 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Domain Knowledge for Low Resource Named Entity Recognition
Paper and Code
Mar 28, 2022
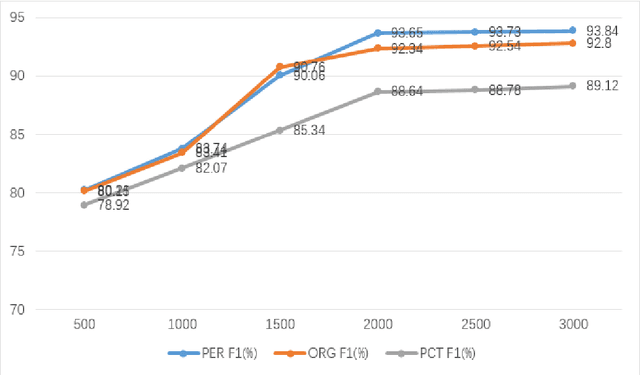
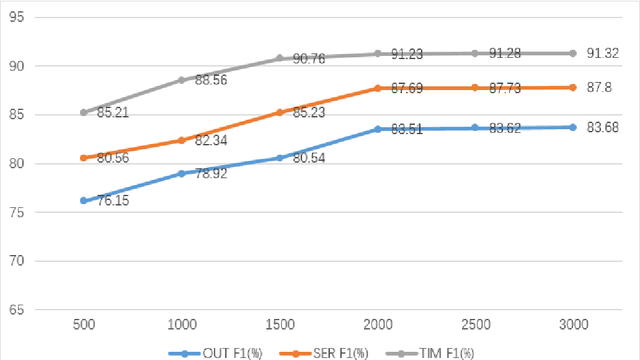

In recent years, named entity recognition has always been a popular research in the field of natural language processing, while traditional deep learning methods require a large amount of labeled data for model training, which makes them not suitable for areas where labeling resources are scarce. In addition, the existing cross-domain knowledge transfer methods need to adjust the entity labels for different fields, so as to increase the training cost. To solve these problems, enlightened by a processing method of Chinese named entity recognition, we propose to use domain knowledge to improve the performance of named entity recognition in areas with low resources. The domain knowledge mainly applied by us is domain dictionary and domain labeled data. We use dictionary information for each word to strengthen its word embedding and domain labeled data to reinforce the recognition effect. The proposed model avoids large-scale data adjustments in different domains while handling named entities recognition with low resources. Experiments demonstrate the effectiveness of our method, which has achieved impressive results on the data set in the field of scientific and technological equipment, and the F1 score has been significantly improved compared with many other baseline methods.