 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Conservativeness Oriented Offline Reinforcement Learning
Paper and Code
Feb 27, 2021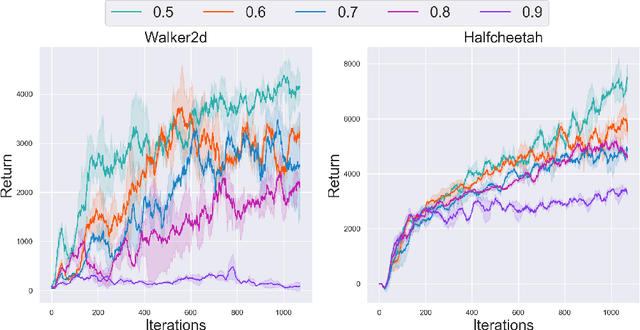
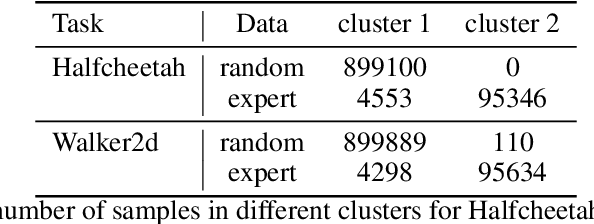
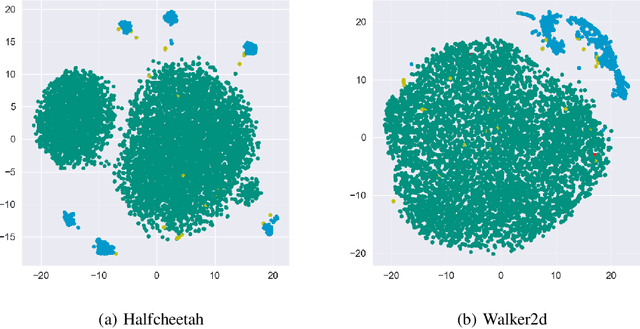
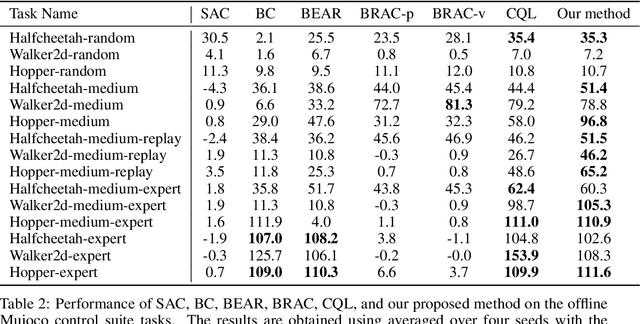
In offline reinforcement learning, a policy learns to maximize cumulative rewards with a fixed collection of data. Towards conservative strategy, current methods choose to regularize the behavior policy or learn a lower bound of the value function. However, exorbitant conservation tends to impair the policy's generalization ability and degrade its performance, especially for the mixed datasets. In this paper, we propose the method of reducing conservativeness oriented reinforcement learning. On the one hand, the policy is trained to pay more attention to the minority samples in the static dataset to address the data imbalance problem. On the other hand, we give a tighter lower bound of value function than previous methods to discover potential optimal actions. Consequently, our proposed method is able to tackle the skewed distribution of the provided dataset and derive a value function closer to the expected value function. Experimental results demonstrate that our proposed method outperforms the state-of-the-art methods in D4RL offline reinforcement learning evaluation tasks and our own designed mixed datasets.