 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Local Planner: A Periodic Sampling-Based Motion Planner with Minimal Waypoints for Home Environments
Feb 24, 2026The objective of this study is to enable fast and safe manipulation tasks in home environments. Specifically, we aim to develop a system that can recognize its surroundings and identify target objects while in motion, enabling it to plan and execute actions accordingly. We propose a periodic sampling-based whole-body trajectory planning method, called the "Robot Local Planner (RLP)." This method leverages unique features of home environments to enhance computational efficiency, motion optimality, and robustness against recognition and control errors, all while ensuring safety. The RLP minimizes computation time by planning with minimal waypoints and generating safe trajectories. Furthermore, overall motion optimality is improved by periodically executing trajectory planning to select more optimal motions. This approach incorporates inverse kinematics that are robust to base position errors, further enhancing robustness. Evaluation experiments demonstrated that the RLP outperformed existing methods in terms of motion planning time, motion duration, and robustness, confirming its effectiveness in home environments. Moreover, application experiments using a tidy-up task achieved high success rates and short operation times, thereby underscoring its practical feasibility.
Japanese Tort-case Dataset for Rationale-supported Legal Judgment Prediction
Dec 01, 2023This paper presents the first dataset for Japanese Legal Judgment Prediction (LJP), the Japanese Tort-case Dataset (JTD), which features two tasks: tort prediction and its rationale extraction. The rationale extraction task identifies the court's accepting arguments from alleged arguments by plaintiffs and defendants, which is a novel task in the field. JTD is constructed based on annotated 3,477 Japanese Civil Code judgments by 41 legal experts, resulting in 7,978 instances with 59,697 of their alleged arguments from the involved parties. Our baseline experiments show the feasibility of the proposed two tasks, and our error analysis by legal experts identifies sources of errors and suggests future directions of the LJP research.
Multimodal Active Measurement for Human Mesh Recovery in Close Proximity
Oct 12, 2023
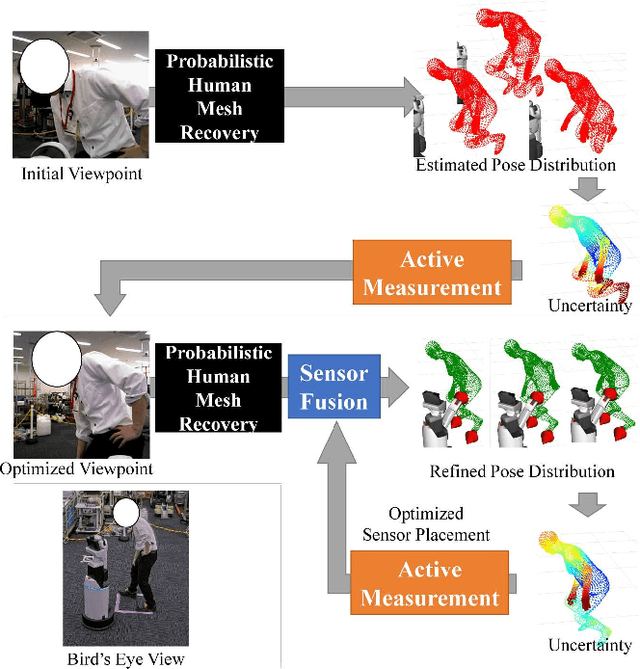


For safe and sophisticated physical human-robot interactions (pHRI), a robot needs to estimate the accurate body pose or mesh of the target person. However, in these pHRI scenarios, the robot cannot fully observe the target person's body with equipped cameras because the target person is usually close to the robot. This leads to severe truncation and occlusions, and results in poor accuracy of human pose estimation. For better accuracy of human pose estimation or mesh recovery on this limited information from cameras, we propose an active measurement and sensor fusion framework of the equipped cameras and other sensors such as touch sensors and 2D LiDAR. These touch and LiDAR sensing are obtained attendantly through pHRI without additional costs. These sensor measurements are sparse but reliable and informative cues for human mesh recovery. In our active measurement process, camera viewpoints and sensor placements are optimized based on the uncertainty of the estimated pose, which is closely related to the truncated or occluded areas. In our sensor fusion process, we fuse the sensor measurements to the camera-based estimated pose by minimizing the distance between the estimated mesh and measured positions. Our method is agnostic to robot configurations. Experiments were conducted using the Toyota Human Support Robot, which has a camera, 2D LiDAR, and a touch sensor on the robot arm. Our proposed method demonstrated the superiority in the human pose estimation accuracy on the quantitative comparison. Furthermore, our proposed method reliably estimated the pose of the target person in practical settings such as target people occluded by a blanket and standing aid with the robot arm.
Learning Locally, Communicating Globally: Reinforcement Learning of Multi-robot Task Allocation for Cooperative Transport
Dec 06, 2022



We consider task allocation for multi-object transport using a multi-robot system, in which each robot selects one object among multiple objects with different and unknown weights. The existing centralized methods assume the number of robots and tasks to be fixed, which is inapplicable to scenarios that differ from the learning environment. Meanwhile, the existing distributed methods limit the minimum number of robots and tasks to a constant value, making them applicable to various numbers of robots and tasks. However, they cannot transport an object whose weight exceeds the load capacity of robots observing the object. To make it applicable to various numbers of robots and objects with different and unknown weights, we propose a framework using multi-agent reinforcement learning for task allocation. First, we introduce a structured policy model consisting of 1) predesigned dynamic task priorities with global communication and 2) a neural network-based distributed policy model that determines the timing for coordination. The distributed policy builds consensus on the high-priority object under local observations and selects cooperative or independent actions. Then, the policy is optimized by multi-agent reinforcement learning through trial and error. This structured policy of local learning and global communication makes our framework applicable to various numbers of robots and objects with different and unknown weights, as demonstrated by numerical simulations.