 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemCovert: Secure and Covert Video Transmission via Deep Semantic-Level Hiding
Dec 23, 2025Video semantic communication, praised for its transmission efficiency, still faces critical challenges related to privacy leakage. Traditional security techniques like steganography and encryption are challenging to apply since they are not inherently robust against semantic-level transformations and abstractions. Moreover, the temporal continuity of video enables framewise statistical modeling over extended periods, which increases the risk of exposing distributional anomalies and reconstructing hidden content. To address these challenges, we propose SemCovert, a deep semantic-level hiding framework for secure and covert video transmission. SemCovert introduces a pair of co-designed models, namely the semantic hiding model and the secret semantic extractor, which are seamlessly integrated into the semantic communication pipeline. This design enables authorized receivers to reliably recover hidden information, while keeping it imperceptible to regular users. To further improve resistance to analysis, we introduce a randomized semantic hiding strategy, which breaks the determinism of embedding and introduces unpredictable distribution patterns. The experimental results demonstrate that SemCovert effectively mitigates potential eavesdropping and detection risks while reliably concealing secret videos during transmission. Meanwhile, video quality suffers only minor degradation, preserving transmission fidelity. These results confirm SemCovert's effectiveness in enabling secure and covert transmission without compromising semantic communication performance.
Misalignment of Semantic Relation Knowledge between WordNet and Human Intuition
Dec 03, 2024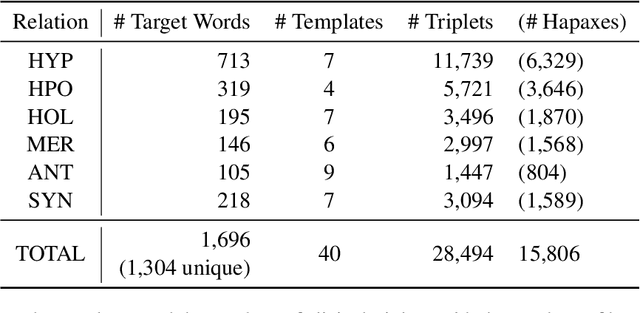
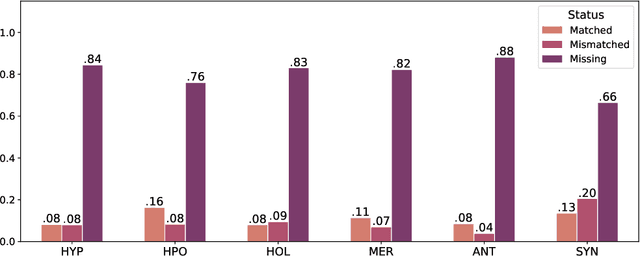
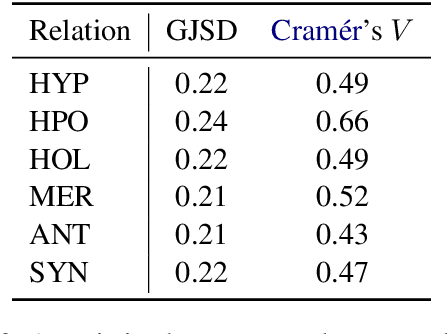
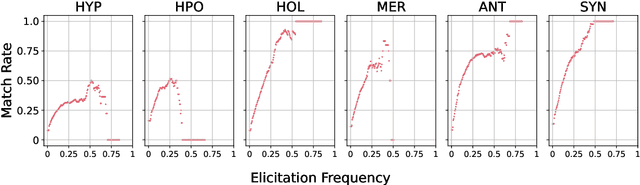
WordNet provides a carefully constructed repository of semantic relations, created by specialists. But there is another source of information on semantic relations, the intuition of language users. We present the first systematic study of the degree to which these two sources are aligned. Investigating the cases of misalignment could make proper use of WordNet and facilitate its improvement. Our analysis which uses templates to elicit responses from human participants, reveals a general misalignment of semantic relation knowledge between WordNet and human intuition. Further analyses find a systematic pattern of mismatch among synonymy and taxonomic relations~(hypernymy and hyponymy), together with the fact that WordNet path length does not serve as a reliable indicator of human intuition regarding hypernymy or hyponymy relations.
A Comprehensive Evaluation of Semantic Relation Knowledge of Pretrained Language Models and Humans
Dec 02, 2024Recently, much work has concerned itself with the enigma of what exactly PLMs (pretrained language models) learn about different aspects of language, and how they learn it. One stream of this type of research investigates the knowledge that PLMs have about semantic relations. However, many aspects of semantic relations were left unexplored. Only one relation was considered, namely hypernymy. Furthermore, previous work did not measure humans' performance on the same task as that solved by the PLMs. This means that at this point in time, there is only an incomplete view of models' semantic relation knowledge. To address this gap, we introduce a comprehensive evaluation framework covering five relations beyond hypernymy, namely hyponymy, holonymy, meronymy, antonymy, and synonymy. We use six metrics (two newly introduced here) for recently untreated aspects of semantic relation knowledge, namely soundness, completeness, symmetry, asymmetry, prototypicality, and distinguishability and fairly compare humans and models on the same task. Our extensive experiments involve 16 PLMs, eight masked and eight causal language models. Up to now only masked language models had been tested although causal and masked language models treat context differently. Our results reveal a significant knowledge gap between humans and models for almost all semantic relations. Antonymy is the outlier relation where all models perform reasonably well. In general, masked language models perform significantly better than causal language models. Nonetheless, both masked and causal language models are likely to confuse non-antonymy relations with antonymy.