 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisalignment of Semantic Relation Knowledge between WordNet and Human Intuition
Dec 03, 2024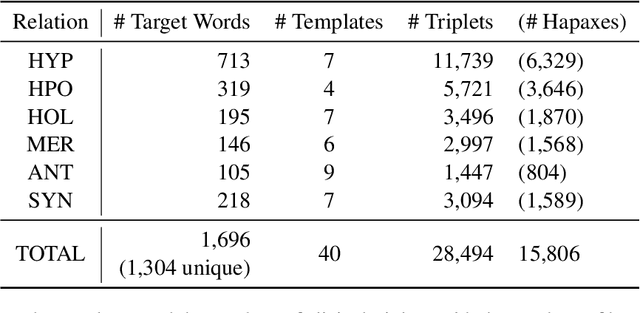
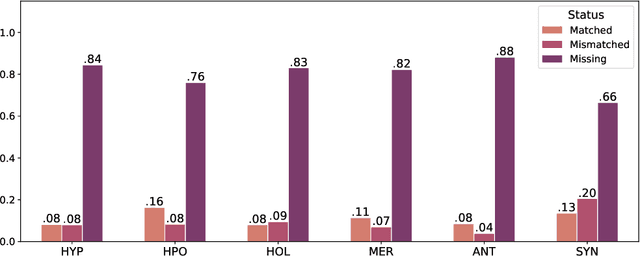
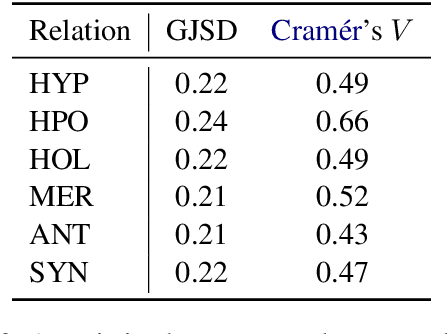
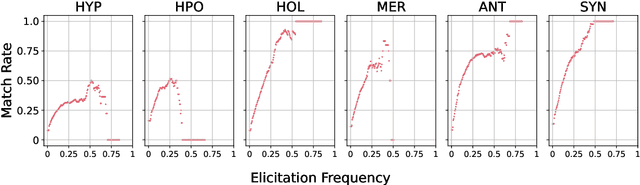
WordNet provides a carefully constructed repository of semantic relations, created by specialists. But there is another source of information on semantic relations, the intuition of language users. We present the first systematic study of the degree to which these two sources are aligned. Investigating the cases of misalignment could make proper use of WordNet and facilitate its improvement. Our analysis which uses templates to elicit responses from human participants, reveals a general misalignment of semantic relation knowledge between WordNet and human intuition. Further analyses find a systematic pattern of mismatch among synonymy and taxonomic relations~(hypernymy and hyponymy), together with the fact that WordNet path length does not serve as a reliable indicator of human intuition regarding hypernymy or hyponymy relations.
A Comprehensive Evaluation of Semantic Relation Knowledge of Pretrained Language Models and Humans
Dec 02, 2024Recently, much work has concerned itself with the enigma of what exactly PLMs (pretrained language models) learn about different aspects of language, and how they learn it. One stream of this type of research investigates the knowledge that PLMs have about semantic relations. However, many aspects of semantic relations were left unexplored. Only one relation was considered, namely hypernymy. Furthermore, previous work did not measure humans' performance on the same task as that solved by the PLMs. This means that at this point in time, there is only an incomplete view of models' semantic relation knowledge. To address this gap, we introduce a comprehensive evaluation framework covering five relations beyond hypernymy, namely hyponymy, holonymy, meronymy, antonymy, and synonymy. We use six metrics (two newly introduced here) for recently untreated aspects of semantic relation knowledge, namely soundness, completeness, symmetry, asymmetry, prototypicality, and distinguishability and fairly compare humans and models on the same task. Our extensive experiments involve 16 PLMs, eight masked and eight causal language models. Up to now only masked language models had been tested although causal and masked language models treat context differently. Our results reveal a significant knowledge gap between humans and models for almost all semantic relations. Antonymy is the outlier relation where all models perform reasonably well. In general, masked language models perform significantly better than causal language models. Nonetheless, both masked and causal language models are likely to confuse non-antonymy relations with antonymy.
GPTs and Language Barrier: A Cross-Lingual Legal QA Examination
Mar 26, 2024
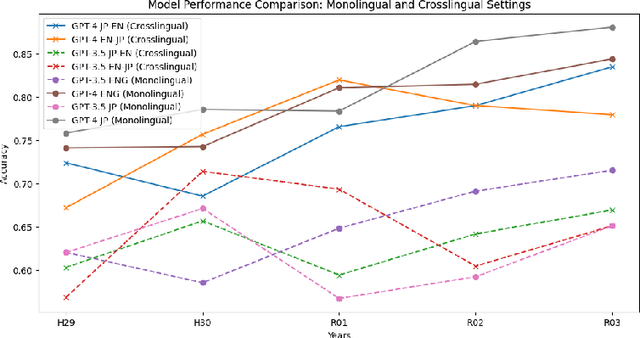
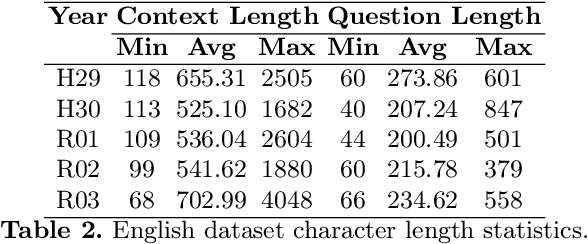
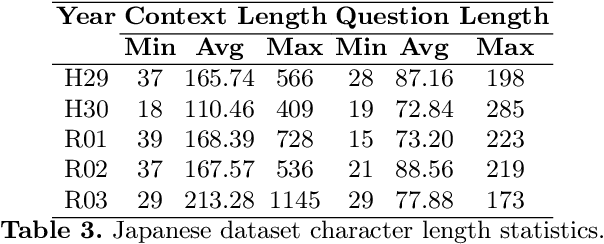
In this paper, we explore the application of Generative Pre-trained Transformers (GPTs) in cross-lingual legal Question-Answering (QA) systems using the COLIEE Task 4 dataset. In the COLIEE Task 4, given a statement and a set of related legal articles that serve as context, the objective is to determine whether the statement is legally valid, i.e., if it can be inferred from the provided contextual articles or not, which is also known as an entailment task. By benchmarking four different combinations of English and Japanese prompts and data, we provide valuable insights into GPTs' performance in multilingual legal QA scenarios, contributing to the development of more efficient and accurate cross-lingual QA solutions in the legal domain.
Japanese Tort-case Dataset for Rationale-supported Legal Judgment Prediction
Dec 01, 2023This paper presents the first dataset for Japanese Legal Judgment Prediction (LJP), the Japanese Tort-case Dataset (JTD), which features two tasks: tort prediction and its rationale extraction. The rationale extraction task identifies the court's accepting arguments from alleged arguments by plaintiffs and defendants, which is a novel task in the field. JTD is constructed based on annotated 3,477 Japanese Civil Code judgments by 41 legal experts, resulting in 7,978 instances with 59,697 of their alleged arguments from the involved parties. Our baseline experiments show the feasibility of the proposed two tasks, and our error analysis by legal experts identifies sources of errors and suggests future directions of the LJP research.
Dynamic Sasvi: Strong Safe Screening for Norm-Regularized Least Squares
Feb 08, 2021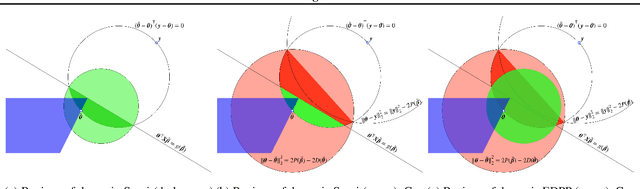
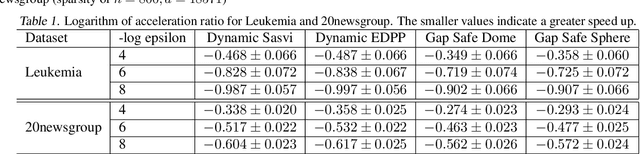
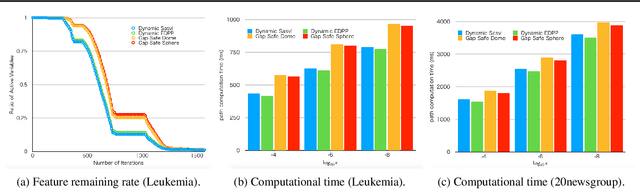
A recently introduced technique for a sparse optimization problem called "safe screening" allows us to identify irrelevant variables in the early stage of optimization. In this paper, we first propose a flexible framework for safe screening based on the Fenchel-Rockafellar duality and then derive a strong safe screening rule for norm-regularized least squares by the framework. We call the proposed screening rule for norm-regularized least squares "dynamic Sasvi" because it can be interpreted as a generalization of Sasvi. Unlike the original Sasvi, it does not require the exact solution of a more strongly regularized problem; hence, it works safely in practice. We show that our screening rule can eliminate more features and increase the speed of the solver in comparison with other screening rules both theoretically and experimentally.