 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Physics-Informed Neural Networks
Jan 27, 2025



We present a novel class of Physics-Informed Neural Networks that is formulated based on the principles of Evidential Deep Learning, where the model incorporates uncertainty quantification by learning parameters of a higher-order distribution. The dependent and trainable variables of the PDE residual loss and data-fitting loss terms are recast as functions of the hyperparameters of an evidential prior distribution. Our model is equipped with an information-theoretic regularizer that contains the Kullback-Leibler divergence between two inverse-gamma distributions characterizing predictive uncertainty. Relative to Bayesian-Physics-Informed-Neural-Networks, our framework appeared to exhibit higher sensitivity to data noise, preserve boundary conditions more faithfully and yield empirical coverage probabilities closer to nominal ones. Toward examining its relevance for data mining in scientific discoveries, we demonstrate how to apply our model to inverse problems involving 1D and 2D nonlinear differential equations.
From Generalist to Specialist: Improving Large Language Models for Medical Physics Using ARCoT
May 17, 2024



Large Language Models (LLMs) have achieved remarkable progress, yet their application in specialized fields, such as medical physics, remains challenging due to the need for domain-specific knowledge. This study introduces ARCoT (Adaptable Retrieval-based Chain of Thought), a framework designed to enhance the domain-specific accuracy of LLMs without requiring fine-tuning or extensive retraining. ARCoT integrates a retrieval mechanism to access relevant domain-specific information and employs step-back and chain-of-thought prompting techniques to guide the LLM's reasoning process, ensuring more accurate and context-aware responses. Benchmarking on a medical physics multiple-choice exam, our model outperformed standard LLMs and reported average human performance, demonstrating improvements of up to 68% and achieving a high score of 90%. This method reduces hallucinations and increases domain-specific performance. The versatility and model-agnostic nature of ARCoT make it easily adaptable to various domains, showcasing its significant potential for enhancing the accuracy and reliability of LLMs in specialized fields.
A Proof-of-Concept Study of Artificial Intelligence Assisted Contour Revision
Jul 28, 2021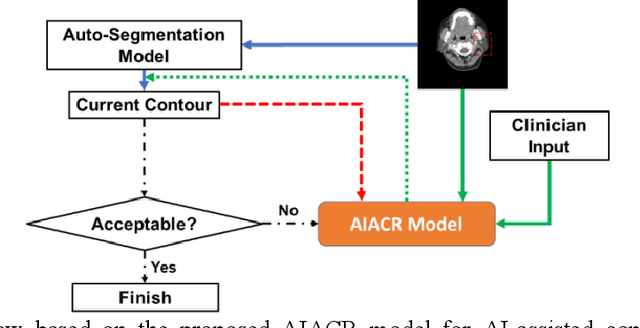

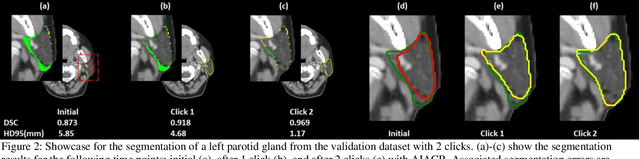
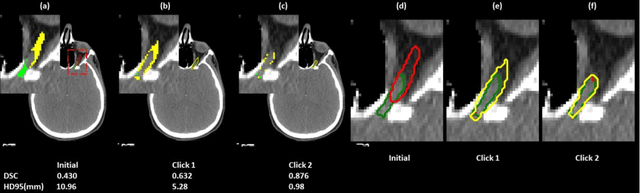
Automatic segmentation of anatomical structures is critical for many medical applications. However, the results are not always clinically acceptable and require tedious manual revision. Here, we present a novel concept called artificial intelligence assisted contour revision (AIACR) and demonstrate its feasibility. The proposed clinical workflow of AIACR is as follows given an initial contour that requires a clinicians revision, the clinician indicates where a large revision is needed, and a trained deep learning (DL) model takes this input to update the contour. This process repeats until a clinically acceptable contour is achieved. The DL model is designed to minimize the clinicians input at each iteration and to minimize the number of iterations needed to reach acceptance. In this proof-of-concept study, we demonstrated the concept on 2D axial images of three head-and-neck cancer datasets, with the clinicians input at each iteration being one mouse click on the desired location of the contour segment. The performance of the model is quantified with Dice Similarity Coefficient (DSC) and 95th percentile of Hausdorff Distance (HD95). The average DSC/HD95 (mm) of the auto-generated initial contours were 0.82/4.3, 0.73/5.6 and 0.67/11.4 for three datasets, which were improved to 0.91/2.1, 0.86/2.4 and 0.86/4.7 with three mouse clicks, respectively. Each DL-based contour update requires around 20 ms. We proposed a novel AIACR concept that uses DL models to assist clinicians in revising contours in an efficient and effective way, and we demonstrated its feasibility by using 2D axial CT images from three head-and-neck cancer datasets.
Site-Agnostic 3D Dose Distribution Prediction with Deep Learning Neural Networks
Jun 15, 2021
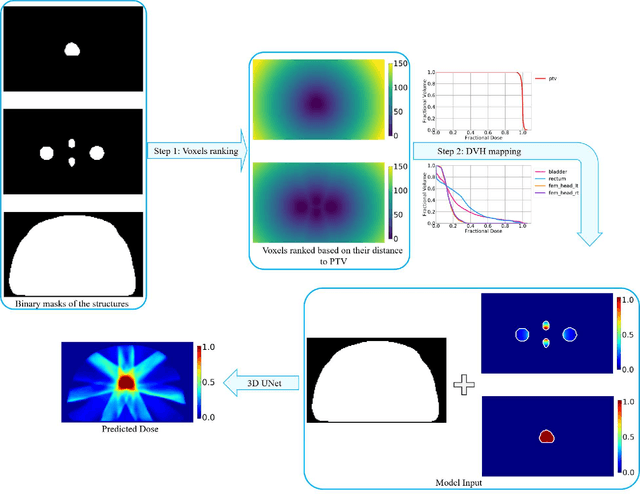
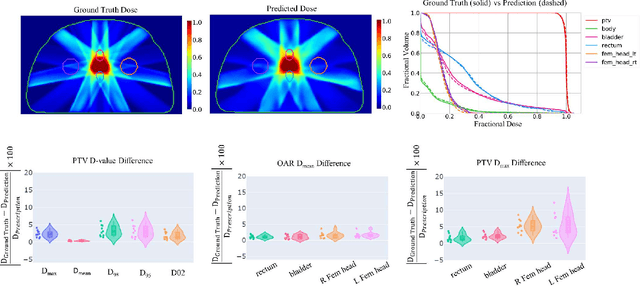
Typically, the current dose prediction models are limited to small amounts of data and require re-training for a specific site, often leading to suboptimal performance. We propose a site-agnostic, 3D dose distribution prediction model using deep learning that can leverage data from any treatment site, thus increasing the total data available to train the model. Applying our proposed model to a new target treatment site requires only a brief fine-tuning of the model to the new data and involves no modifications to the model input channels or its parameters. Thus, it can be efficiently adapted to a different treatment site, even with a small training dataset.
Using Monte Carlo dropout and bootstrap aggregation for uncertainty estimation in radiation therapy dose prediction with deep learning neural networks
Nov 01, 2020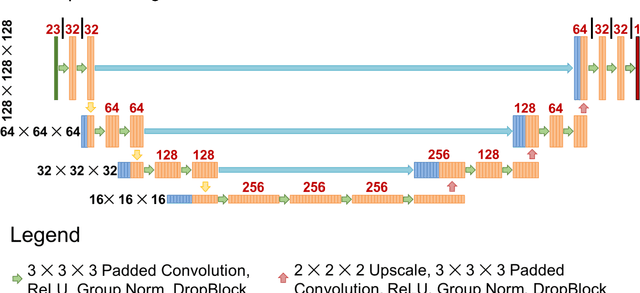
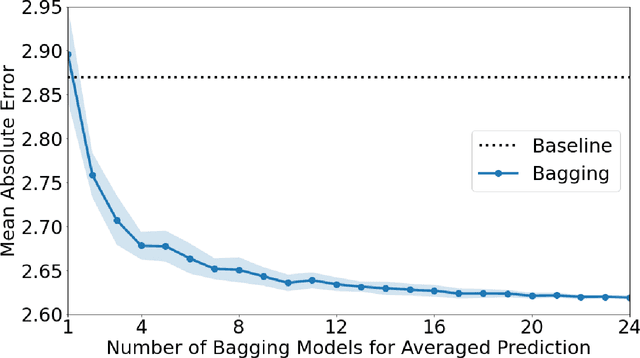
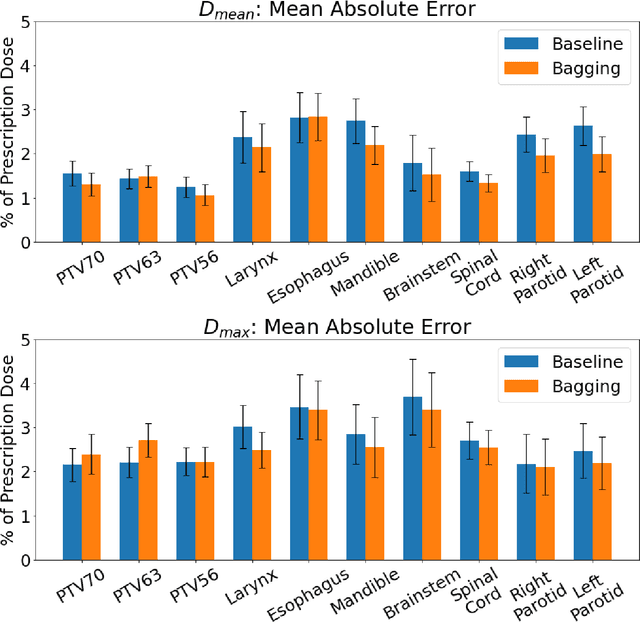
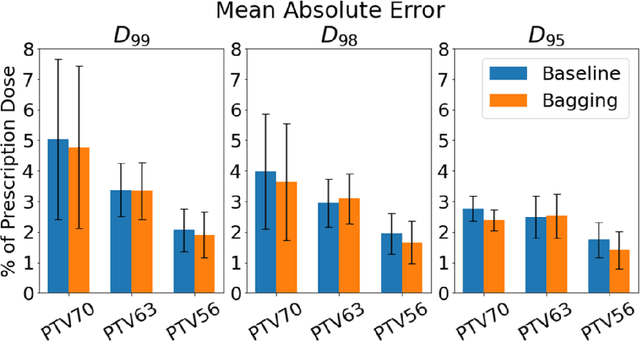
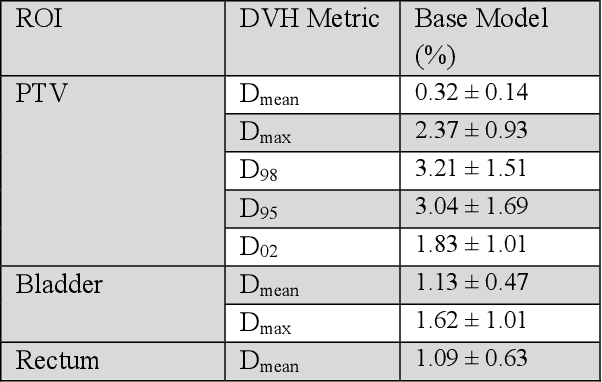
Recently, artificial intelligence technologies and algorithms have become a major focus for advancements in treatment planning for radiation therapy. As these are starting to become incorporated into the clinical workflow, a major concern from clinicians is not whether the model is accurate, but whether the model can express to a human operator when it does not know if its answer is correct. We propose to use Monte Carlo dropout (MCDO) and the bootstrap aggregation (bagging) technique on deep learning models to produce uncertainty estimations for radiation therapy dose prediction. We show that both models are capable of generating a reasonable uncertainty map, and, with our proposed scaling technique, creating interpretable uncertainties and bounds on the prediction and any relevant metrics. Performance-wise, bagging provides statistically significant reduced loss value and errors in most of the metrics investigated in this study. The addition of bagging was able to further reduce errors by another 0.34% for Dmean and 0.19% for Dmax, on average, when compared to the baseline framework. Overall, the bagging framework provided significantly lower MAE of 2.62, as opposed to the baseline framework's MAE of 2.87. The usefulness of bagging, from solely a performance standpoint, does highly depend on the problem and the acceptable predictive error, and its high upfront computational cost during training should be factored in to deciding whether it is advantageous to use it. In terms of deployment with uncertainty estimations turned on, both frameworks offer the same performance time of about 12 seconds. As an ensemble-based metaheuristic, bagging can be used with existing machine learning architectures to improve stability and performance, and MCDO can be applied to any deep learning models that have dropout as part of their architecture.
Incorporating human and learned domain knowledge into training deep neural networks: A differentiable dose volume histogram and adversarial inspired framework for generating Pareto optimal dose distributions in radiation therapy
Aug 16, 2019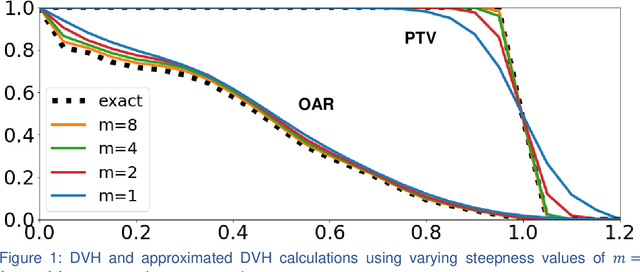
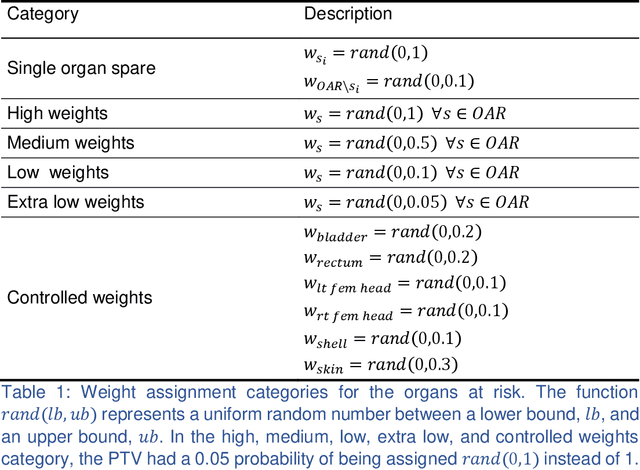
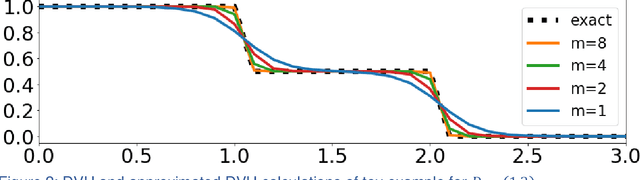

We propose a novel domain specific loss, which is a differentiable loss function based on the dose volume histogram, and combine it with an adversarial loss for the training of deep neural networks to generate Pareto optimal dose distributions. The mean squared error (MSE) loss, dose volume histogram (DVH) loss, and adversarial (ADV) loss were used to train 4 instances of the neural network model: 1) MSE, 2) MSE+ADV, 3) MSE+DVH, and 4) MSE+DVH+ADV. 70 prostate patients were acquired, and the dose influence arrays were calculated for each patient. 1200 Pareto surface plans per patient were generated by pseudo-randomizing the tradeoff weights (84,000 plans total). We divided the data into 54 training, 6 validation, and 10 testing patients. Each model was trained for 100,000 iterations, with a batch size of 2. The prediction time of each model is 0.052 seconds. Quantitatively, the MSE+DVH+ADV model had the lowest prediction error of 0.038 (conformation), 0.026 (homogeneity), 0.298 (R50), 1.65% (D95), 2.14% (D98), 2.43% (D99). The MSE model had the worst prediction error of 0.134 (conformation), 0.041 (homogeneity), 0.520 (R50), 3.91% (D95), 4.33% (D98), 4.60% (D99). For both the mean dose PTV error and the max dose PTV, Body, Bladder and rectum error, the MSE+DVH+ADV outperformed all other models. All model's predictions have an average mean and max dose error less than 2.8% and 4.2%, respectively. Expert human domain specific knowledge can be the largest driver in the performance improvement, and adversarial learning can be used to further capture nuanced features. The real-time prediction capabilities allow for a physician to quickly navigate the tradeoff space, and produce a dose distribution as a tangible endpoint for the dosimetrist to use for planning. This can considerably reduce the treatment planning time, allowing for clinicians to focus their efforts on challenging cases.