 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Clique: Graph-based Correspondence Matching Augmented by Vision Language Models for Object-based Global Localization
Oct 04, 2024



This letter proposes a method of global localization on a map with semantic object landmarks. One of the most promising approaches for localization on object maps is to use semantic graph matching using landmark descriptors calculated from the distribution of surrounding objects. These descriptors are vulnerable to misclassification and partial observations. Moreover, many existing methods rely on inlier extraction using RANSAC, which is stochastic and sensitive to a high outlier rate. To address the former issue, we augment the correspondence matching using Vision Language Models (VLMs). Landmark discriminability is improved by VLM embeddings, which are independent of surrounding objects. In addition, inliers are estimated deterministically using a graph-theoretic approach. We also incorporate pose calculation using the weighted least squares considering correspondence similarity and observation completeness to improve the robustness. We confirmed improvements in matching and pose estimation accuracy through experiments on ScanNet and TUM datasets.
CLIP-Loc: Multi-modal Landmark Association for Global Localization in Object-based Maps
Feb 08, 2024



This paper describes a multi-modal data association method for global localization using object-based maps and camera images. In global localization, or relocalization, using object-based maps, existing methods typically resort to matching all possible combinations of detected objects and landmarks with the same object category, followed by inlier extraction using RANSAC or brute-force search. This approach becomes infeasible as the number of landmarks increases due to the exponential growth of correspondence candidates. In this paper, we propose labeling landmarks with natural language descriptions and extracting correspondences based on conceptual similarity with image observations using a Vision Language Model (VLM). By leveraging detailed text information, our approach efficiently extracts correspondences compared to methods using only object categories. Through experiments, we demonstrate that the proposed method enables more accurate global localization with fewer iterations compared to baseline methods, exhibiting its efficiency.
Multimodal Active Measurement for Human Mesh Recovery in Close Proximity
Oct 12, 2023
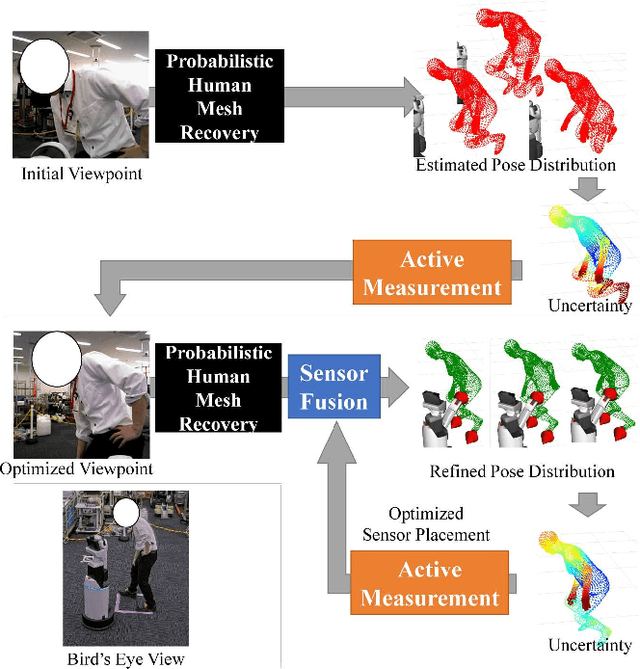


For safe and sophisticated physical human-robot interactions (pHRI), a robot needs to estimate the accurate body pose or mesh of the target person. However, in these pHRI scenarios, the robot cannot fully observe the target person's body with equipped cameras because the target person is usually close to the robot. This leads to severe truncation and occlusions, and results in poor accuracy of human pose estimation. For better accuracy of human pose estimation or mesh recovery on this limited information from cameras, we propose an active measurement and sensor fusion framework of the equipped cameras and other sensors such as touch sensors and 2D LiDAR. These touch and LiDAR sensing are obtained attendantly through pHRI without additional costs. These sensor measurements are sparse but reliable and informative cues for human mesh recovery. In our active measurement process, camera viewpoints and sensor placements are optimized based on the uncertainty of the estimated pose, which is closely related to the truncated or occluded areas. In our sensor fusion process, we fuse the sensor measurements to the camera-based estimated pose by minimizing the distance between the estimated mesh and measured positions. Our method is agnostic to robot configurations. Experiments were conducted using the Toyota Human Support Robot, which has a camera, 2D LiDAR, and a touch sensor on the robot arm. Our proposed method demonstrated the superiority in the human pose estimation accuracy on the quantitative comparison. Furthermore, our proposed method reliably estimated the pose of the target person in practical settings such as target people occluded by a blanket and standing aid with the robot arm.