 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Navigation in Constrained Pedestrian Environments using Reinforcement Learning
Oct 16, 2020
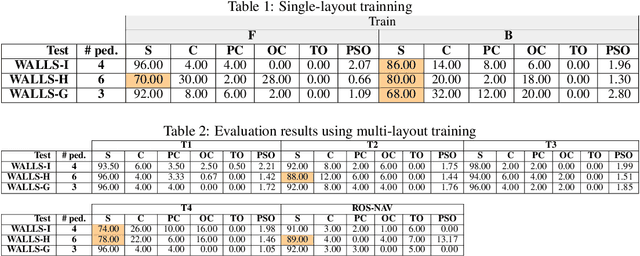
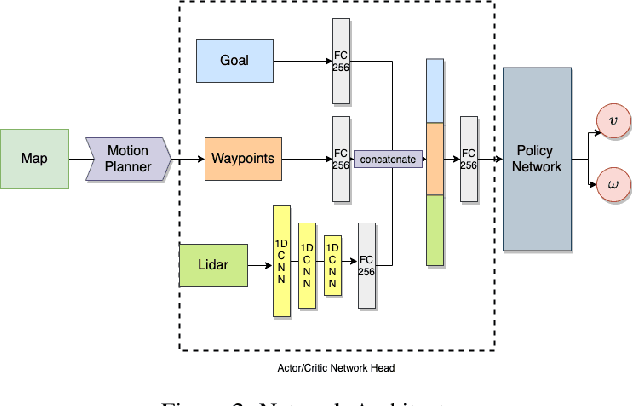
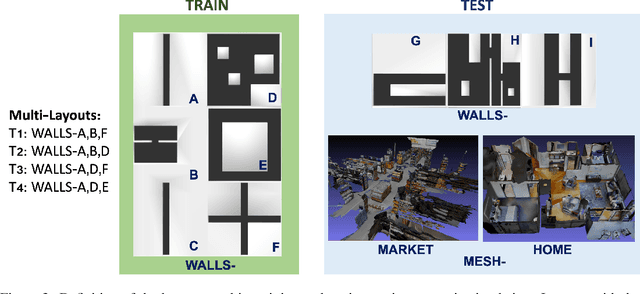
Navigating fluently around pedestrians is a necessary capability for mobile robots deployed in human environments, such as office buildings and homes. While related literature has addressed the co-navigation problem focused on the scalability with the number of pedestrians in open spaces, typical indoor environments present the additional challenge of constrained spaces such as corridors, doorways and crosswalks that limit maneuverability and influence patterns of pedestrian interaction. We present an approach based on reinforcement learning to learn policies capable of dynamic adaptation to the presence of moving pedestrians while navigating between desired locations in constrained environments. The policy network receives guidance from a motion planner that provides waypoints to follow a globally planned trajectory, whereas the reinforcement component handles the local interactions. We explore a compositional principle for multi-layout training and find that policies trained in a small set of geometrically simple layouts successfully generalize to unseen and more complex layouts that exhibit composition of the simple structural elements available during training. Going beyond wall-world like domains, we show transfer of the learned policy to unseen 3D reconstructions of two real environments (market, home). These results support the applicability of the compositional principle to real-world environments and indicate promising usage of agent simulation within reconstructed environments for tasks that involve interaction.
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020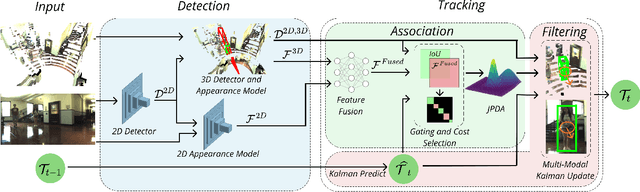
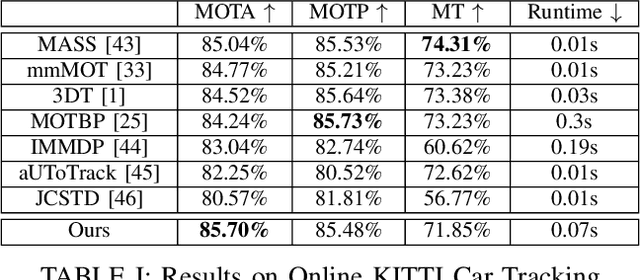
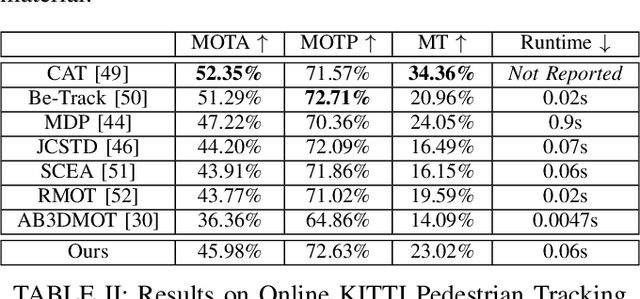
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
JRDB: A Dataset and Benchmark for Visual Perception for Navigation in Human Environments
Oct 25, 2019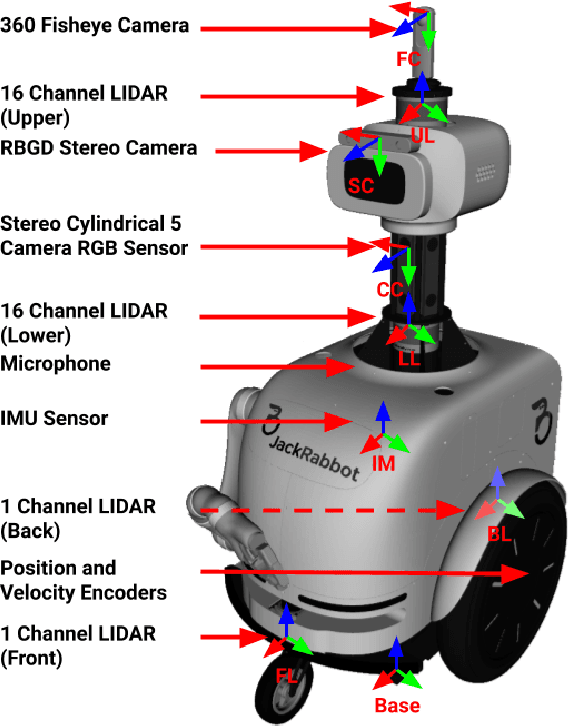
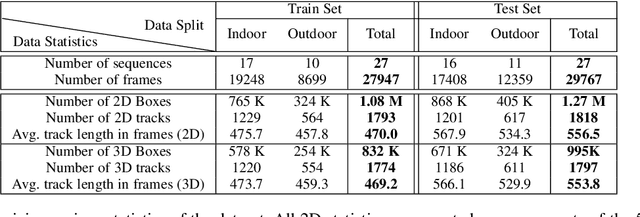
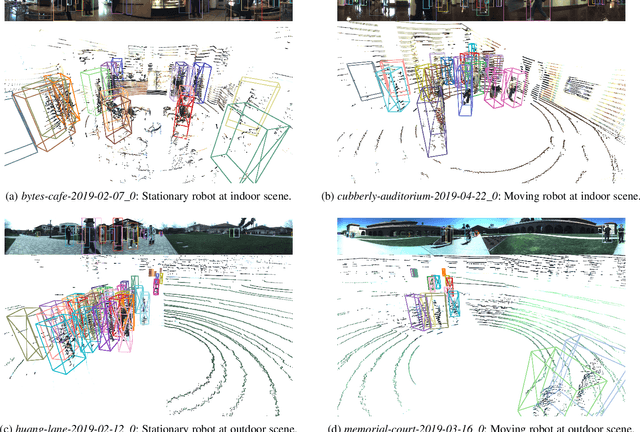
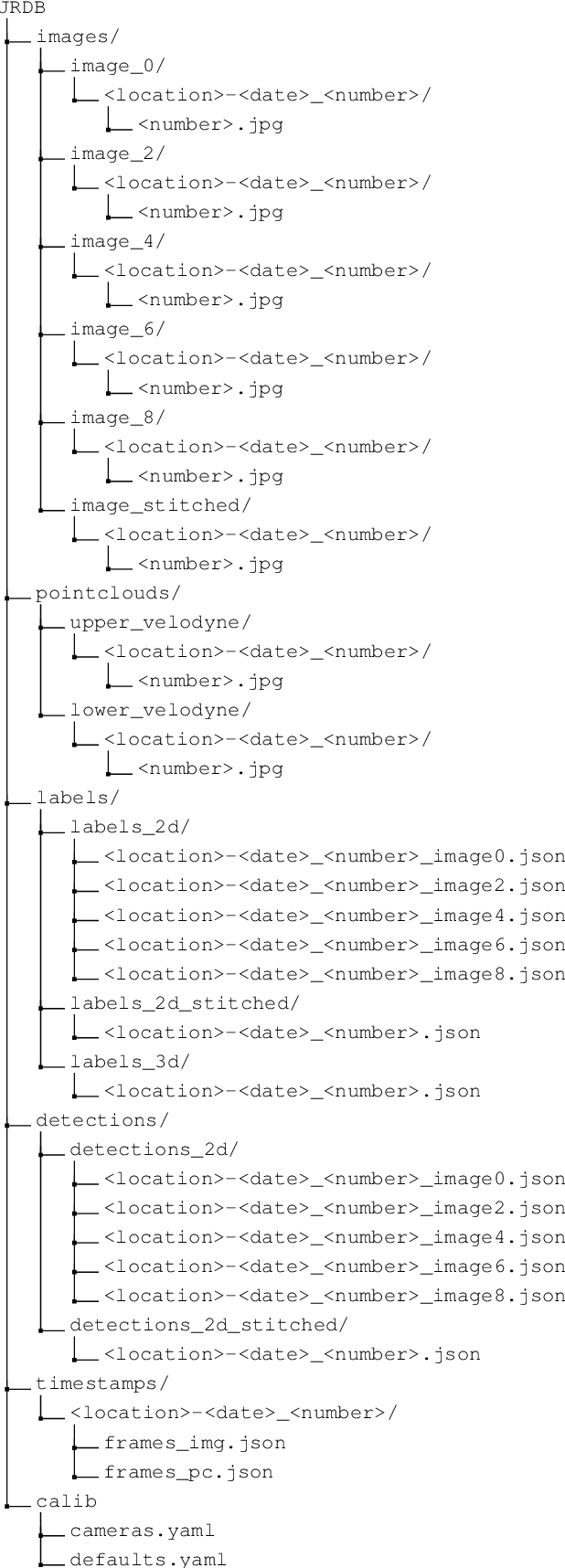
We present JRDB, a novel dataset collected from our social mobile manipulator JackRabbot. The dataset includes 64 minutes of multimodal sensor data including stereo cylindrical 360$^\circ$ RGB video at 15 fps, 3D point clouds from two Velodyne 16 Lidars, line 3D point clouds from two Sick Lidars, audio signal, RGBD video at 30 fps, 360$^\circ$ spherical image from a fisheye camera and encoder values from the robot's wheels. Our dataset includes data from traditionally underrepresented scenes such as indoor environments and pedestrian areas, from both stationary and navigating robot platform. The dataset has been annotated with over 2.3 million bounding boxes spread over 5 individual cameras and 1.8 million associated 3D cuboids around all people in the scenes totalling over 3500 time consistent trajectories. Together with our dataset and the annotations, we launch a benchmark and metrics for 2D and 3D person detection and tracking. With this dataset, that we plan on further annotating in the future, we hope to provide a new source of data and a test-bench for research in the areas of robot autonomous navigation and all perceptual tasks around social robotics in human environments.
Deep Local Trajectory Replanning and Control for Robot Navigation
May 13, 2019
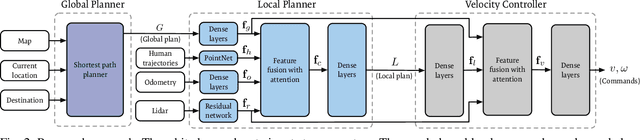
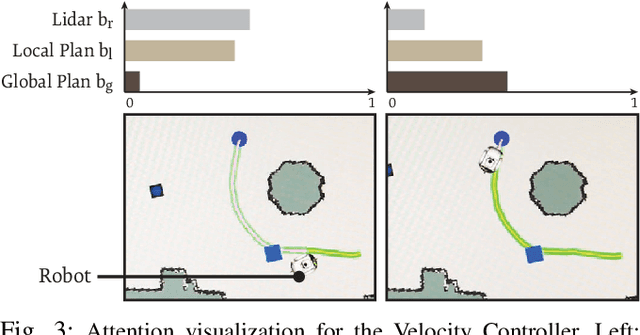
We present a navigation system that combines ideas from hierarchical planning and machine learning. The system uses a traditional global planner to compute optimal paths towards a goal, and a deep local trajectory planner and velocity controller to compute motion commands. The latter components of the system adjust the behavior of the robot through attention mechanisms such that it moves towards the goal, avoids obstacles, and respects the space of nearby pedestrians. Both the structure of the proposed deep models and the use of attention mechanisms make the system's execution interpretable. Our simulation experiments suggest that the proposed architecture outperforms baselines that try to map global plan information and sensor data directly to velocity commands. In comparison to a hand-designed traditional navigation system, the proposed approach showed more consistent performance.
GONet: A Semi-Supervised Deep Learning Approach For Traversability Estimation
Mar 08, 2018
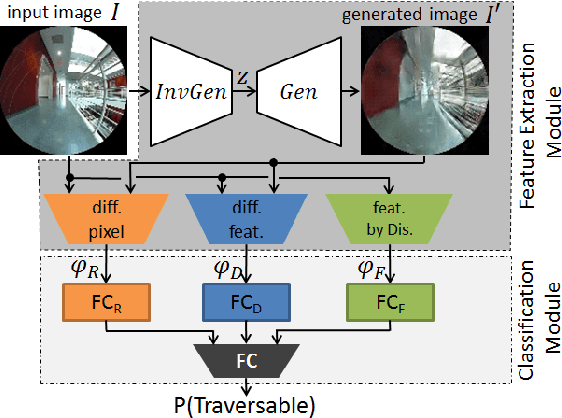
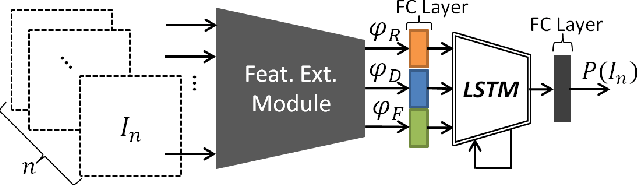

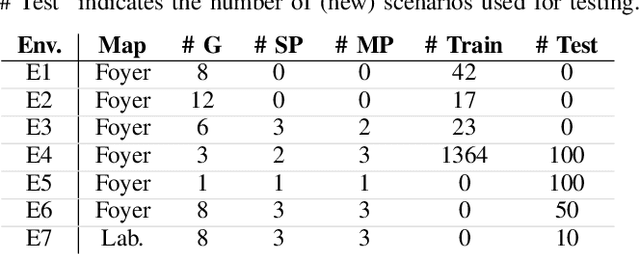
We present semi-supervised deep learning approaches for traversability estimation from fisheye images. Our method, GONet, and the proposed extensions leverage Generative Adversarial Networks (GANs) to effectively predict whether the area seen in the input image(s) is safe for a robot to traverse. These methods are trained with many positive images of traversable places, but just a small set of negative images depicting blocked and unsafe areas. This makes the proposed methods practical. Positive examples can be collected easily by simply operating a robot through traversable spaces, while obtaining negative examples is time consuming, costly, and potentially dangerous. Through extensive experiments and several demonstrations, we show that the proposed traversability estimation approaches are robust and can generalize to unseen scenarios. Further, we demonstrate that our methods are memory efficient and fast, allowing for real-time operation on a mobile robot with single or stereo fisheye cameras. As part of our contributions, we open-source two new datasets for traversability estimation. These datasets are composed of approximately 24h of videos from more than 25 indoor environments. Our methods outperform baseline approaches for traversability estimation on these new datasets.
To Go or Not To Go? A Near Unsupervised Learning Approach For Robot Navigation
Sep 16, 2017



It is important for robots to be able to decide whether they can go through a space or not, as they navigate through a dynamic environment. This capability can help them avoid injury or serious damage, e.g., as a result of running into people and obstacles, getting stuck, or falling off an edge. To this end, we propose an unsupervised and a near-unsupervised method based on Generative Adversarial Networks (GAN) to classify scenarios as traversable or not based on visual data. Our method is inspired by the recent success of data-driven approaches on computer vision problems and anomaly detection, and reduces the need for vast amounts of negative examples at training time. Collecting negative data indicating that a robot should not go through a space is typically hard and dangerous because of collisions, whereas collecting positive data can be automated and done safely based on the robot's own traveling experience. We verify the generality and effectiveness of the proposed approach on a test dataset collected in a previously unseen environment with a mobile robot. Furthermore, we show that our method can be used to build costmaps (we call as "GoNoGo" costmaps) for robot path planning using visual data only.