar 12, 2023



Interactive devices with touch screen have become commonly used in various aspects of daily life, which raises the demand for high production quality of touch screen glass. While it is desirable to develop effective defect detection technologies to optimize the automatic touch screen production lines, the development of these technologies suffers from the lack of publicly available datasets. To address this issue, we in this paper propose a dedicated touch screen glass defect dataset which includes seven types of defects and consists of 2504 images captured in various scenarios.All data are captured with professional acquisition equipment on the fixed workstation. Additionally, we benchmark the CNN- and Transformer-based object detection frameworks on the proposed dataset to demonstrate the challenges of defect detection on high-resolution images. Dataset and related code will be available at https://github.com/Yangr116/SSGDataset.