 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Drive Anywhere with Model-Based Reannotation11
May 08, 2025Developing broadly generalizable visual navigation policies for robots is a significant challenge, primarily constrained by the availability of large-scale, diverse training data. While curated datasets collected by researchers offer high quality, their limited size restricts policy generalization. To overcome this, we explore leveraging abundant, passively collected data sources, including large volumes of crowd-sourced teleoperation data and unlabeled YouTube videos, despite their potential for lower quality or missing action labels. We propose Model-Based ReAnnotation (MBRA), a framework that utilizes a learned short-horizon, model-based expert model to relabel or generate high-quality actions for these passive datasets. This relabeled data is then distilled into LogoNav, a long-horizon navigation policy conditioned on visual goals or GPS waypoints. We demonstrate that LogoNav, trained using MBRA-processed data, achieves state-of-the-art performance, enabling robust navigation over distances exceeding 300 meters in previously unseen indoor and outdoor environments. Our extensive real-world evaluations, conducted across a fleet of robots (including quadrupeds) in six cities on three continents, validate the policy's ability to generalize and navigate effectively even amidst pedestrians in crowded settings.
LeLaN: Learning A Language-Conditioned Navigation Policy from In-the-Wild Videos
Oct 04, 2024The world is filled with a wide variety of objects. For robots to be useful, they need the ability to find arbitrary objects described by people. In this paper, we present LeLaN(Learning Language-conditioned Navigation policy), a novel approach that consumes unlabeled, action-free egocentric data to learn scalable, language-conditioned object navigation. Our framework, LeLaN leverages the semantic knowledge of large vision-language models, as well as robotic foundation models, to label in-the-wild data from a variety of indoor and outdoor environments. We label over 130 hours of data collected in real-world indoor and outdoor environments, including robot observations, YouTube video tours, and human walking data. Extensive experiments with over 1000 real-world trials show that our approach enables training a policy from unlabeled action-free videos that outperforms state-of-the-art robot navigation methods, while being capable of inference at 4 times their speed on edge compute. We open-source our models, datasets and provide supplementary videos on our project page (https://learning-language-navigation.github.io/).
SELFI: Autonomous Self-Improvement with Reinforcement Learning for Social Navigation
Mar 01, 2024Autonomous self-improving robots that interact and improve with experience are key to the real-world deployment of robotic systems. In this paper, we propose an online learning method, SELFI, that leverages online robot experience to rapidly fine-tune pre-trained control policies efficiently. SELFI applies online model-free reinforcement learning on top of offline model-based learning to bring out the best parts of both learning paradigms. Specifically, SELFI stabilizes the online learning process by incorporating the same model-based learning objective from offline pre-training into the Q-values learned with online model-free reinforcement learning. We evaluate SELFI in multiple real-world environments and report improvements in terms of collision avoidance, as well as more socially compliant behavior, measured by a human user study. SELFI enables us to quickly learn useful robotic behaviors with less human interventions such as pre-emptive behavior for the pedestrians, collision avoidance for small and transparent objects, and avoiding travel on uneven floor surfaces. We provide supplementary videos to demonstrate the performance of our fine-tuned policy on our project page.
ViNT: A Foundation Model for Visual Navigation
Jun 26, 2023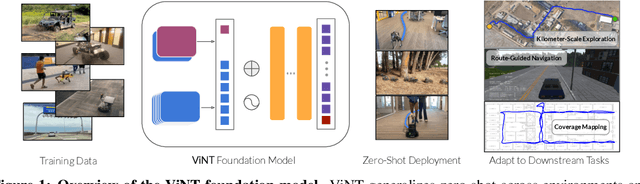
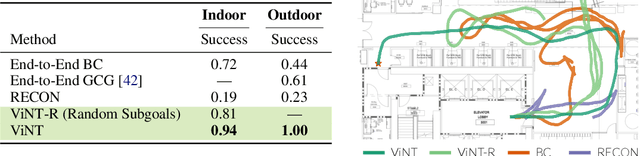
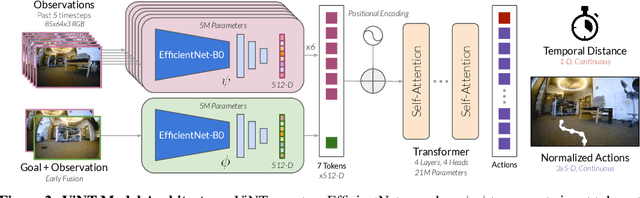

General-purpose pre-trained models ("foundation models") have enabled practitioners to produce generalizable solutions for individual machine learning problems with datasets that are significantly smaller than those required for learning from scratch. Such models are typically trained on large and diverse datasets with weak supervision, consuming much more training data than is available for any individual downstream application. In this paper, we describe the Visual Navigation Transformer (ViNT), a foundation model that aims to bring the success of general-purpose pre-trained models to vision-based robotic navigation. ViNT is trained with a general goal-reaching objective that can be used with any navigation dataset, and employs a flexible Transformer-based architecture to learn navigational affordances and enable efficient adaptation to a variety of downstream navigational tasks. ViNT is trained on a number of existing navigation datasets, comprising hundreds of hours of robotic navigation from a variety of different robotic platforms, and exhibits positive transfer, outperforming specialist models trained on singular datasets. ViNT can be augmented with diffusion-based subgoal proposals to explore novel environments, and can solve kilometer-scale navigation problems when equipped with long-range heuristics. ViNT can also be adapted to novel task specifications with a technique inspired by prompt-tuning, where the goal encoder is replaced by an encoding of another task modality (e.g., GPS waypoints or routing commands) embedded into the same space of goal tokens. This flexibility and ability to accommodate a variety of downstream problem domains establishes ViNT as an effective foundation model for mobile robotics. For videos, code, and model checkpoints, see our project page at https://visualnav-transformer.github.io.
SACSoN: Scalable Autonomous Data Collection for Social Navigation
Jun 02, 2023Machine learning provides a powerful tool for building socially compliant robotic systems that go beyond simple predictive models of human behavior. By observing and understanding human interactions from past experiences, learning can enable effective social navigation behaviors directly from data. However, collecting navigation data in human-occupied environments may require teleoperation or continuous monitoring, making the process prohibitively expensive to scale. In this paper, we present a scalable data collection system for vision-based navigation, SACSoN, that can autonomously navigate around pedestrians in challenging real-world environments while encouraging rich interactions. SACSoN uses visual observations to observe and react to humans in its vicinity. It couples this visual understanding with continual learning and an autonomous collision recovery system that limits the involvement of a human operator, allowing for better dataset scaling. We use a this system to collect the SACSoN dataset, the largest-of-its-kind visual navigation dataset of autonomous robots operating in human-occupied spaces, spanning over 75 hours and 4000 rich interactions with humans. Our experiments show that collecting data with a novel objective that encourages interactions, leads to significant improvements in downstream tasks such as inferring pedestrian dynamics and learning socially compliant navigation behaviors. We make videos of our autonomous data collection system and the SACSoN dataset publicly available on our project page.
ExAug: Robot-Conditioned Navigation Policies via Geometric Experience Augmentation
Oct 14, 2022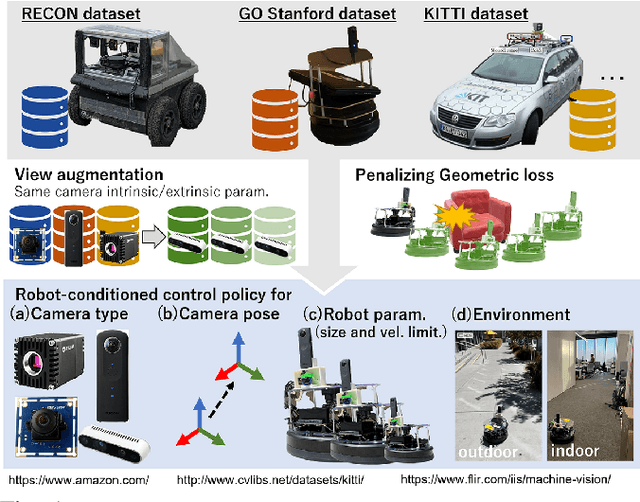
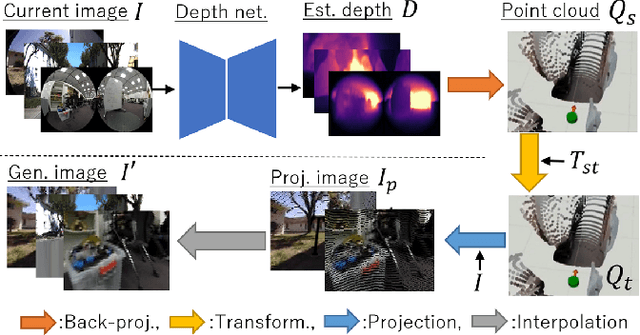

Machine learning techniques rely on large and diverse datasets for generalization. Computer vision, natural language processing, and other applications can often reuse public datasets to train many different models. However, due to differences in physical configurations, it is challenging to leverage public datasets for training robotic control policies on new robot platforms or for new tasks. In this work, we propose a novel framework, ExAug to augment the experiences of different robot platforms from multiple datasets in diverse environments. ExAug leverages a simple principle: by extracting 3D information in the form of a point cloud, we can create much more complex and structured augmentations, utilizing both generating synthetic images and geometric-aware penalization that would have been suitable in the same situation for a different robot, with different size, turning radius, and camera placement. The trained policy is evaluated on two new robot platforms with three different cameras in indoor and outdoor environments with obstacles.
GNM: A General Navigation Model to Drive Any Robot
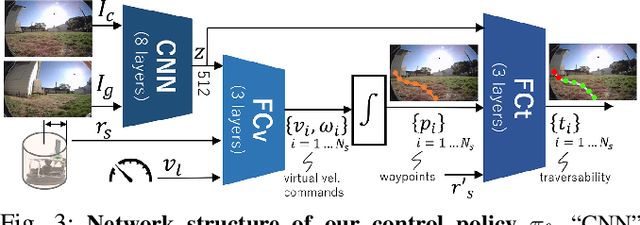
Oct 07, 2022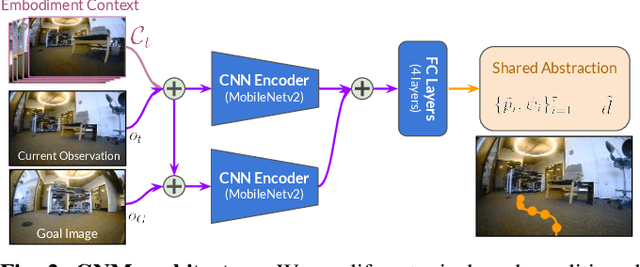

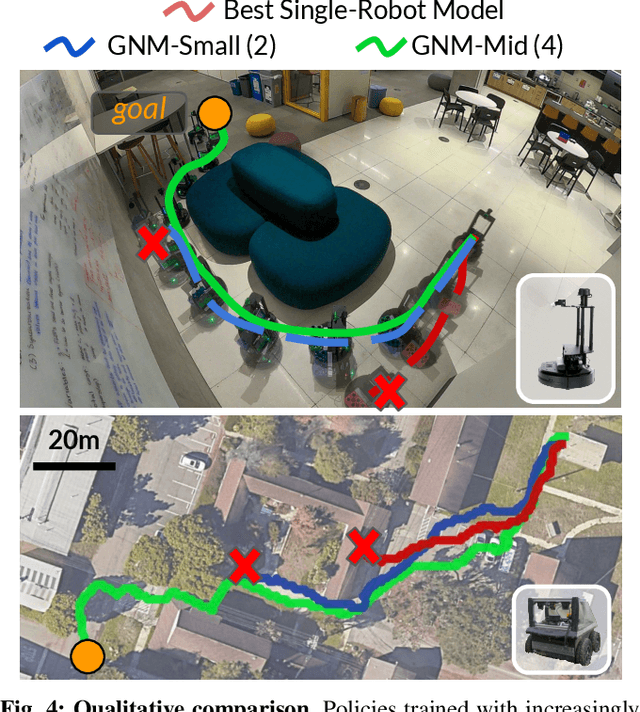
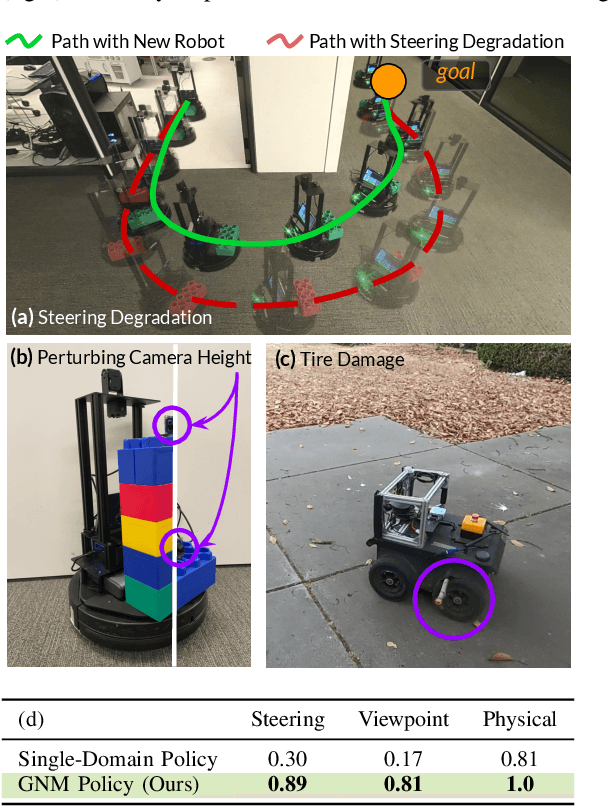
Learning provides a powerful tool for vision-based navigation, but the capabilities of learning-based policies are constrained by limited training data. If we could combine data from all available sources, including multiple kinds of robots, we could train more powerful navigation models. In this paper, we study how a general goal-conditioned model for vision-based navigation can be trained on data obtained from many distinct but structurally similar robots, and enable broad generalization across environments and embodiments. We analyze the necessary design decisions for effective data sharing across robots, including the use of temporal context and standardized action spaces, and demonstrate that an omnipolicy trained from heterogeneous datasets outperforms policies trained on any single dataset. We curate 60 hours of navigation trajectories from 6 distinct robots, and deploy the trained GNM on a range of new robots, including an underactuated quadrotor. We find that training on diverse data leads to robustness against degradation in sensing and actuation. Using a pre-trained navigation model with broad generalization capabilities can bootstrap applications on novel robots going forward, and we hope that the GNM represents a step in that direction. For more information on the datasets, code, and videos, please check out http://sites.google.com/view/drive-any-robot.
Spatio-Temporal Graph Localization Networks for Image-based Navigation
Apr 28, 2022
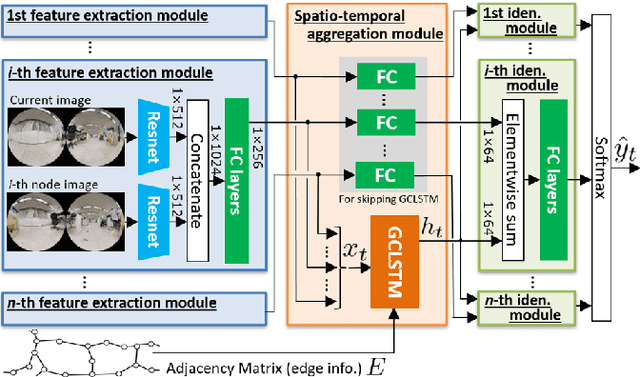

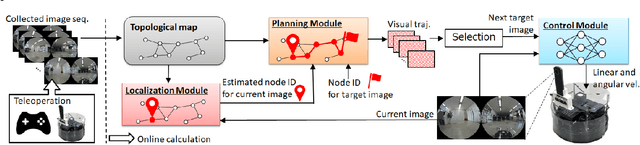
Localization in topological maps is essential for image-based navigation using an RGB camera. Localization using only one camera can be challenging in medium-to-large-sized environments because similar-looking images are often observed repeatedly, especially in indoor environments. To overcome this issue, we propose a learning-based localization method that simultaneously utilizes the spatial consistency from topological maps and the temporal consistency from time-series images captured by the robot. Our method combines a convolutional neural network (CNN) to embed image features and a recurrent-type graph neural network to perform accurate localization. When training our model, it is difficult to obtain the ground truth pose of the robot when capturing images in real-world environments. Hence, we propose a sim2real transfer approach with semi-supervised learning that leverages simulator images with the ground truth pose in addition to real images. We evaluated our method quantitatively and qualitatively and compared it with several state-of-the-art baselines. The proposed method outperformed the baselines in environments where the map contained similar images. Moreover, we evaluated an image-based navigation system incorporating our localization method and confirmed that navigation accuracy significantly improved in the simulator and real environments when compared with the other baseline methods.
Unsupervised Simultaneous Learning for Camera Re-Localization and Depth Estimation from Video
Mar 24, 2022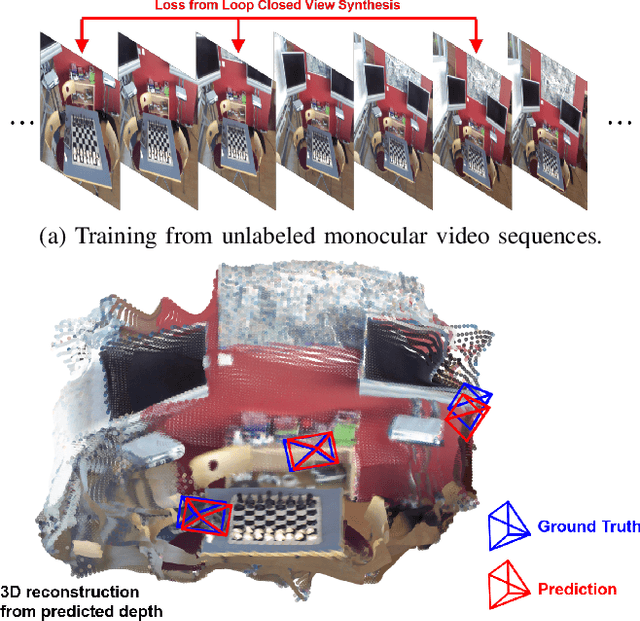
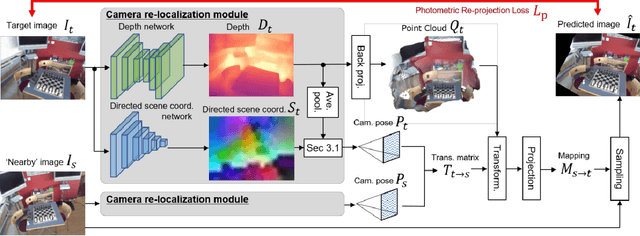
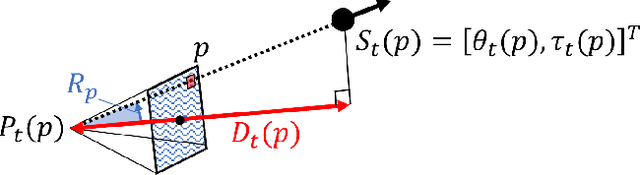
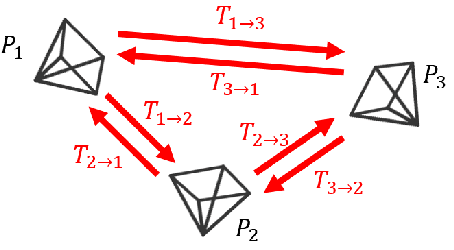
We present an unsupervised simultaneous learning framework for the task of monocular camera re-localization and depth estimation from unlabeled video sequences. Monocular camera re-localization refers to the task of estimating the absolute camera pose from an instance image in a known environment, which has been intensively studied for alternative localization in GPS-denied environments. In recent works, camera re-localization methods are trained via supervised learning from pairs of camera images and camera poses. In contrast to previous works, we propose a completely unsupervised learning framework for camera re-localization and depth estimation, requiring only monocular video sequences for training. In our framework, we train two networks that estimate the scene coordinates using directions and the depth map from each image which are then combined to estimate the camera pose. The networks can be trained through the minimization of loss functions based on our loop closed view synthesis. In experiments with the 7-scenes dataset, the proposed method outperformed the re-localization of the state-of-the-art visual SLAM, ORB-SLAM3. Our method also outperforms state-of-the-art monocular depth estimation in a trained environment.
Ex-DoF: Expansion of Action Degree-of-Freedom with Virtual Camera Rotation for Omnidirectional Image
Nov 24, 2021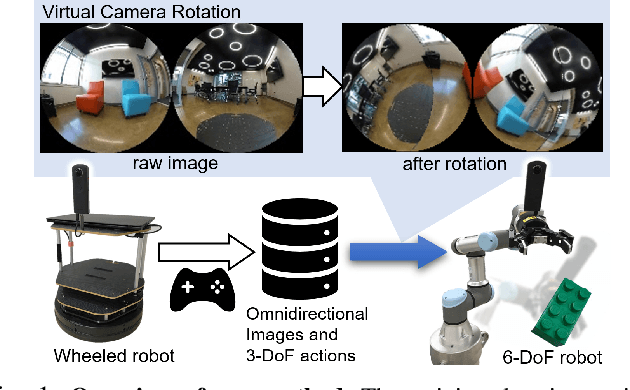
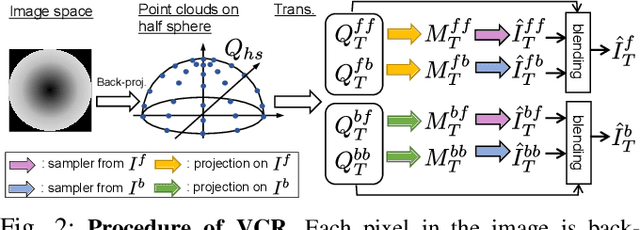
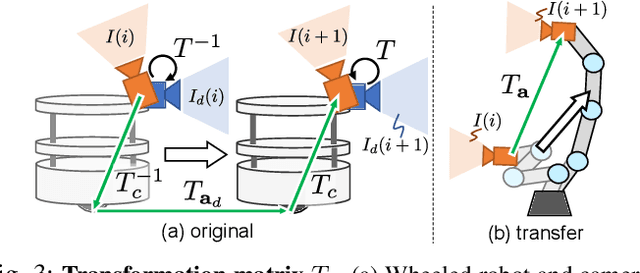
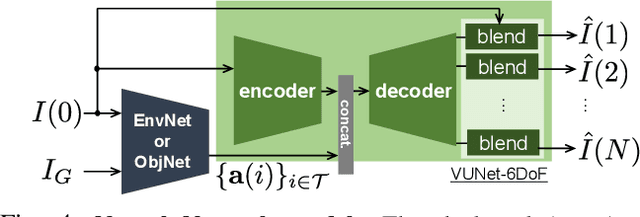
Inter-robot transfer of training data is a little explored topic in learning and vision-based robot control. Thus, we propose a transfer method from a robot with a lower Degree-of-Freedom (DoF) action to one with a higher DoF utilizing an omnidirectional camera. The virtual rotation of the robot camera enables data augmentation in this transfer learning process. In this study, a vision-based control policy for a 6-DoF robot was trained using a dataset collected by a differential wheeled ground robot with only three DoFs. Towards application of robotic manipulations, we also demonstrate a control system of a 6-DoF arm robot using multiple policies with different fields of view to enable object reaching tasks.