 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Sentiment Analysis via Latent Category Distribution and Constrained Decoding
Jul 31, 2024Fine-grained sentiment analysis involves extracting and organizing sentiment elements from textual data. However, existing approaches often overlook issues of category semantic inclusion and overlap, as well as inherent structural patterns within the target sequence. This study introduces a generative sentiment analysis model. To address the challenges related to category semantic inclusion and overlap, a latent category distribution variable is introduced. By reconstructing the input of a variational autoencoder, the model learns the intensity of the relationship between categories and text, thereby improving sequence generation. Additionally, a trie data structure and constrained decoding strategy are utilized to exploit structural patterns, which in turn reduces the search space and regularizes the generation process. Experimental results on the Restaurant-ACOS and Laptop-ACOS datasets demonstrate a significant performance improvement compared to baseline models. Ablation experiments further confirm the effectiveness of latent category distribution and constrained decoding strategy.
Entity-centered Cross-document Relation Extraction
Oct 29, 2022



Relation Extraction (RE) is a fundamental task of information extraction, which has attracted a large amount of research attention. Previous studies focus on extracting the relations within a sentence or document, while currently researchers begin to explore cross-document RE. However, current cross-document RE methods directly utilize text snippets surrounding target entities in multiple given documents, which brings considerable noisy and non-relevant sentences. Moreover, they utilize all the text paths in a document bag in a coarse-grained way, without considering the connections between these text paths.In this paper, we aim to address both of these shortages and push the state-of-the-art for cross-document RE. First, we focus on input construction for our RE model and propose an entity-based document-context filter to retain useful information in the given documents by using the bridge entities in the text paths. Second, we propose a cross-document RE model based on cross-path entity relation attention, which allow the entity relations across text paths to interact with each other. We compare our cross-document RE method with the state-of-the-art methods in the dataset CodRED. Our method outperforms them by at least 10% in F1, thus demonstrating its effectiveness.
OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction
Sep 06, 2022
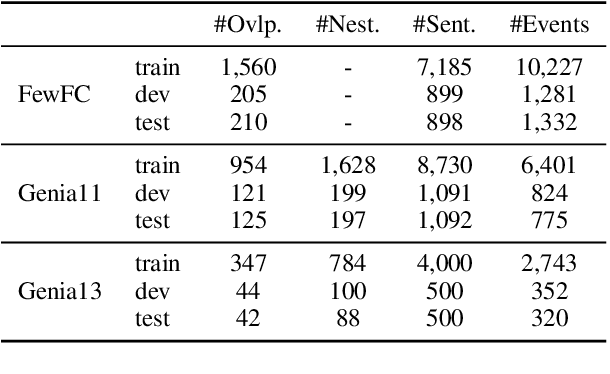

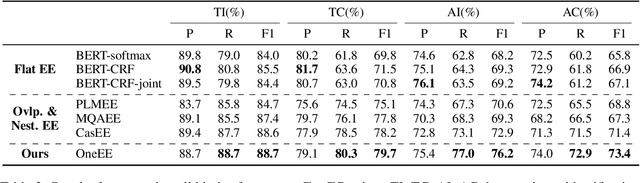
Event extraction (EE) is an essential task of information extraction, which aims to extract structured event information from unstructured text. Most prior work focuses on extracting flat events while neglecting overlapped or nested ones. A few models for overlapped and nested EE includes several successive stages to extract event triggers and arguments,which suffer from error propagation. Therefore, we design a simple yet effective tagging scheme and model to formulate EE as word-word relation recognition, called OneEE. The relations between trigger or argument words are simultaneously recognized in one stage with parallel grid tagging, thus yielding a very fast event extraction speed. The model is equipped with an adaptive event fusion module to generate event-aware representations and a distance-aware predictor to integrate relative distance information for word-word relation recognition, which are empirically demonstrated to be effective mechanisms. Experiments on 3 overlapped and nested EE benchmarks, namely FewFC, Genia11, and Genia13, show that OneEE achieves the state-of-the-art (SOTA) results. Moreover, the inference speed of OneEE is faster than those of baselines in the same condition, and can be further substantially improved since it supports parallel inference.