 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWATCH: World-aware Allied Trajectory and pose reconstruction for Camera and Human
Sep 04, 2025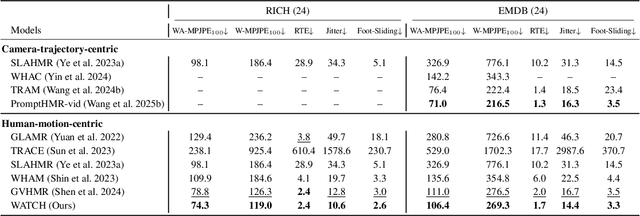
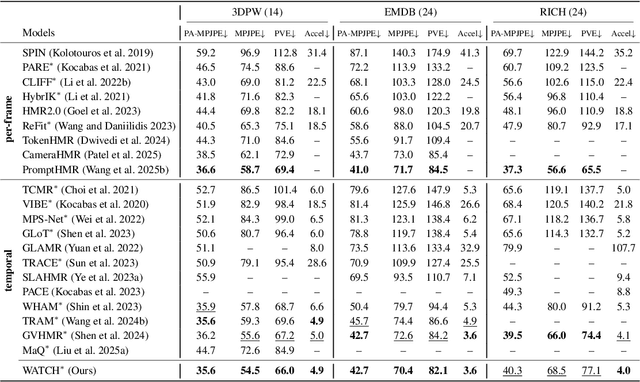

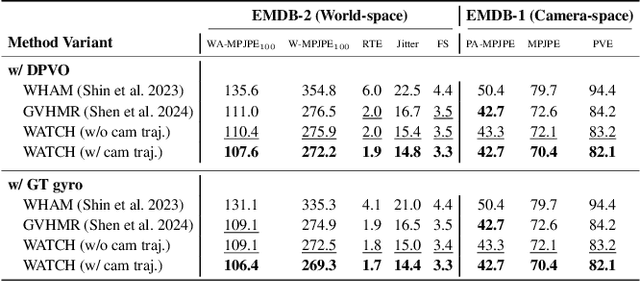
Global human motion reconstruction from in-the-wild monocular videos is increasingly demanded across VR, graphics, and robotics applications, yet requires accurate mapping of human poses from camera to world coordinates-a task challenged by depth ambiguity, motion ambiguity, and the entanglement between camera and human movements. While human-motion-centric approaches excel in preserving motion details and physical plausibility, they suffer from two critical limitations: insufficient exploitation of camera orientation information and ineffective integration of camera translation cues. We present WATCH (World-aware Allied Trajectory and pose reconstruction for Camera and Human), a unified framework addressing both challenges. Our approach introduces an analytical heading angle decomposition technique that offers superior efficiency and extensibility compared to existing geometric methods. Additionally, we design a camera trajectory integration mechanism inspired by world models, providing an effective pathway for leveraging camera translation information beyond naive hard-decoding approaches. Through experiments on in-the-wild benchmarks, WATCH achieves state-of-the-art performance in end-to-end trajectory reconstruction. Our work demonstrates the effectiveness of jointly modeling camera-human motion relationships and offers new insights for addressing the long-standing challenge of camera translation integration in global human motion reconstruction. The code will be available publicly.
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Nov 27, 2024



Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.