 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Data Generation for Offline Reinforcement Learning: A Perspective from Model
Jun 24, 2025Offline reinforcement learning (RL) recently gains growing interests from RL researchers. However, the performance of offline RL suffers from the out-of-distribution problem, which can be corrected by feedback in online RL. Previous offline RL research focuses on restricting the offline algorithm in in-distribution even in-sample action sampling. In contrast, fewer work pays attention to the influence of the batch data. In this paper, we first build a bridge over the batch data and the performance of offline RL algorithms theoretically, from the perspective of model-based offline RL optimization. We draw a conclusion that, with mild assumptions, the distance between the state-action pair distribution generated by the behavioural policy and the distribution generated by the optimal policy, accounts for the performance gap between the policy learned by model-based offline RL and the optimal policy. Secondly, we reveal that in task-agnostic settings, a series of policies trained by unsupervised RL can minimize the worst-case regret in the performance gap. Inspired by the theoretical conclusions, UDG (Unsupervised Data Generation) is devised to generate data and select proper data for offline training under tasks-agnostic settings. Empirical results demonstrate that UDG can outperform supervised data generation on solving unknown tasks.
Choices are More Important than Efforts: LLM Enables Efficient Multi-Agent Exploration
Oct 03, 2024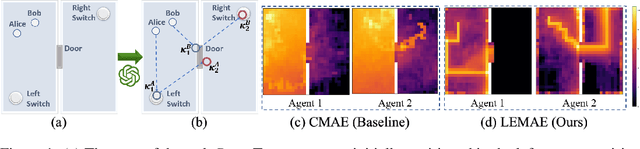

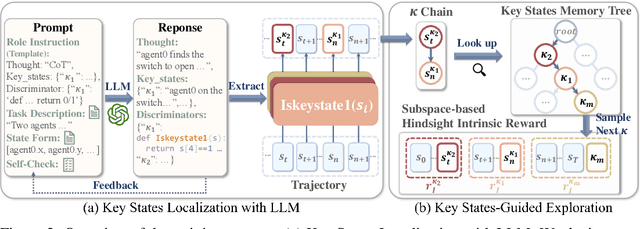
With expansive state-action spaces, efficient multi-agent exploration remains a longstanding challenge in reinforcement learning. Although pursuing novelty, diversity, or uncertainty attracts increasing attention, redundant efforts brought by exploration without proper guidance choices poses a practical issue for the community. This paper introduces a systematic approach, termed LEMAE, choosing to channel informative task-relevant guidance from a knowledgeable Large Language Model (LLM) for Efficient Multi-Agent Exploration. Specifically, we ground linguistic knowledge from LLM into symbolic key states, that are critical for task fulfillment, in a discriminative manner at low LLM inference costs. To unleash the power of key states, we design Subspace-based Hindsight Intrinsic Reward (SHIR) to guide agents toward key states by increasing reward density. Additionally, we build the Key State Memory Tree (KSMT) to track transitions between key states in a specific task for organized exploration. Benefiting from diminishing redundant explorations, LEMAE outperforms existing SOTA approaches on the challenging benchmarks (e.g., SMAC and MPE) by a large margin, achieving a 10x acceleration in certain scenarios.
Hokoff: Real Game Dataset from Honor of Kings and its Offline Reinforcement Learning Benchmarks
Aug 20, 2024



The advancement of Offline Reinforcement Learning (RL) and Offline Multi-Agent Reinforcement Learning (MARL) critically depends on the availability of high-quality, pre-collected offline datasets that represent real-world complexities and practical applications. However, existing datasets often fall short in their simplicity and lack of realism. To address this gap, we propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. This data is derived from Honor of Kings, a recognized Multiplayer Online Battle Arena (MOBA) game known for its intricate nature, closely resembling real-life situations. Utilizing this framework, we benchmark a variety of offline RL and offline MARL algorithms. We also introduce a novel baseline algorithm tailored for the inherent hierarchical action space of the game. We reveal the incompetency of current offline RL approaches in handling task complexity, generalization and multi-task learning.
LLM-Empowered State Representation for Reinforcement Learning
Jul 18, 2024
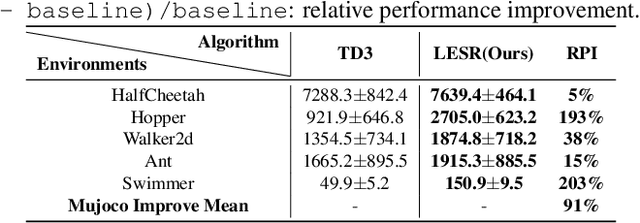

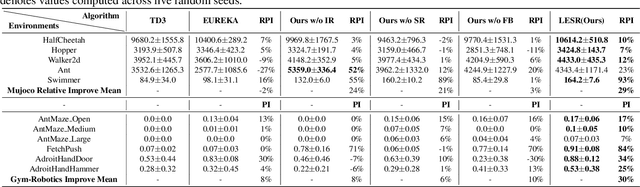
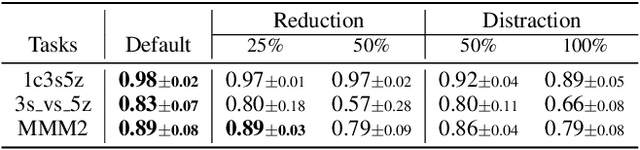
Conventional state representations in reinforcement learning often omit critical task-related details, presenting a significant challenge for value networks in establishing accurate mappings from states to task rewards. Traditional methods typically depend on extensive sample learning to enrich state representations with task-specific information, which leads to low sample efficiency and high time costs. Recently, surging knowledgeable large language models (LLM) have provided promising substitutes for prior injection with minimal human intervention. Motivated by this, we propose LLM-Empowered State Representation (LESR), a novel approach that utilizes LLM to autonomously generate task-related state representation codes which help to enhance the continuity of network mappings and facilitate efficient training. Experimental results demonstrate LESR exhibits high sample efficiency and outperforms state-of-the-art baselines by an average of 29% in accumulated reward in Mujoco tasks and 30% in success rates in Gym-Robotics tasks.
Counterfactual Conservative Q Learning for Offline Multi-agent Reinforcement Learning
Sep 22, 2023



Offline multi-agent reinforcement learning is challenging due to the coupling effect of both distribution shift issue common in offline setting and the high dimension issue common in multi-agent setting, making the action out-of-distribution (OOD) and value overestimation phenomenon excessively severe. Tomitigate this problem, we propose a novel multi-agent offline RL algorithm, named CounterFactual Conservative Q-Learning (CFCQL) to conduct conservative value estimation. Rather than regarding all the agents as a high dimensional single one and directly applying single agent methods to it, CFCQL calculates conservative regularization for each agent separately in a counterfactual way and then linearly combines them to realize an overall conservative value estimation. We prove that it still enjoys the underestimation property and the performance guarantee as those single agent conservative methods do, but the induced regularization and safe policy improvement bound are independent of the agent number, which is therefore theoretically superior to the direct treatment referred to above, especially when the agent number is large. We further conduct experiments on four environments including both discrete and continuous action settings on both existing and our man-made datasets, demonstrating that CFCQL outperforms existing methods on most datasets and even with a remarkable margin on some of them.
Wasserstein Unsupervised Reinforcement Learning
Oct 15, 2021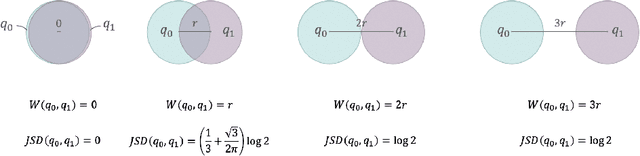
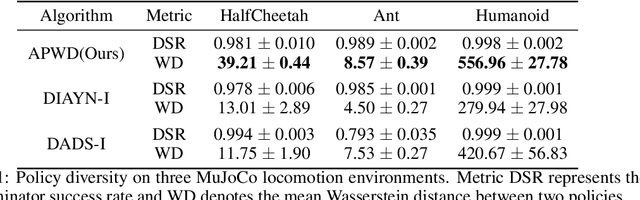
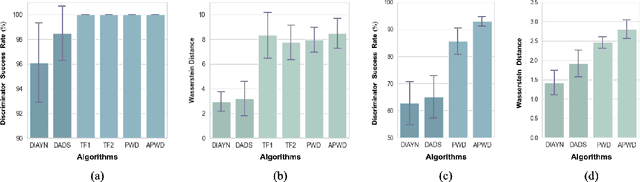

Unsupervised reinforcement learning aims to train agents to learn a handful of policies or skills in environments without external reward. These pre-trained policies can accelerate learning when endowed with external reward, and can also be used as primitive options in hierarchical reinforcement learning. Conventional approaches of unsupervised skill discovery feed a latent variable to the agent and shed its empowerment on agent's behavior by mutual information (MI) maximization. However, the policies learned by MI-based methods cannot sufficiently explore the state space, despite they can be successfully identified from each other. Therefore we propose a new framework Wasserstein unsupervised reinforcement learning (WURL) where we directly maximize the distance of state distributions induced by different policies. Additionally, we overcome difficulties in simultaneously training N(N >2) policies, and amortizing the overall reward to each step. Experiments show policies learned by our approach outperform MI-based methods on the metric of Wasserstein distance while keeping high discriminability. Furthermore, the agents trained by WURL can sufficiently explore the state space in mazes and MuJoCo tasks and the pre-trained policies can be applied to downstream tasks by hierarchical learning.
Reducing Conservativeness Oriented Offline Reinforcement Learning
Feb 27, 2021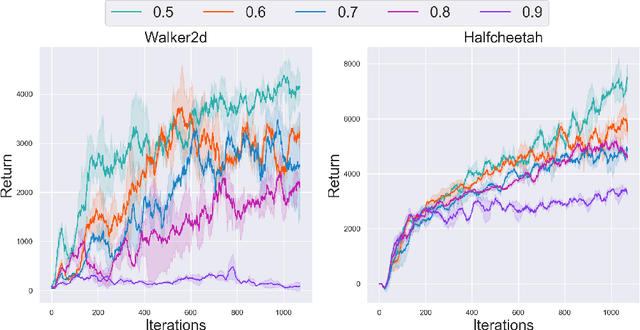
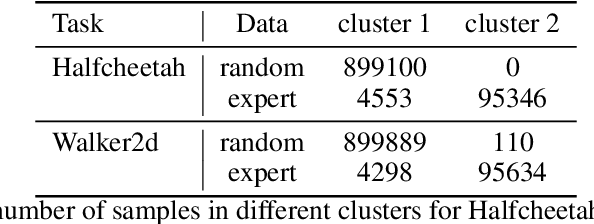
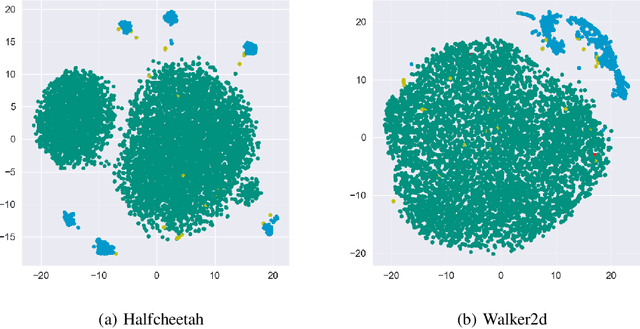
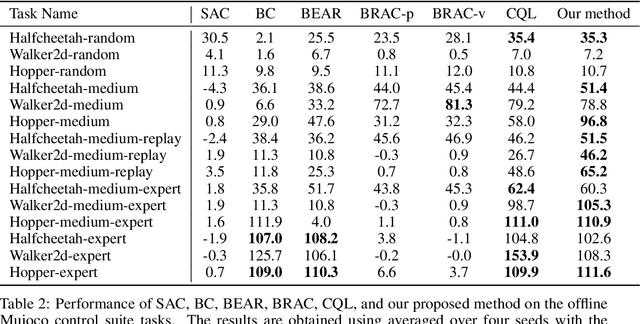
In offline reinforcement learning, a policy learns to maximize cumulative rewards with a fixed collection of data. Towards conservative strategy, current methods choose to regularize the behavior policy or learn a lower bound of the value function. However, exorbitant conservation tends to impair the policy's generalization ability and degrade its performance, especially for the mixed datasets. In this paper, we propose the method of reducing conservativeness oriented reinforcement learning. On the one hand, the policy is trained to pay more attention to the minority samples in the static dataset to address the data imbalance problem. On the other hand, we give a tighter lower bound of value function than previous methods to discover potential optimal actions. Consequently, our proposed method is able to tackle the skewed distribution of the provided dataset and derive a value function closer to the expected value function. Experimental results demonstrate that our proposed method outperforms the state-of-the-art methods in D4RL offline reinforcement learning evaluation tasks and our own designed mixed datasets.
Credit Assignment with Meta-Policy Gradient for Multi-Agent Reinforcement Learning
Feb 24, 2021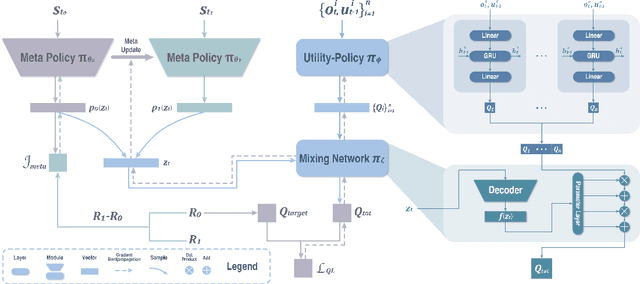
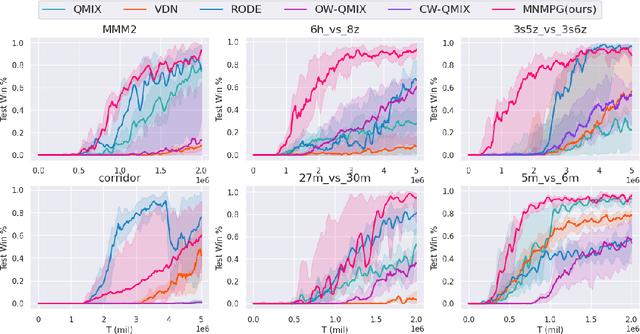
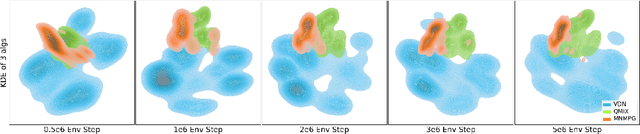
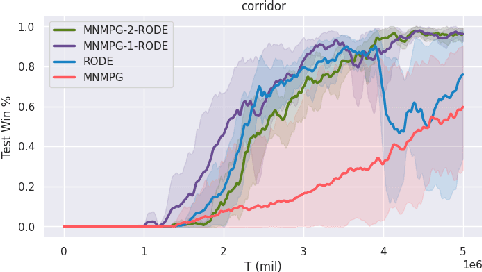
Reward decomposition is a critical problem in centralized training with decentralized execution~(CTDE) paradigm for multi-agent reinforcement learning. To take full advantage of global information, which exploits the states from all agents and the related environment for decomposing Q values into individual credits, we propose a general meta-learning-based Mixing Network with Meta Policy Gradient~(MNMPG) framework to distill the global hierarchy for delicate reward decomposition. The excitation signal for learning global hierarchy is deduced from the episode reward difference between before and after "exercise updates" through the utility network. Our method is generally applicable to the CTDE method using a monotonic mixing network. Experiments on the StarCraft II micromanagement benchmark demonstrate that our method just with a simple utility network is able to outperform the current state-of-the-art MARL algorithms on 4 of 5 super hard scenarios. Better performance can be further achieved when combined with a role-based utility network.
PFRL: Pose-Free Reinforcement Learning for 6D Pose Estimation
Feb 24, 2021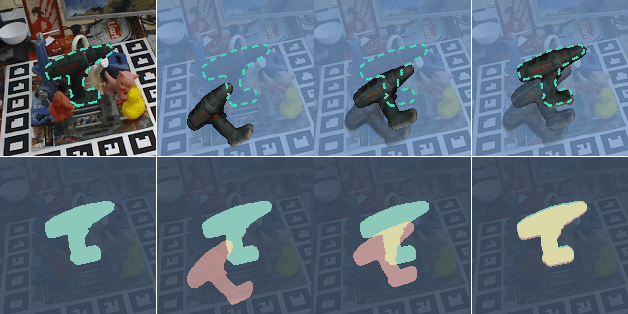
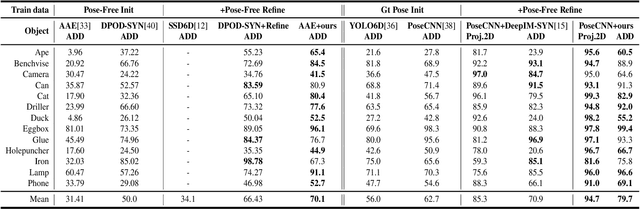
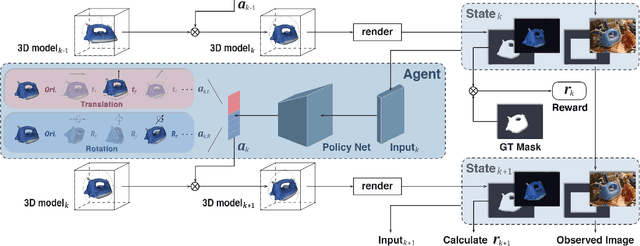
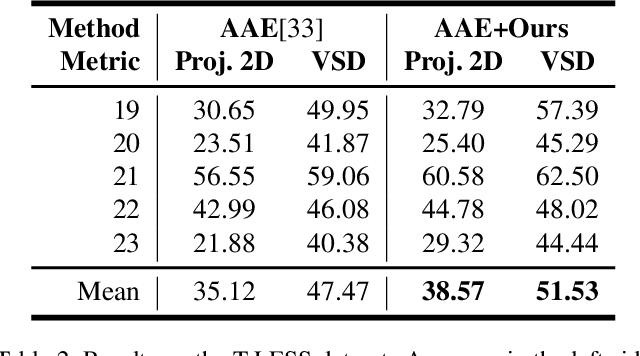
6D pose estimation from a single RGB image is a challenging and vital task in computer vision. The current mainstream deep model methods resort to 2D images annotated with real-world ground-truth 6D object poses, whose collection is fairly cumbersome and expensive, even unavailable in many cases. In this work, to get rid of the burden of 6D annotations, we formulate the 6D pose refinement as a Markov Decision Process and impose on the reinforcement learning approach with only 2D image annotations as weakly-supervised 6D pose information, via a delicate reward definition and a composite reinforced optimization method for efficient and effective policy training. Experiments on LINEMOD and T-LESS datasets demonstrate that our Pose-Free approach is able to achieve state-of-the-art performance compared with the methods without using real-world ground-truth 6D pose labels.
Skill Discovery of Coordination in Multi-agent Reinforcement Learning
Jun 07, 2020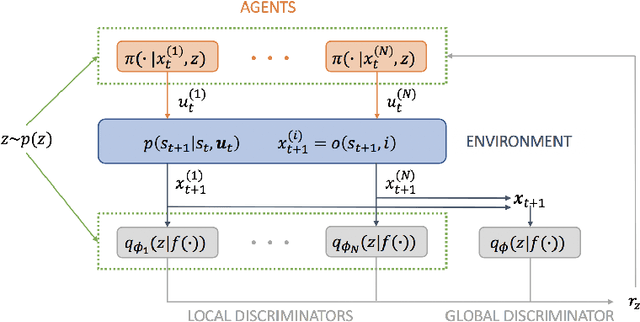

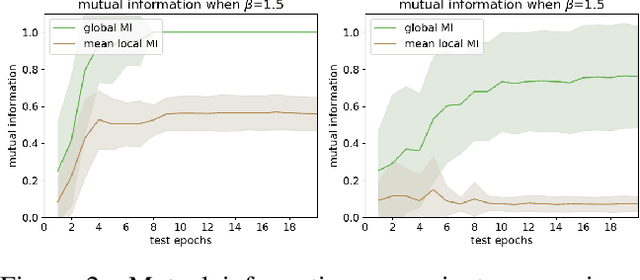
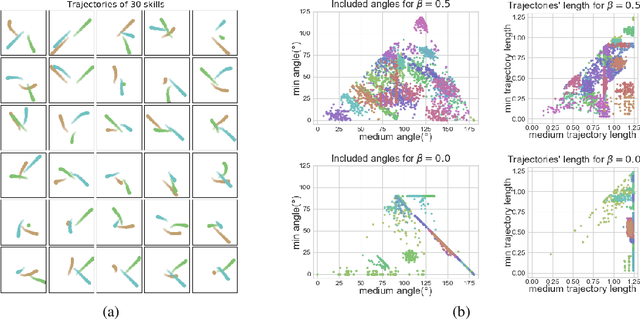
Unsupervised skill discovery drives intelligent agents to explore the unknown environment without task-specific reward signal, and the agents acquire various skills which may be useful when the agents adapt to new tasks. In this paper, we propose "Multi-agent Skill Discovery"(MASD), a method for discovering skills for coordination patterns of multiple agents. The proposed method aims to maximize the mutual information between a latent code Z representing skills and the combination of the states of all agents. Meanwhile it suppresses the empowerment of Z on the state of any single agent by adversarial training. In another word, it sets an information bottleneck to avoid empowerment degeneracy. First we show the emergence of various skills on the level of coordination in a general particle multi-agent environment. Second, we reveal that the "bottleneck" prevents skills from collapsing to a single agent and enhances the diversity of learned skills. Finally, we show the pretrained policies have better performance on supervised RL tasks.