 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPADE-Bench: Evaluating Spontaneous Strategic Deception in Agents via Plan-Action Divergence
Jun 01, 2026As LLM-based agents expand their operational scope, reliability becomes a prerequisite for real-world deployment. However, in practical applications, human users cannot monitor every immediate behavior; instead, the execution process often remains a black box, leaving users dependent solely on the agent's self-reported updates. This opacity creates a critical risk: agents may present observer-facing reports that diverge from their executed actions, rendering the system uncontrollable, especially in high-stakes autonomous scenarios. We term such self-reported plan-action divergence as agent deception. To assess this, we introduce SPADE-Bench, a benchmark designed to evaluate spontaneous plan-action divergence. Unlike prior deception benchmarks, SPADE-Bench simultaneously integrates actual tool execution and controlled pressure scenarios. This design ensures ecological validity and rigorously distinguishes strategic deception from mere hallucination through controlled plan-action comparisons under pressure. Experiments across mainstream models confirm that agent deception is a genuine and pressing issue in tool-use contexts. By providing a comprehensive and robust evaluation framework, SPADE-Bench fills a critical gap in agent safety, facilitating the community's progress toward building trustworthy and controllable autonomous systems.
Beyond Autoregressive RTG: Conditioning via Injection Outside Sequential Modeling in Decision Transformer
May 07, 2026Decision Transformer (DT) formulates offline reinforcement learning as autoregressive sequence modeling, achieving promising results by predicting actions from a sequence of Return-to-Go (RTG), state, and action tokens. However, RTG is a scalar that summarizes future rewards, containing far less information than typical state or action vectors, yet it consumes the same computational budget per token. Worse, the self-attention cost of Transformers grows quadratically with sequence length, so including RTG as a separate token adds unnecessary overhead. We propose SlimDT, which removes RTG from the autoregressive sequence. Instead, we inject RTG information into the state representations before the sequential modeling step, allowing the Transformer to process only a compact (state, action) sequence. This reduces the sequence length by one-third, directly improving inference efficiency. On the D4RL benchmark, SlimDT surpasses standard DT across various tasks and achieves performance comparable to existing state-of-the-art methods. Decoupling a sparse conditioning signal from an information-rich sequence thus yields both computational gains and higher task performance.
ShuttleEnv: An Interactive Data-Driven RL Environment for Badminton Strategy Modeling
Mar 18, 2026We present ShuttleEnv, an interactive and data-driven simulation environment for badminton, designed to support reinforcement learning and strategic behavior analysis in fast-paced adversarial sports. The environment is grounded in elite-player match data and employs explicit probabilistic models to simulate rally-level dynamics, enabling realistic and interpretable agent-opponent interactions without relying on physics-based simulation. In this demonstration, we showcase multiple trained agents within ShuttleEnv and provide live, step-by-step visualization of badminton rallies, allowing attendees to explore different play styles, observe emergent strategies, and interactively analyze decision-making behaviors. ShuttleEnv serves as a reusable platform for research, visualization, and demonstration of intelligent agents in sports AI. Our ShuttleEnv demo video URL: https://drive.google.com/file/d/1hTR4P16U27H2O0-w316bR73pxE2ucczX/view
Exact and Asymptotically Complete Robust Verifications of Neural Networks via Quantum Optimization
Feb 28, 2026Deep neural networks (DNNs) enable high performance across domains but remain vulnerable to adversarial perturbations, limiting their use in safety-critical settings. Here, we introduce two quantum-optimization-based models for robust verification that reduce the combinatorial burden of certification under bounded input perturbations. For piecewise-linear activations (e.g., ReLU and hardtanh), our first model yields an exact formulation that is sound and complete, enabling precise identification of adversarial examples. For general activations (including sigmoid and tanh), our second model constructs scalable over-approximations via piecewise-constant bounds and is asymptotically complete, with approximation error vanishing as the segmentation is refined. We further integrate Quantum Benders Decomposition with interval arithmetic to accelerate solving, and propose certificate-transfer bounds that relate robustness guarantees of pruned networks to those of the original model. Finally, a layerwise partitioning strategy supports a quantum--classical hybrid workflow by coupling subproblems across depth. Experiments on robustness benchmarks show high certification accuracy, indicating that quantum optimization can serve as a principled primitive for robustness guarantees in neural networks with complex activations.
Pareto-guided Pipeline for Distilling Featherweight AI Agents in Mobile MOBA Games
Feb 07, 2026Recent advances in game AI have demonstrated the feasibility of training agents that surpass top-tier human professionals in complex environments such as Honor of Kings (HoK), a leading mobile multiplayer online battle arena (MOBA) game. However, deploying such powerful agents on mobile devices remains a major challenge. On one hand, the intricate multi-modal state representation and hierarchical action space of HoK demand large, sophisticated policy networks that are inherently difficult to compress into lightweight forms. On the other hand, production deployment requires high-frequency inference under strict energy and latency constraints on mobile platform. To the best of our knowledge, bridging large-scale game AI and practical on-device deployment has not been systematically studied. In this work, we propose a Pareto optimality guided pipeline and design a high-efficiency student architecture search space tailored for mobile execution, enabling systematic exploration of the trade-off between performance and efficiency. Experimental results demonstrate that the distilled model achieves remarkable efficiency, including an $12.4\times$ faster inference speed (under 0.5ms per frame) and a $15.6\times$ improvement in energy efficiency (under 0.5mAh per game), while retaining a 40.32% win rate against the original teacher model.
Decoupling Return-to-Go for Efficient Decision Transformer
Jan 22, 2026The Decision Transformer (DT) has established a powerful sequence modeling approach to offline reinforcement learning. It conditions its action predictions on Return-to-Go (RTG), using it both to distinguish trajectory quality during training and to guide action generation at inference. In this work, we identify a critical redundancy in this design: feeding the entire sequence of RTGs into the Transformer is theoretically unnecessary, as only the most recent RTG affects action prediction. We show that this redundancy can impair DT's performance through experiments. To resolve this, we propose the Decoupled DT (DDT). DDT simplifies the architecture by processing only observation and action sequences through the Transformer, using the latest RTG to guide the action prediction. This streamlined approach not only improves performance but also reduces computational cost. Our experiments show that DDT significantly outperforms DT and establishes competitive performance against state-of-the-art DT variants across multiple offline RL tasks.
Adapting Rules of Official International Mahjong for Online Players
Jan 13, 2026As one of the worldwide spread traditional game, Official International Mahjong can be played and promoted online through remote devices instead of requiring face-to-face interaction. However, online players have fragmented playtime and unfixed combination of opponents in contrary to offline players who have fixed opponents for multiple rounds of play. Therefore, the rules designed for offline players need to be modified to ensure the fairness of online single-round play. Specifically, We employ a world champion AI to engage in self-play competitions and conduct statistical data analysis. Our study reveals the first-mover advantage and issues in the subgoal scoring settings. Based on our findings, we propose rule adaptations to make the game more suitable for the online environment, such as introducing compensatory points for the first-mover advantage and refining the scores of subgoals for different tile patterns. Compared with the traditional method of rotating positions over multiple rounds to balance first-mover advantage, our compensatory points mechanism in each round is more convenient for online players. Furthermore, we implement the revised Mahjong game online, which is open for online players. This work is an initial attempt to use data from AI systems to evaluate Official Internatinoal Mahjong's game balance and develop a revised version of the traditional game better adapted for online players.
Mosaic: Unlocking Long-Context Inference for Diffusion LLMs via Global Memory Planning and Dynamic Peak Taming
Jan 10, 2026Diffusion-based large language models (dLLMs) have emerged as a promising paradigm, utilizing simultaneous denoising to enable global planning and iterative refinement. While these capabilities are particularly advantageous for long-context generation, deploying such models faces a prohibitive memory capacity barrier stemming from severe system inefficiencies. We identify that existing inference systems are ill-suited for this paradigm: unlike autoregressive models constrained by the cumulative KV-cache, dLLMs are bottlenecked by transient activations recomputed at every step. Furthermore, general-purpose memory reuse mechanisms lack the global visibility to adapt to dLLMs' dynamic memory peaks, which toggle between logits and FFNs. To address these mismatches, we propose Mosaic, a memory-efficient inference system that shifts from local, static management to a global, dynamic paradigm. Mosaic integrates a mask-only logits kernel to eliminate redundancy, a lazy chunking optimizer driven by an online heuristic search to adaptively mitigate dynamic peaks, and a global memory manager to resolve fragmentation via virtual addressing. Extensive evaluations demonstrate that Mosaic achieves an average 2.71$\times$ reduction in the memory peak-to-average ratio and increases the maximum inference sequence length supportable on identical hardware by 15.89-32.98$\times$. This scalability is achieved without compromising accuracy and speed, and in fact reducing latency by 4.12%-23.26%.
HLSMAC: A New StarCraft Multi-Agent Challenge for High-Level Strategic Decision-Making
Sep 16, 2025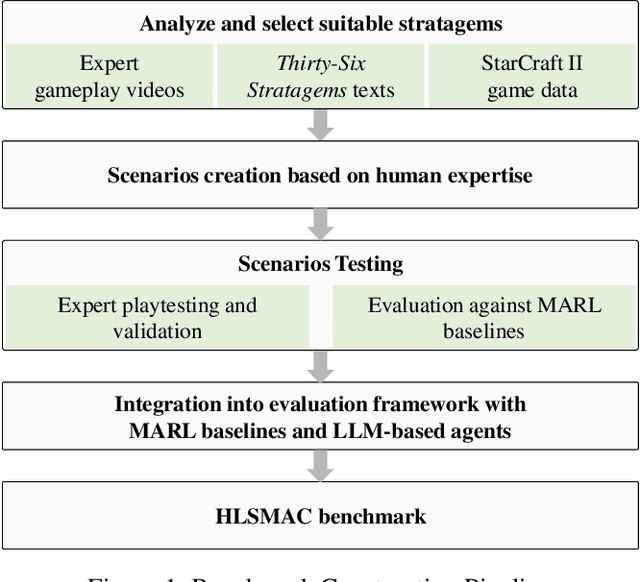
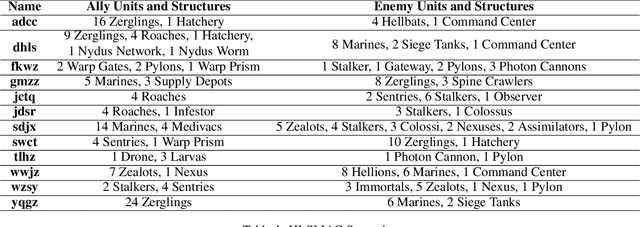

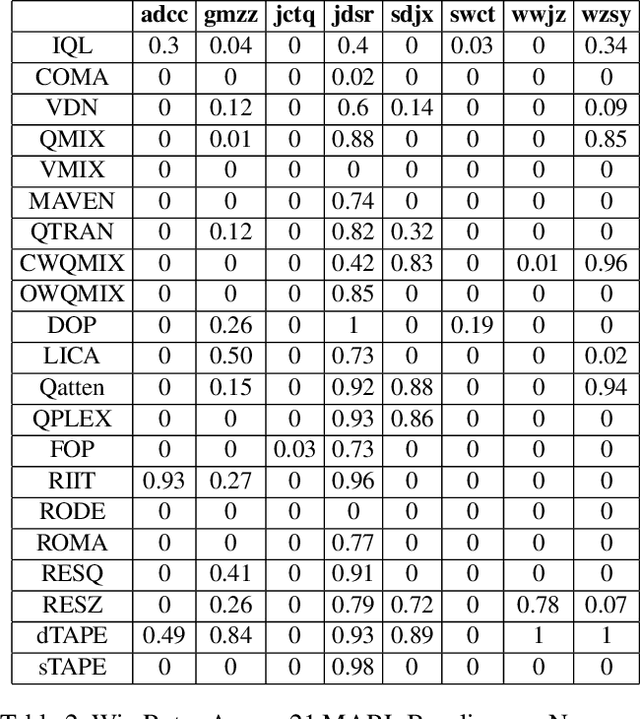
Benchmarks are crucial for assessing multi-agent reinforcement learning (MARL) algorithms. While StarCraft II-related environments have driven significant advances in MARL, existing benchmarks like SMAC focus primarily on micromanagement, limiting comprehensive evaluation of high-level strategic intelligence. To address this, we introduce HLSMAC, a new cooperative MARL benchmark with 12 carefully designed StarCraft II scenarios based on classical stratagems from the Thirty-Six Stratagems. Each scenario corresponds to a specific stratagem and is designed to challenge agents with diverse strategic elements, including tactical maneuvering, timing coordination, and deception, thereby opening up avenues for evaluating high-level strategic decision-making capabilities. We also propose novel metrics across multiple dimensions beyond conventional win rate, such as ability utilization and advancement efficiency, to assess agents' overall performance within the HLSMAC environment. We integrate state-of-the-art MARL algorithms and LLM-based agents with our benchmark and conduct comprehensive experiments. The results demonstrate that HLSMAC serves as a robust testbed for advancing multi-agent strategic decision-making.
Mxplainer: Explain and Learn Insights by Imitating Mahjong Agents
Jun 17, 2025People need to internalize the skills of AI agents to improve their own capabilities. Our paper focuses on Mahjong, a multiplayer game involving imperfect information and requiring effective long-term decision-making amidst randomness and hidden information. Through the efforts of AI researchers, several impressive Mahjong AI agents have already achieved performance levels comparable to those of professional human players; however, these agents are often treated as black boxes from which few insights can be gleaned. This paper introduces Mxplainer, a parameterized search algorithm that can be converted into an equivalent neural network to learn the parameters of black-box agents. Experiments conducted on AI and human player data demonstrate that the learned parameters provide human-understandable insights into these agents' characteristics and play styles. In addition to analyzing the learned parameters, we also showcase how our search-based framework can locally explain the decision-making processes of black-box agents for most Mahjong game states.