 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-Pose: Enhancing Human Pose and Action Understanding via Keypoint-Integrated Instruction Tuning
Jun 26, 2025Current vision-language models (VLMs) are well-adapted for general visual understanding tasks. However, they perform inadequately when handling complex visual tasks related to human poses and actions due to the lack of specialized vision-language instruction-following data. We introduce a method for generating such data by integrating human keypoints with traditional visual features such as captions and bounding boxes, enabling more precise understanding of human-centric scenes. Our approach constructs a dataset comprising 200,328 samples tailored to fine-tune models for human-centric tasks, focusing on three areas: conversation, detailed description, and complex reasoning. We establish an Extended Human Pose and Action Understanding Benchmark (E-HPAUB) to assess model performance on human pose and action understanding. We fine-tune the LLaVA-1.5-7B model using this dataset and evaluate our resulting LLaVA-Pose model on the benchmark, achieving significant improvements. Experimental results show an overall improvement of 33.2% compared to the original LLaVA-1.5-7B model. These findings highlight the effectiveness of keypoint-integrated data in enhancing multimodal models for human-centric visual understanding. Code is available at https://github.com/Ody-trek/LLaVA-Pose.
Keypoints-Integrated Instruction-Following Data Generation for Enhanced Human Pose Understanding in Multimodal Models
Sep 14, 2024Current multimodal models are well-suited for general visual understanding tasks. However, they perform inadequately when handling complex visual tasks related to human poses and actions, primarily due to the lack of specialized instruction-following data. We introduce a new method for generating such data by integrating human keypoints with traditional visual features like captions and bounding boxes. Our approach produces datasets designed for fine-tuning models to excel in human-centric activities, focusing on three specific types: conversation, detailed description, and complex reasoning. We fine-tuned the LLaVA-7B model with this novel dataset, achieving significant improvements across various human pose-related tasks. Experimental results show an overall improvement of 21.18% compared to the original LLaVA-7B model. These findings demonstrate the effectiveness of keypoints-assisted data in enhancing multimodal models.
Bayesian Sparse Covariance Structure Analysis for Correlated Count Data
Jun 05, 2020
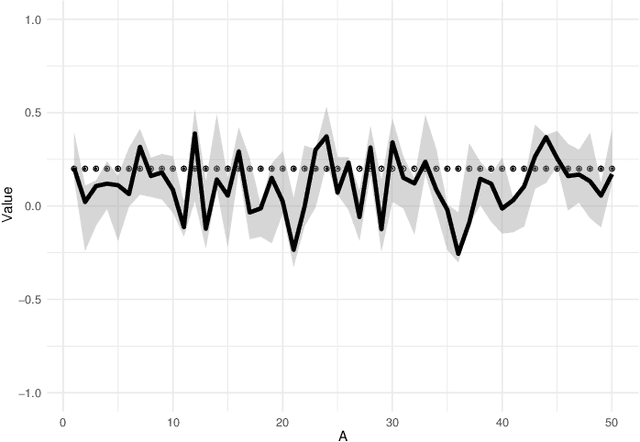
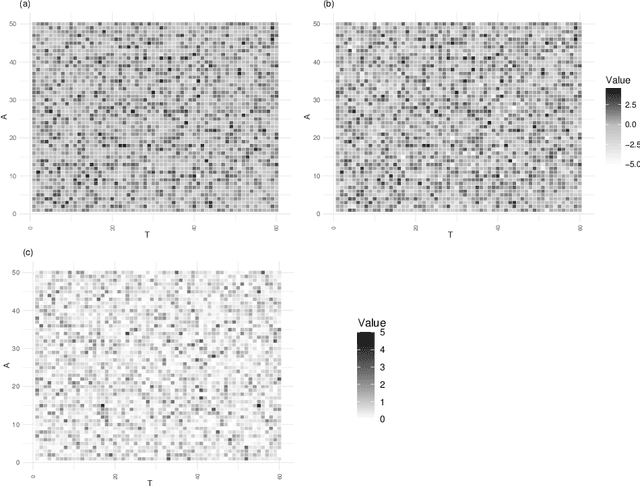
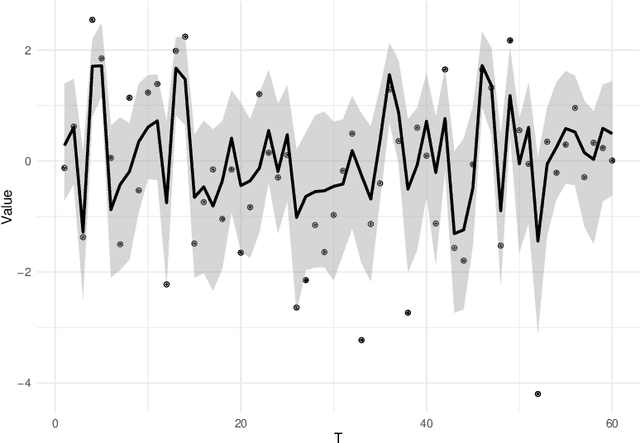
In this paper, we propose a Bayesian Graphical LASSO for correlated countable data and apply it to spatial crime data. In the proposed model, we assume a Gaussian Graphical Model for the latent variables which dominate the potential risks of crimes. To evaluate the proposed model, we determine optimal hyperparameters which represent samples better. We apply the proposed model for estimation of the sparse inverse covariance of the latent variable and evaluate the partial correlation coefficients. Finally, we illustrate the results on crime spots data and consider the estimated latent variables and the partial correlation coefficients of the sparse inverse covariance.
Interpretation of ResNet by Visualization of Preferred Stimulus in Receptive Fields
Jun 02, 2020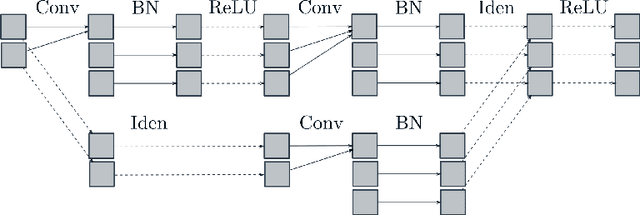
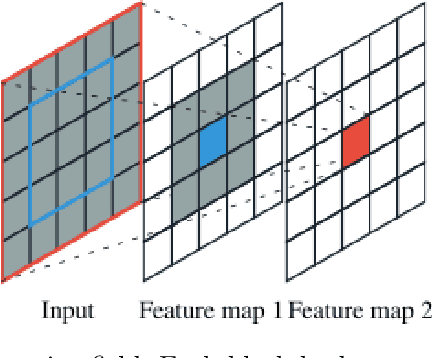
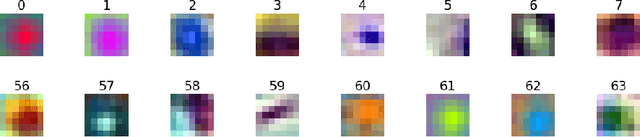

One of the methods used in image recognition is the Deep Convolutional Neural Network (DCNN). DCNN is a model in which the expressive power of features is greatly improved by deepening the hidden layer of CNN. The architecture of CNNs is determined based on a model of the visual cortex of mammals. There is a model called Residual Network (ResNet) that has a skip connection. ResNet is an advanced model in terms of the learning method, but it has no biological viewpoint. In this research, we investigate the receptive fields of a ResNet on the classification task in ImageNet. We find that ResNet has orientation selective neurons and double opponent color neurons. In addition, we suggest that some inactive neurons in the first layer of ResNet effect for the classification task.
Fast Bayesian Restoration of Poisson Corrupted Images with INLA
Apr 02, 2019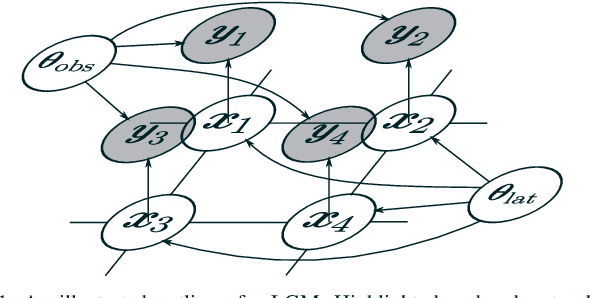
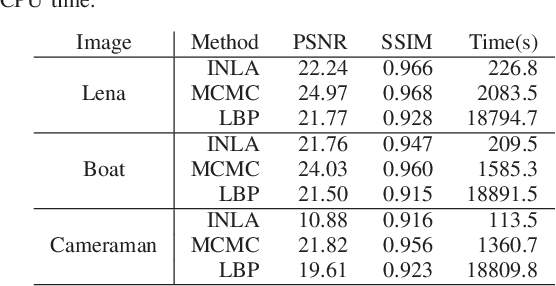


Photon-limited images are often seen in fields such as medical imaging. Although the number of collected photons on an image sensor statistically follows Poisson distribution, this type of noise is intractable, unlike Gaussian noise. In this study, we propose a Bayesian restoration method of Poisson corrupted image using Integrated Nested Laplace Approximation (INLA), which is a computational method to evaluate marginalized posterior distributions of latent Gaussian models (LGMs). When the original image can be regarded as ICAR (intrinsic conditional auto-regressive) model reasonably, our method performs very faster than well-known ones such as loopy belief propagation-based method and Markov chain Monte Carlo (MCMC) without decreasing the accuracy.
A Generative Model of Textures Using Hierarchical Probabilistic Principal Component Analysis
Oct 16, 2018
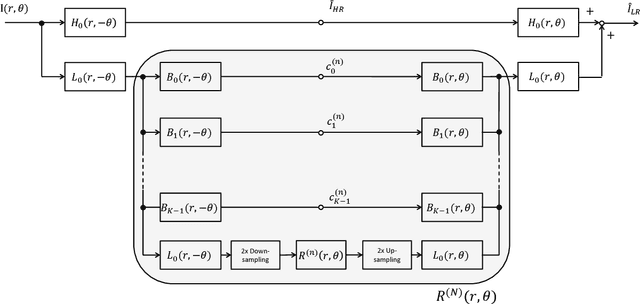


Modeling of textures in natural images is an important task to make a microscopic model of natural images. Portilla and Simoncelli proposed a generative texture model, which is based on the mechanism of visual systems in brains, with a set of texture features and a feature matching. On the other hand, the texture features, used in Portillas' model, have redundancy between its components came from typical natural textures. In this paper, we propose a contracted texture model which provides a dimension reduction for the Portillas' feature. This model is based on a hierarchical principal components analysis using known group structure of the feature. In the experiment, we reveal effective dimensions to describe texture is fewer than the original description. Moreover, we also demonstrate how well the textures can be synthesized from the contracted texture representations.
* 6 pages, 9 figures; A proceeding of PDPTA'17 accepted as an oral presentation
Feature Representation Analysis of Deep Convolutional Neural Network using Two-stage Feature Transfer -An Application for Diffuse Lung Disease Classification-
Oct 15, 2018
Transfer learning is a machine learning technique designed to improve generalization performance by using pre-trained parameters obtained from other learning tasks. For image recognition tasks, many previous studies have reported that, when transfer learning is applied to deep neural networks, performance improves, despite having limited training data. This paper proposes a two-stage feature transfer learning method focusing on the recognition of textural medical images. During the proposed method, a model is successively trained with massive amounts of natural images, some textural images, and the target images. We applied this method to the classification task of textural X-ray computed tomography images of diffuse lung diseases. In our experiment, the two-stage feature transfer achieves the best performance compared to a from-scratch learning and a conventional single-stage feature transfer. We also investigated the robustness of the target dataset, based on size. Two-stage feature transfer shows better robustness than the other two learning methods. Moreover, we analyzed the feature representations obtained from DLDs imagery inputs for each feature transfer models using a visualization method. We showed that the two-stage feature transfer obtains both edge and textural features of DLDs, which does not occur in conventional single-stage feature transfer models.
B-DCGAN:Evaluation of Binarized DCGAN for FPGA
Mar 29, 2018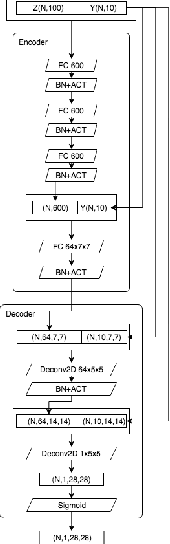
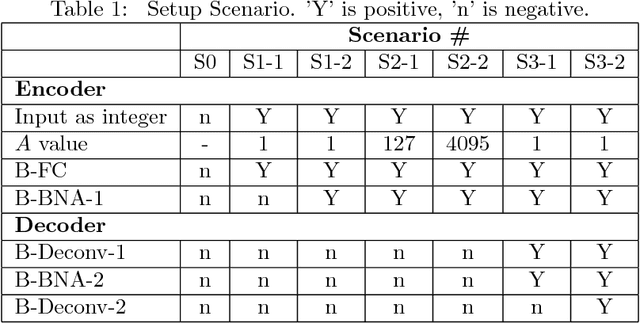

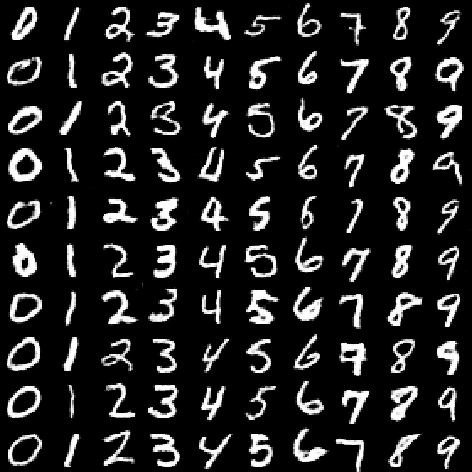
We are trying to implement deep neural networks in the edge computing environment for real-world applications such as the IoT(Internet of Things), the FinTech etc., for the purpose of utilizing the significant achievement of Deep Learning in recent years. Especially, we now focus algorithm implementation on FPGA, because FPGA is one of the promising devices for low-cost and low-power implementation of the edge computer. In this work, we introduce Binary-DCGAN(B-DCGAN) - Deep Convolutional GAN model with binary weights and activations, and with using integer-valued operations in forward pass(train-time and run-time). And we show how to implement B-DCGAN on FPGA(Xilinx Zynq). Using the B-DCGAN, we do feasibility study of FPGA's characteristic and performance for Deep Learning. Because the binarization and using integer-valued operation reduce the memory capacity and the number of the circuit gates, it is very effective for FPGA implementation. On the other hand, the quality of generated data from the model will be decreased by these reductions. So we investigate the influence of these reductions.
Simultaneous Estimation of Non-Gaussian Components and their Correlation Structure
Jul 27, 2017The statistical dependencies which independent component analysis (ICA) cannot remove often provide rich information beyond the linear independent components. It would thus be very useful to estimate the dependency structure from data. While such models have been proposed, they usually concentrated on higher-order correlations such as energy (square) correlations. Yet, linear correlations are a most fundamental and informative form of dependency in many real data sets. Linear correlations are usually completely removed by ICA and related methods, so they can only be analyzed by developing new methods which explicitly allow for linearly correlated components. In this paper, we propose a probabilistic model of linear non-Gaussian components which are allowed to have both linear and energy correlations. The precision matrix of the linear components is assumed to be randomly generated by a higher-order process and explicitly parametrized by a parameter matrix. The estimation of the parameter matrix is shown to be particularly simple because using score matching, the objective function is a quadratic form. Using simulations with artificial data, we demonstrate that the proposed method improves identifiability of non-Gaussian components by simultaneously learning their correlation structure. Applications on simulated complex cells with natural image input, as well as spectrograms of natural audio data show that the method finds new kinds of dependencies between the components.
Analysis of dropout learning regarded as ensemble learning
Jun 20, 2017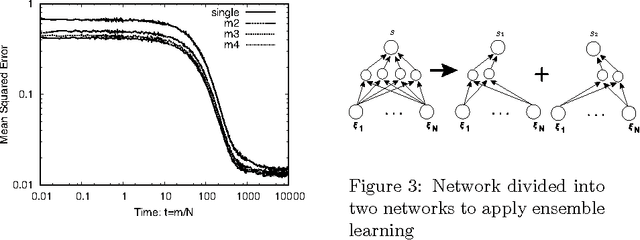
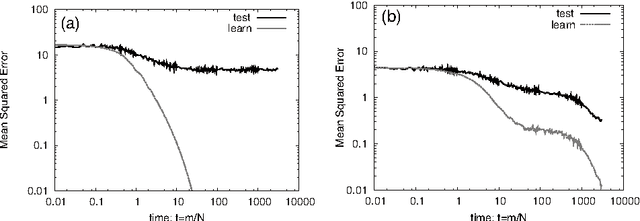
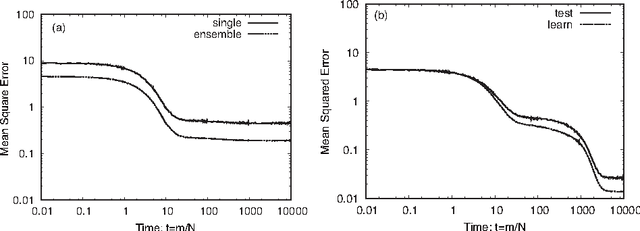
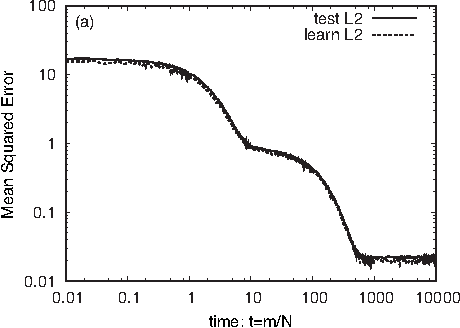
Deep learning is the state-of-the-art in fields such as visual object recognition and speech recognition. This learning uses a large number of layers, huge number of units, and connections. Therefore, overfitting is a serious problem. To avoid this problem, dropout learning is proposed. Dropout learning neglects some inputs and hidden units in the learning process with a probability, p, and then, the neglected inputs and hidden units are combined with the learned network to express the final output. We find that the process of combining the neglected hidden units with the learned network can be regarded as ensemble learning, so we analyze dropout learning from this point of view.
* 9 pages, 8 figures, submitted to Conference