 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Decision-Making for Clinical Assessment of Auto-Segmented Contour Quality
May 01, 2025Purpose: This study presents a Deep Learning (DL)-based quality assessment (QA) approach for evaluating auto-generated contours (auto-contours) in radiotherapy, with emphasis on Online Adaptive Radiotherapy (OART). Leveraging Bayesian Ordinal Classification (BOC) and calibrated uncertainty thresholds, the method enables confident QA predictions without relying on ground truth contours or extensive manual labeling. Methods: We developed a BOC model to classify auto-contour quality and quantify prediction uncertainty. A calibration step was used to optimize uncertainty thresholds that meet clinical accuracy needs. The method was validated under three data scenarios: no manual labels, limited labels, and extensive labels. For rectum contours in prostate cancer, we applied geometric surrogate labels when manual labels were absent, transfer learning when limited, and direct supervision when ample labels were available. Results: The BOC model delivered robust performance across all scenarios. Fine-tuning with just 30 manual labels and calibrating with 34 subjects yielded over 90% accuracy on test data. Using the calibrated threshold, over 93% of the auto-contours' qualities were accurately predicted in over 98% of cases, reducing unnecessary manual reviews and highlighting cases needing correction. Conclusion: The proposed QA model enhances contouring efficiency in OART by reducing manual workload and enabling fast, informed clinical decisions. Through uncertainty quantification, it ensures safer, more reliable radiotherapy workflows.
Incorporating human and learned domain knowledge into training deep neural networks: A differentiable dose volume histogram and adversarial inspired framework for generating Pareto optimal dose distributions in radiation therapy
Aug 16, 2019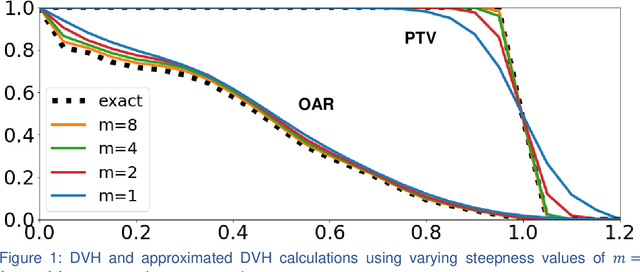
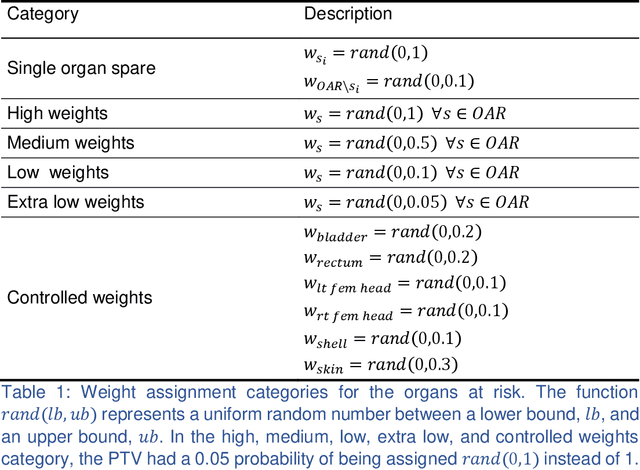
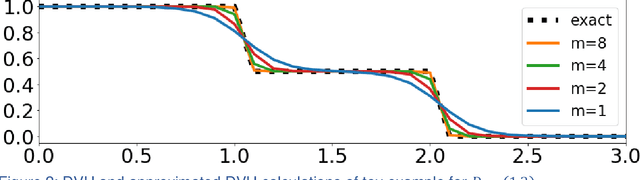

We propose a novel domain specific loss, which is a differentiable loss function based on the dose volume histogram, and combine it with an adversarial loss for the training of deep neural networks to generate Pareto optimal dose distributions. The mean squared error (MSE) loss, dose volume histogram (DVH) loss, and adversarial (ADV) loss were used to train 4 instances of the neural network model: 1) MSE, 2) MSE+ADV, 3) MSE+DVH, and 4) MSE+DVH+ADV. 70 prostate patients were acquired, and the dose influence arrays were calculated for each patient. 1200 Pareto surface plans per patient were generated by pseudo-randomizing the tradeoff weights (84,000 plans total). We divided the data into 54 training, 6 validation, and 10 testing patients. Each model was trained for 100,000 iterations, with a batch size of 2. The prediction time of each model is 0.052 seconds. Quantitatively, the MSE+DVH+ADV model had the lowest prediction error of 0.038 (conformation), 0.026 (homogeneity), 0.298 (R50), 1.65% (D95), 2.14% (D98), 2.43% (D99). The MSE model had the worst prediction error of 0.134 (conformation), 0.041 (homogeneity), 0.520 (R50), 3.91% (D95), 4.33% (D98), 4.60% (D99). For both the mean dose PTV error and the max dose PTV, Body, Bladder and rectum error, the MSE+DVH+ADV outperformed all other models. All model's predictions have an average mean and max dose error less than 2.8% and 4.2%, respectively. Expert human domain specific knowledge can be the largest driver in the performance improvement, and adversarial learning can be used to further capture nuanced features. The real-time prediction capabilities allow for a physician to quickly navigate the tradeoff space, and produce a dose distribution as a tangible endpoint for the dosimetrist to use for planning. This can considerably reduce the treatment planning time, allowing for clinicians to focus their efforts on challenging cases.
Intelligent Parameter Tuning in Optimization-based Iterative CT Reconstruction via Deep Reinforcement Learning
Nov 01, 2017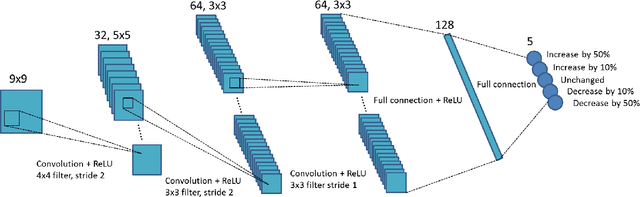
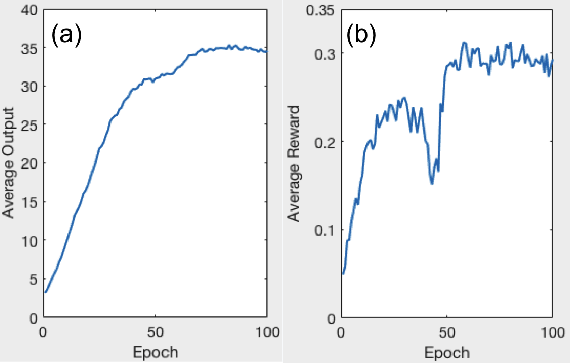
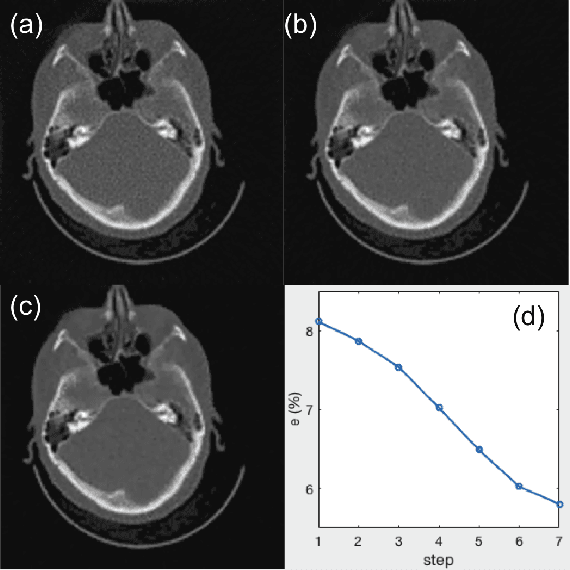
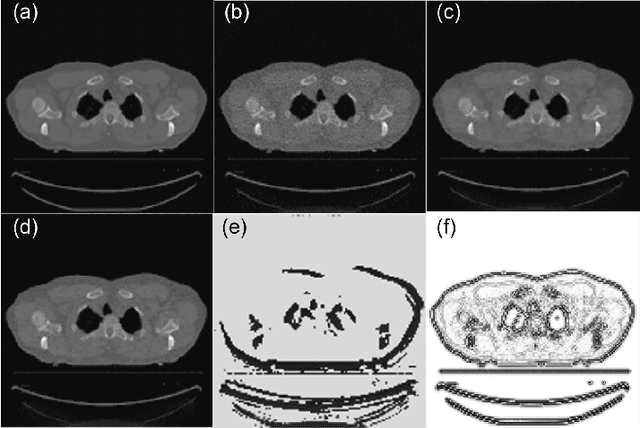
A number of image-processing problems can be formulated as optimization problems. The objective function typically contains several terms specifically designed for different purposes. Parameters in front of these terms are used to control the relative weights among them. It is of critical importance to tune these parameters, as quality of the solution depends on their values. Tuning parameter is a relatively straightforward task for a human, as one can intelligently determine the direction of parameter adjustment based on the solution quality. Yet manual parameter tuning is not only tedious in many cases, but becomes impractical when a number of parameters exist in a problem. Aiming at solving this problem, this paper proposes an approach that employs deep reinforcement learning to train a system that can automatically adjust parameters in a human-like manner. We demonstrate our idea in an example problem of optimization-based iterative CT reconstruction with a pixel-wise total-variation regularization term. We set up a parameter tuning policy network (PTPN), which maps an CT image patch to an output that specifies the direction and amplitude by which the parameter at the patch center is adjusted. We train the PTPN via an end-to-end reinforcement learning procedure. We demonstrate that under the guidance of the trained PTPN for parameter tuning at each pixel, reconstructed CT images attain quality similar or better than in those reconstructed with manually tuned parameters.