 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIPP: Discriminative Impact Point Predictor for Catching Diverse In-Flight Objects
Sep 18, 2025
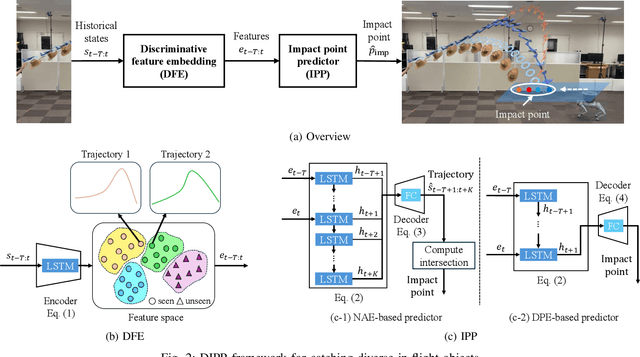

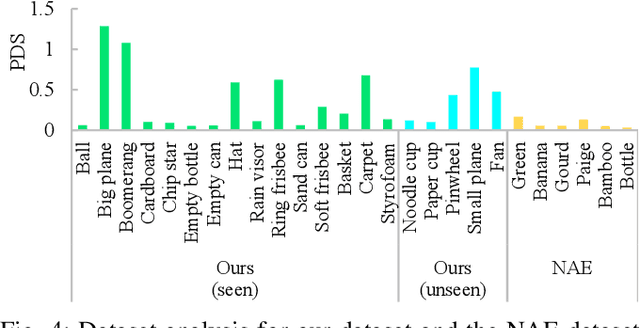
In this study, we address the problem of in-flight object catching using a quadruped robot with a basket. Our objective is to accurately predict the impact point, defined as the object's landing position. This task poses two key challenges: the absence of public datasets capturing diverse objects under unsteady aerodynamics, which are essential for training reliable predictors; and the difficulty of accurate early-stage impact point prediction when trajectories appear similar across objects. To overcome these issues, we construct a real-world dataset of 8,000 trajectories from 20 objects, providing a foundation for advancing in-flight object catching under complex aerodynamics. We then propose the Discriminative Impact Point Predictor (DIPP), consisting of two modules: (i) a Discriminative Feature Embedding (DFE) that separates trajectories by dynamics to enable early-stage discrimination and generalization, and (ii) an Impact Point Predictor (IPP) that estimates the impact point from these features. Two IPP variants are implemented: an Neural Acceleration Estimator (NAE)-based method that predicts trajectories and derives the impact point, and a Direct Point Estimator (DPE)-based method that directly outputs it. Experimental results show that our dataset is more diverse and complex than existing dataset, and that our method outperforms baselines on both 15 seen and 5 unseen objects. Furthermore, we show that improved early-stage prediction enhances catching success in simulation and demonstrate the effectiveness of our approach through real-world experiments. The demonstration is available at https://sites.google.com/view/robot-catching-2025.
ICCO: Learning an Instruction-conditioned Coordinator for Language-guided Task-aligned Multi-robot Control
Mar 15, 2025Recent advances in Large Language Models (LLMs) have permitted the development of language-guided multi-robot systems, which allow robots to execute tasks based on natural language instructions. However, achieving effective coordination in distributed multi-agent environments remains challenging due to (1) misalignment between instructions and task requirements and (2) inconsistency in robot behaviors when they independently interpret ambiguous instructions. To address these challenges, we propose Instruction-Conditioned Coordinator (ICCO), a Multi-Agent Reinforcement Learning (MARL) framework designed to enhance coordination in language-guided multi-robot systems. ICCO consists of a Coordinator agent and multiple Local Agents, where the Coordinator generates Task-Aligned and Consistent Instructions (TACI) by integrating language instructions with environmental states, ensuring task alignment and behavioral consistency. The Coordinator and Local Agents are jointly trained to optimize a reward function that balances task efficiency and instruction following. A Consistency Enhancement Term is added to the learning objective to maximize mutual information between instructions and robot behaviors, further improving coordination. Simulation and real-world experiments validate the effectiveness of ICCO in achieving language-guided task-aligned multi-robot control. The demonstration can be found at https://yanoyoshiki.github.io/ICCO/.
Cooperative Grasping and Transportation using Multi-agent Reinforcement Learning with Ternary Force Representation
Nov 21, 2024



Cooperative grasping and transportation require effective coordination to complete the task. This study focuses on the approach leveraging force-sensing feedback, where robots use sensors to detect forces applied by others on an object to achieve coordination. Unlike explicit communication, it avoids delays and interruptions; however, force-sensing is highly sensitive and prone to interference from variations in grasping environment, such as changes in grasping force, grasping pose, object size and geometry, which can interfere with force signals, subsequently undermining coordination. We propose multi-agent reinforcement learning (MARL) with ternary force representation, a force representation that maintains consistent representation against variations in grasping environment. The simulation and real-world experiments demonstrate the robustness of the proposed method to changes in grasping force, object size and geometry as well as inherent sim2real gap.
Language to Map: Topological map generation from natural language path instructions
Mar 15, 2024



In this paper, a method for generating a map from path information described using natural language (textual path) is proposed. In recent years, robotics research mainly focus on vision-and-language navigation (VLN), a navigation task based on images and textual paths. Although VLN is expected to facilitate user instructions to robots, its current implementation requires users to explain the details of the path for each navigation session, which results in high explanation costs for users. To solve this problem, we proposed a method that creates a map as a topological map from a textual path and automatically creates a new path using this map. We believe that large language models (LLMs) can be used to understand textual path. Therefore, we propose and evaluate two methods, one for storing implicit maps in LLMs, and the other for generating explicit maps using LLMs. The implicit map is in the LLM's memory. It is created using prompts. In the explicit map, a topological map composed of nodes and edges is constructed and the actions at each node are stored. This makes it possible to estimate the path and actions at waypoints on an undescribed path, if enough information is available. Experimental results on path instructions generated in a real environment demonstrate that generating explicit maps achieves significantly higher accuracy than storing implicit maps in the LLMs.
CLIP feature-based randomized control using images and text for multiple tasks and robots
Jan 18, 2024This study presents a control framework leveraging vision language models (VLMs) for multiple tasks and robots. Notably, existing control methods using VLMs have achieved high performance in various tasks and robots in the training environment. However, these methods incur high costs for learning control policies for tasks and robots other than those in the training environment. Considering the application of industrial and household robots, learning in novel environments where robots are introduced is challenging. To address this issue, we propose a control framework that does not require learning control policies. Our framework combines the vision-language CLIP model with a randomized control. CLIP computes the similarity between images and texts by embedding them in the feature space. This study employs CLIP to compute the similarity between camera images and text representing the target state. In our method, the robot is controlled by a randomized controller that simultaneously explores and increases the similarity gradients. Moreover, we fine-tune the CLIP to improve the performance of the proposed method. Consequently, we confirm the effectiveness of our approach through a multitask simulation and a real robot experiment using a two-wheeled robot and robot arm.
Learning Locally, Communicating Globally: Reinforcement Learning of Multi-robot Task Allocation for Cooperative Transport
Dec 06, 2022



We consider task allocation for multi-object transport using a multi-robot system, in which each robot selects one object among multiple objects with different and unknown weights. The existing centralized methods assume the number of robots and tasks to be fixed, which is inapplicable to scenarios that differ from the learning environment. Meanwhile, the existing distributed methods limit the minimum number of robots and tasks to a constant value, making them applicable to various numbers of robots and tasks. However, they cannot transport an object whose weight exceeds the load capacity of robots observing the object. To make it applicable to various numbers of robots and objects with different and unknown weights, we propose a framework using multi-agent reinforcement learning for task allocation. First, we introduce a structured policy model consisting of 1) predesigned dynamic task priorities with global communication and 2) a neural network-based distributed policy model that determines the timing for coordination. The distributed policy builds consensus on the high-priority object under local observations and selects cooperative or independent actions. Then, the policy is optimized by multi-agent reinforcement learning through trial and error. This structured policy of local learning and global communication makes our framework applicable to various numbers of robots and objects with different and unknown weights, as demonstrated by numerical simulations.
Deep reinforcement learning of event-triggered communication and consensus-based control for distributed cooperative transport
Dec 05, 2022



In this paper, we present a solution to a design problem of control strategies for multi-agent cooperative transport. Although existing learning-based methods assume that the number of agents is the same as that in the training environment, the number might differ in reality considering that the robots' batteries may completely discharge, or additional robots may be introduced to reduce the time required to complete a task. Therefore, it is crucial that the learned strategy be applicable to scenarios wherein the number of agents differs from that in the training environment. In this paper, we propose a novel multi-agent reinforcement learning framework of event-triggered communication and consensus-based control for distributed cooperative transport. The proposed policy model estimates the resultant force and torque in a consensus manner using the estimates of the resultant force and torque with the neighborhood agents. Moreover, it computes the control and communication inputs to determine when to communicate with the neighboring agents under local observations and estimates of the resultant force and torque. Therefore, the proposed framework can balance the control performance and communication savings in scenarios wherein the number of agents differs from that in the training environment. We confirm the effectiveness of our approach by using a maximum of eight and six robots in the simulations and experiments, respectively.
* 14 pages, 14 figures
Development of global optimal coverage control using multiple aerial robots
Apr 28, 2021Coverage control has been widely used for constructing mobile sensor network such as for environmental monitoring, and one of the most commonly used methods is the Lloyd algorithm based on Voronoi partitions. However, when this method is used, the result sometimes converges to a local optimum. To overcome this problem, game theoretic coverage control has been proposed and found to be capable of stochastically deriving the optimal deployment. From a practical point of view, however, it is necessary to make the result converge to the global optimum deterministically. In this paper, we propose a global optimal coverage control along with collision avoidance in continuous space that ensures multiple sensors can deterministically and smoothly move to the global optimal deployment. This approach consists of a cut-in algorithm based on neighborhood importance of measurement and a modified potential method for collision avoidance. The effectiveness of the proposed algorithm has been confirmed through numerous simulations and some experiments using multiple aerial robots.
* 14 pages, 9 figures
Robust shape estimation with false-positive contact detection
Apr 21, 2021
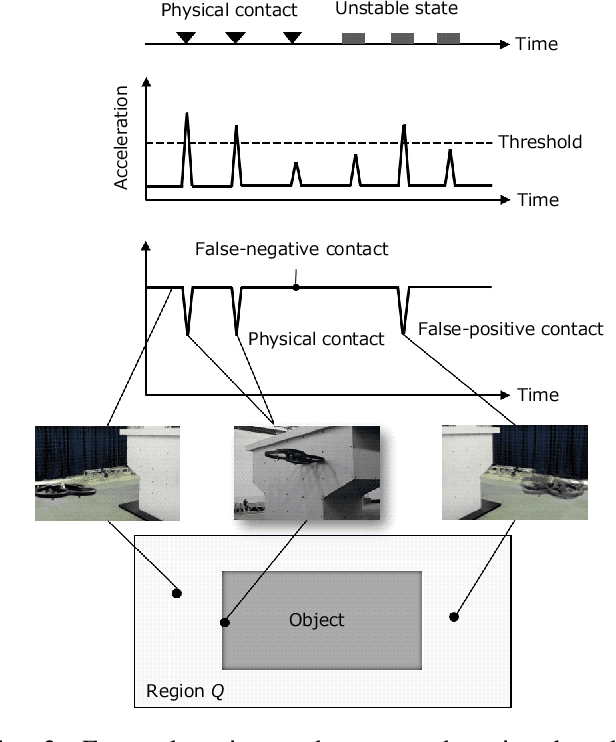
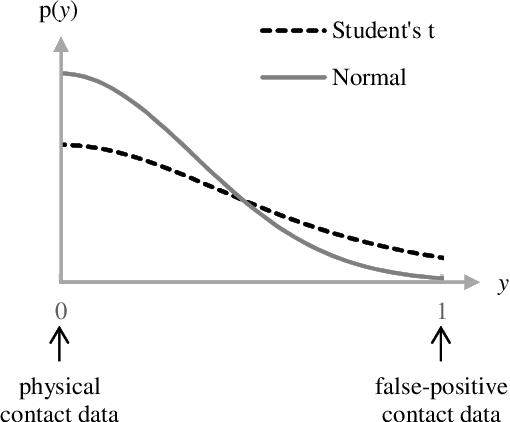
We propose a means of omni-directional contact detection using accelerometers instead of tactile sensors for object shape estimation using touch. Unlike tactile sensors, our contact-based detection method tends to induce a degree of uncertainty with false-positive contact data because the sensors may react not only to actual contact but also to the unstable behavior of the robot. Therefore, it is crucial to consider a robust shape estimation method capable of handling such false-positive contact data. To realize this, we introduce the concept of heteroscedasticity into the contact data and propose a robust shape estimation algorithm based on Gaussian process implicit surfaces (GPIS). We confirmed that our algorithm not only reduces shape estimation errors caused by false-positive contact data but also distinguishes false-positive contact data more clearly than the GPIS through simulations and actual experiments using a quadcopter.
* 12pages, 11 figures
Deep reinforcement learning of event-triggered communication and control for multi-agent cooperative transport
Mar 29, 2021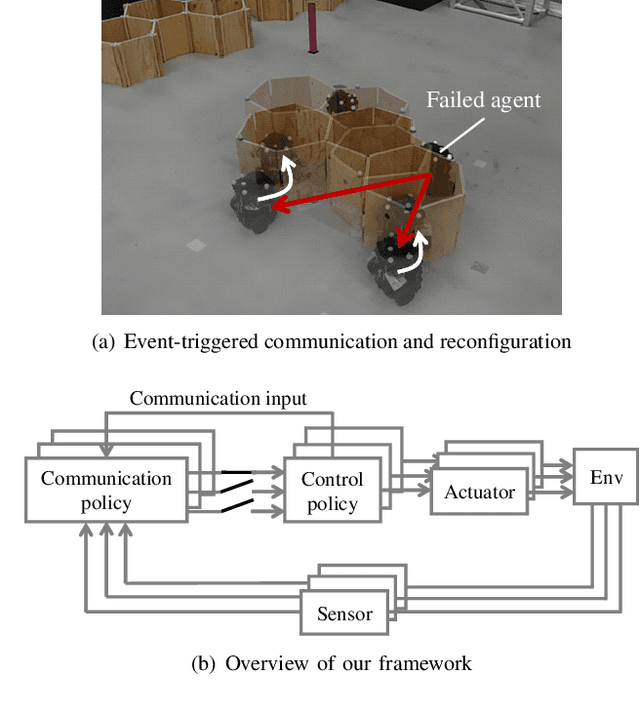
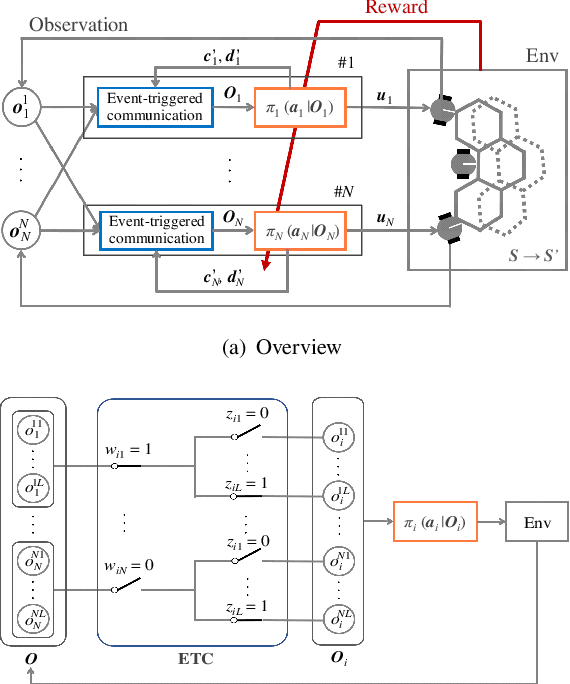
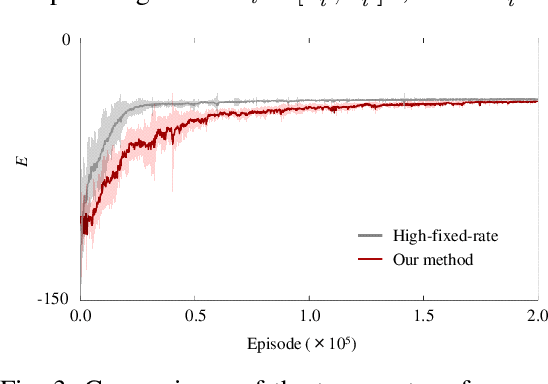
In this paper, we explore a multi-agent reinforcement learning approach to address the design problem of communication and control strategies for multi-agent cooperative transport. Typical end-to-end deep neural network policies may be insufficient for covering communication and control; these methods cannot decide the timing of communication and can only work with fixed-rate communications. Therefore, our framework exploits event-triggered architecture, namely, a feedback controller that computes the communication input and a triggering mechanism that determines when the input has to be updated again. Such event-triggered control policies are efficiently optimized using a multi-agent deep deterministic policy gradient. We confirmed that our approach could balance the transport performance and communication savings through numerical simulations.