 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialPrompting: Keyframe-driven Zero-Shot Spatial Reasoning with Off-the-Shelf Multimodal Large Language Models
May 08, 2025



This study introduces SpatialPrompting, a novel framework that harnesses the emergent reasoning capabilities of off-the-shelf multimodal large language models to achieve zero-shot spatial reasoning in three-dimensional (3D) environments. Unlike existing methods that rely on expensive 3D-specific fine-tuning with specialized 3D inputs such as point clouds or voxel-based features, SpatialPrompting employs a keyframe-driven prompt generation strategy. This framework uses metrics such as vision-language similarity, Mahalanobis distance, field of view, and image sharpness to select a diverse and informative set of keyframes from image sequences and then integrates them with corresponding camera pose data to effectively abstract spatial relationships and infer complex 3D structures. The proposed framework not only establishes a new paradigm for flexible spatial reasoning that utilizes intuitive visual and positional cues but also achieves state-of-the-art zero-shot performance on benchmark datasets, such as ScanQA and SQA3D, across several metrics. The proposed method effectively eliminates the need for specialized 3D inputs and fine-tuning, offering a simpler and more scalable alternative to conventional approaches.
Online Embedding Multi-Scale CLIP Features into 3D Maps
Mar 27, 2024This study introduces a novel approach to online embedding of multi-scale CLIP (Contrastive Language-Image Pre-Training) features into 3D maps. By harnessing CLIP, this methodology surpasses the constraints of conventional vocabulary-limited methods and enables the incorporation of semantic information into the resultant maps. While recent approaches have explored the embedding of multi-modal features in maps, they often impose significant computational costs, lacking practicality for exploring unfamiliar environments in real time. Our approach tackles these challenges by efficiently computing and embedding multi-scale CLIP features, thereby facilitating the exploration of unfamiliar environments through real-time map generation. Moreover, the embedding CLIP features into the resultant maps makes offline retrieval via linguistic queries feasible. In essence, our approach simultaneously achieves real-time object search and mapping of unfamiliar environments. Additionally, we propose a zero-shot object-goal navigation system based on our mapping approach, and we validate its efficacy through object-goal navigation, offline object retrieval, and multi-object-goal navigation in both simulated environments and real robot experiments. The findings demonstrate that our method not only exhibits swifter performance than state-of-the-art mapping methods but also surpasses them in terms of the success rate of object-goal navigation tasks.
Language to Map: Topological map generation from natural language path instructions
Mar 15, 2024



In this paper, a method for generating a map from path information described using natural language (textual path) is proposed. In recent years, robotics research mainly focus on vision-and-language navigation (VLN), a navigation task based on images and textual paths. Although VLN is expected to facilitate user instructions to robots, its current implementation requires users to explain the details of the path for each navigation session, which results in high explanation costs for users. To solve this problem, we proposed a method that creates a map as a topological map from a textual path and automatically creates a new path using this map. We believe that large language models (LLMs) can be used to understand textual path. Therefore, we propose and evaluate two methods, one for storing implicit maps in LLMs, and the other for generating explicit maps using LLMs. The implicit map is in the LLM's memory. It is created using prompts. In the explicit map, a topological map composed of nodes and edges is constructed and the actions at each node are stored. This makes it possible to estimate the path and actions at waypoints on an undescribed path, if enough information is available. Experimental results on path instructions generated in a real environment demonstrate that generating explicit maps achieves significantly higher accuracy than storing implicit maps in the LLMs.
CLIP feature-based randomized control using images and text for multiple tasks and robots
Jan 18, 2024This study presents a control framework leveraging vision language models (VLMs) for multiple tasks and robots. Notably, existing control methods using VLMs have achieved high performance in various tasks and robots in the training environment. However, these methods incur high costs for learning control policies for tasks and robots other than those in the training environment. Considering the application of industrial and household robots, learning in novel environments where robots are introduced is challenging. To address this issue, we propose a control framework that does not require learning control policies. Our framework combines the vision-language CLIP model with a randomized control. CLIP computes the similarity between images and texts by embedding them in the feature space. This study employs CLIP to compute the similarity between camera images and text representing the target state. In our method, the robot is controlled by a randomized controller that simultaneously explores and increases the similarity gradients. Moreover, we fine-tune the CLIP to improve the performance of the proposed method. Consequently, we confirm the effectiveness of our approach through a multitask simulation and a real robot experiment using a two-wheeled robot and robot arm.
Spatio-Temporal Graph Localization Networks for Image-based Navigation
Apr 28, 2022
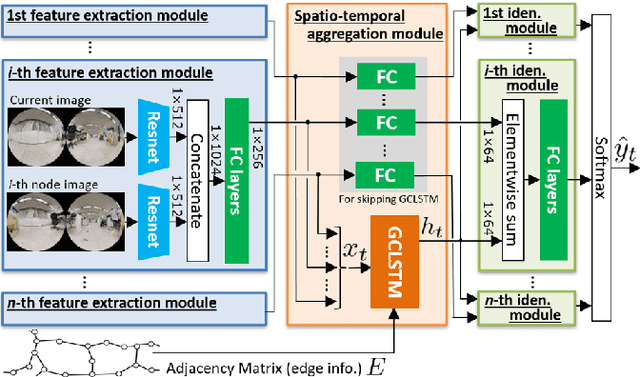

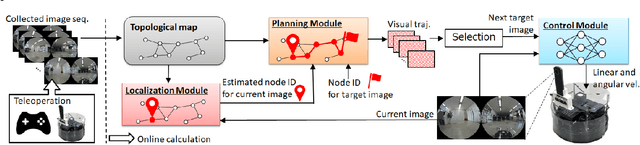
Localization in topological maps is essential for image-based navigation using an RGB camera. Localization using only one camera can be challenging in medium-to-large-sized environments because similar-looking images are often observed repeatedly, especially in indoor environments. To overcome this issue, we propose a learning-based localization method that simultaneously utilizes the spatial consistency from topological maps and the temporal consistency from time-series images captured by the robot. Our method combines a convolutional neural network (CNN) to embed image features and a recurrent-type graph neural network to perform accurate localization. When training our model, it is difficult to obtain the ground truth pose of the robot when capturing images in real-world environments. Hence, we propose a sim2real transfer approach with semi-supervised learning that leverages simulator images with the ground truth pose in addition to real images. We evaluated our method quantitatively and qualitatively and compared it with several state-of-the-art baselines. The proposed method outperformed the baselines in environments where the map contained similar images. Moreover, we evaluated an image-based navigation system incorporating our localization method and confirmed that navigation accuracy significantly improved in the simulator and real environments when compared with the other baseline methods.
Unsupervised Simultaneous Learning for Camera Re-Localization and Depth Estimation from Video
Mar 24, 2022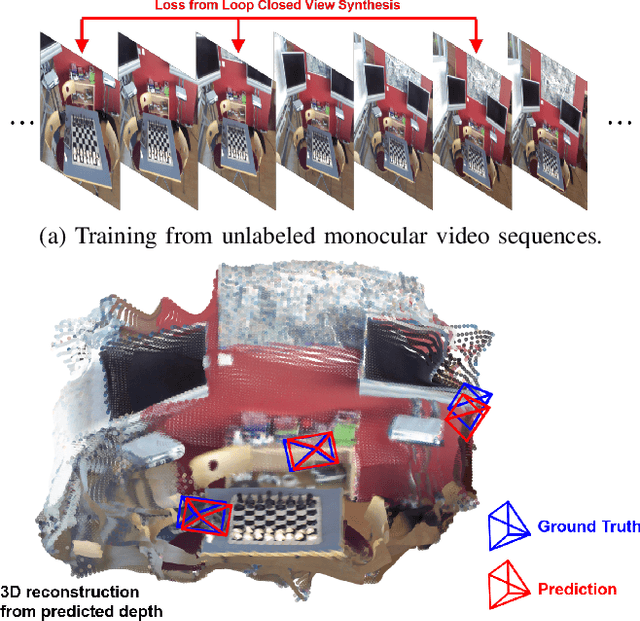
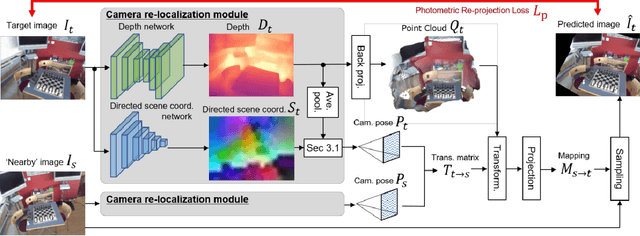
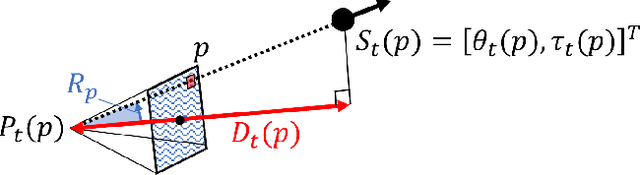
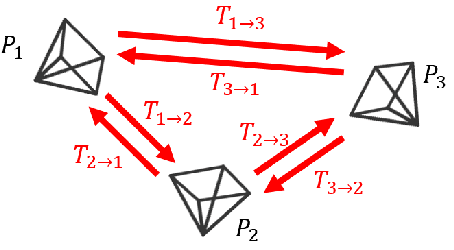
We present an unsupervised simultaneous learning framework for the task of monocular camera re-localization and depth estimation from unlabeled video sequences. Monocular camera re-localization refers to the task of estimating the absolute camera pose from an instance image in a known environment, which has been intensively studied for alternative localization in GPS-denied environments. In recent works, camera re-localization methods are trained via supervised learning from pairs of camera images and camera poses. In contrast to previous works, we propose a completely unsupervised learning framework for camera re-localization and depth estimation, requiring only monocular video sequences for training. In our framework, we train two networks that estimate the scene coordinates using directions and the depth map from each image which are then combined to estimate the camera pose. The networks can be trained through the minimization of loss functions based on our loop closed view synthesis. In experiments with the 7-scenes dataset, the proposed method outperformed the re-localization of the state-of-the-art visual SLAM, ORB-SLAM3. Our method also outperforms state-of-the-art monocular depth estimation in a trained environment.
Variational Monocular Depth Estimation for Reliability Prediction
Nov 24, 2020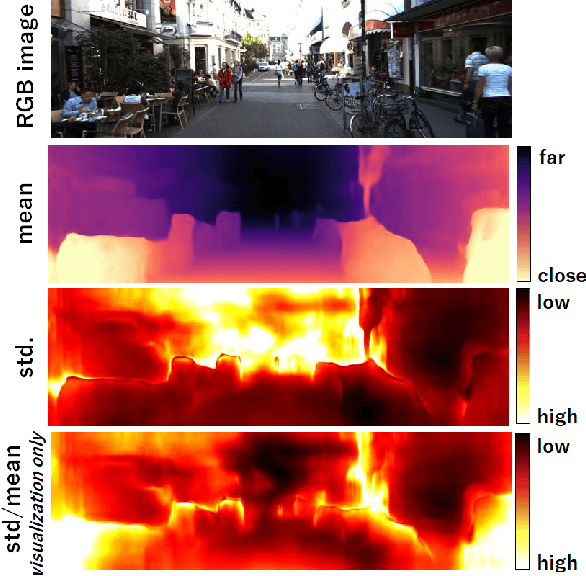
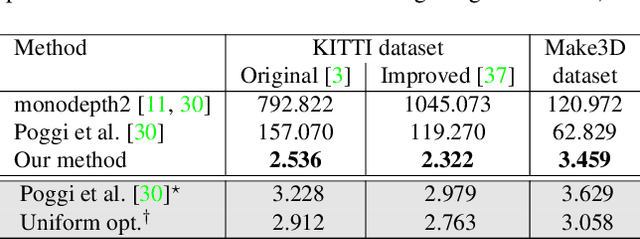
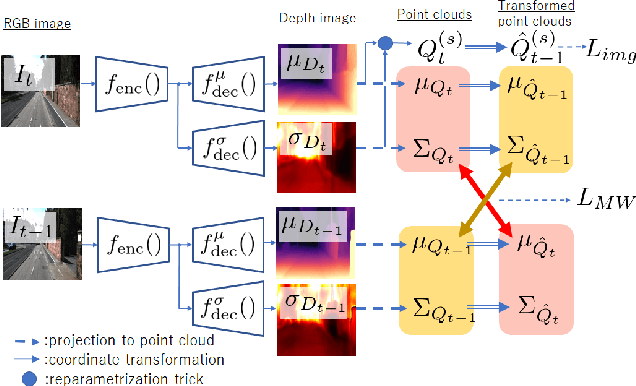

Self-supervised learning for monocular depth estimation is widely investigated as an alternative to supervised learning approach, that requires a lot of ground truths. Previous works have successfully improved the accuracy of depth estimation by modifying the model structure, adding objectives, and masking dynamic objects and occluded area. However, when using such estimated depth image in applications, such as autonomous vehicles, and robots, we have to uniformly believe the estimated depth at each pixel position. This could lead to fatal errors in performing the tasks, because estimated depth at some pixels may make a bigger mistake. In this paper, we theoretically formulate a variational model for the monocular depth estimation to predict the reliability of the estimated depth image. Based on the results, we can exclude the estimated depths with low reliability or refine them for actual use. The effectiveness of the proposed method is quantitatively and qualitatively demonstrated using the KITTI benchmark and Make3D dataset.
Probabilistic Visual Navigation with Bidirectional Image Prediction
Mar 20, 2020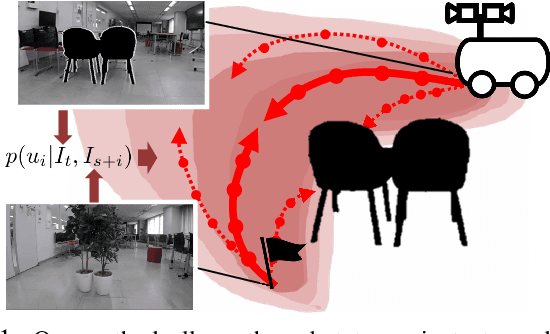
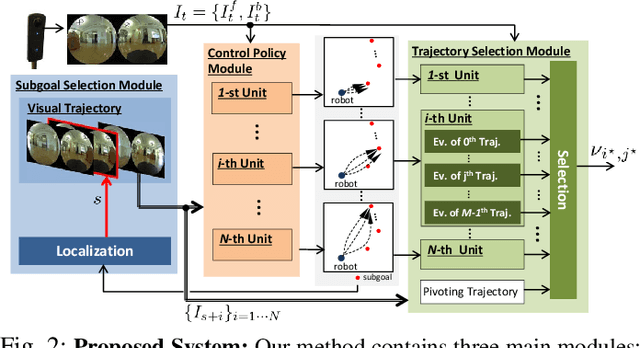
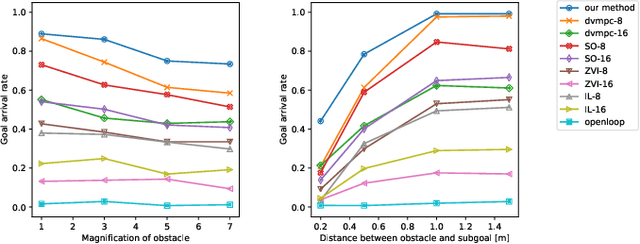
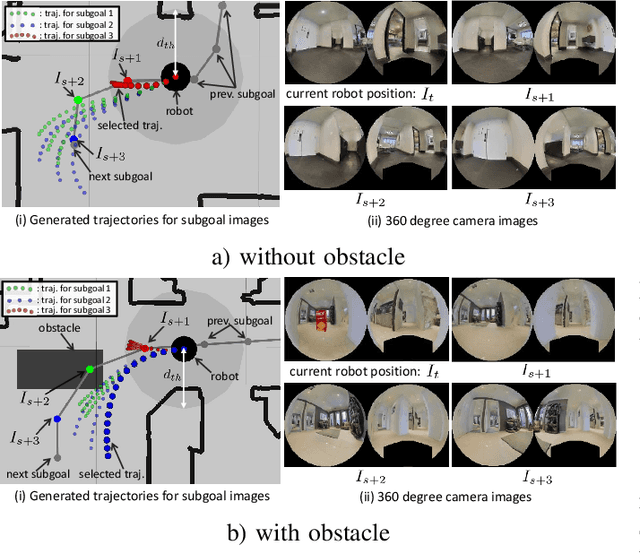
Humans can robustly follow a visual trajectory defined by a sequence of images (i.e. a video) regardless of substantial changes in the environment or the presence of obstacles. We aim at endowing similar visual navigation capabilities to mobile robots solely equipped with a RGB fisheye camera. We propose a novel probabilistic visual navigation system that learns to follow a sequence of images with bidirectional visual predictions conditioned on possible navigation velocities. By predicting bidirectionally (from start towards goal and vice versa) our method extends its predictive horizon enabling the robot to go around unseen large obstacles that are not visible in the video trajectory. Learning how to react to obstacles and potential risks in the visual field is achieved by imitating human teleoperators. Since the human teleoperation commands are diverse, we propose a probabilistic representation of trajectories that we can sample to find the safest path. Integrated into our navigation system, we present a novel localization approach that infers the current location of the robot based on the virtual predicted trajectories required to reach different images in the visual trajectory. We evaluate our navigation system quantitatively and qualitatively in multiple simulated and real environments and compare to state-of-the-art baselines.Our approach outperforms the most recent visual navigation methods with a large margin with regard to goal arrival rate, subgoal coverage rate, and success weighted by path length (SPL). Our method also generalizes to new robot embodiments never used during training.