 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisalignment of Semantic Relation Knowledge between WordNet and Human Intuition
Dec 03, 2024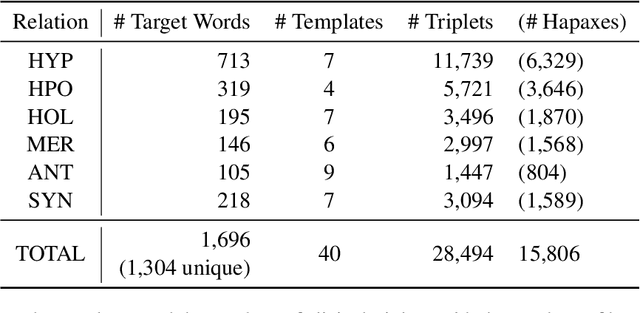
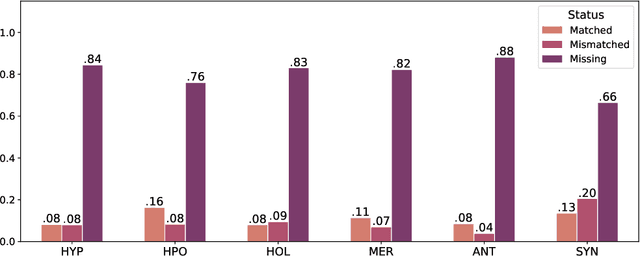
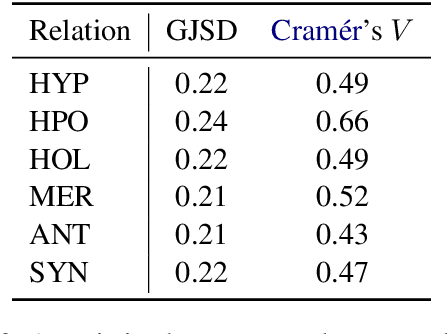
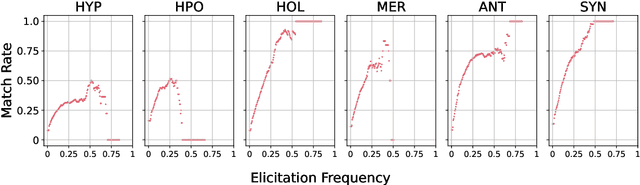
WordNet provides a carefully constructed repository of semantic relations, created by specialists. But there is another source of information on semantic relations, the intuition of language users. We present the first systematic study of the degree to which these two sources are aligned. Investigating the cases of misalignment could make proper use of WordNet and facilitate its improvement. Our analysis which uses templates to elicit responses from human participants, reveals a general misalignment of semantic relation knowledge between WordNet and human intuition. Further analyses find a systematic pattern of mismatch among synonymy and taxonomic relations~(hypernymy and hyponymy), together with the fact that WordNet path length does not serve as a reliable indicator of human intuition regarding hypernymy or hyponymy relations.
A Comprehensive Evaluation of Semantic Relation Knowledge of Pretrained Language Models and Humans
Dec 02, 2024Recently, much work has concerned itself with the enigma of what exactly PLMs (pretrained language models) learn about different aspects of language, and how they learn it. One stream of this type of research investigates the knowledge that PLMs have about semantic relations. However, many aspects of semantic relations were left unexplored. Only one relation was considered, namely hypernymy. Furthermore, previous work did not measure humans' performance on the same task as that solved by the PLMs. This means that at this point in time, there is only an incomplete view of models' semantic relation knowledge. To address this gap, we introduce a comprehensive evaluation framework covering five relations beyond hypernymy, namely hyponymy, holonymy, meronymy, antonymy, and synonymy. We use six metrics (two newly introduced here) for recently untreated aspects of semantic relation knowledge, namely soundness, completeness, symmetry, asymmetry, prototypicality, and distinguishability and fairly compare humans and models on the same task. Our extensive experiments involve 16 PLMs, eight masked and eight causal language models. Up to now only masked language models had been tested although causal and masked language models treat context differently. Our results reveal a significant knowledge gap between humans and models for almost all semantic relations. Antonymy is the outlier relation where all models perform reasonably well. In general, masked language models perform significantly better than causal language models. Nonetheless, both masked and causal language models are likely to confuse non-antonymy relations with antonymy.
Japanese Tort-case Dataset for Rationale-supported Legal Judgment Prediction
Dec 01, 2023This paper presents the first dataset for Japanese Legal Judgment Prediction (LJP), the Japanese Tort-case Dataset (JTD), which features two tasks: tort prediction and its rationale extraction. The rationale extraction task identifies the court's accepting arguments from alleged arguments by plaintiffs and defendants, which is a novel task in the field. JTD is constructed based on annotated 3,477 Japanese Civil Code judgments by 41 legal experts, resulting in 7,978 instances with 59,697 of their alleged arguments from the involved parties. Our baseline experiments show the feasibility of the proposed two tasks, and our error analysis by legal experts identifies sources of errors and suggests future directions of the LJP research.
Multi-Task and Multi-Corpora Training Strategies to Enhance Argumentative Sentence Linking Performance
Sep 27, 2021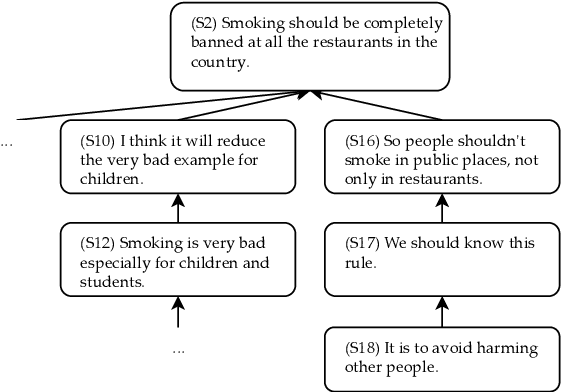
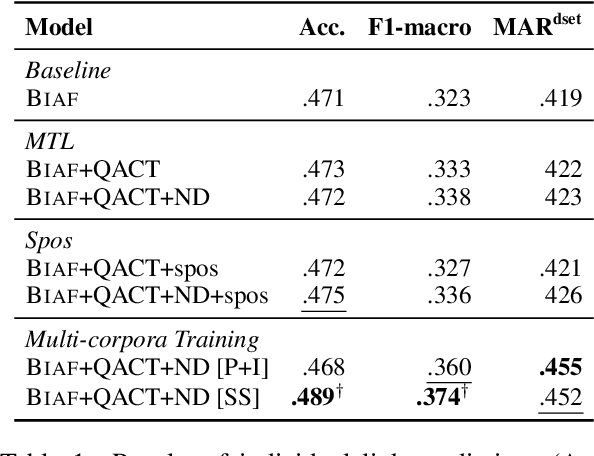
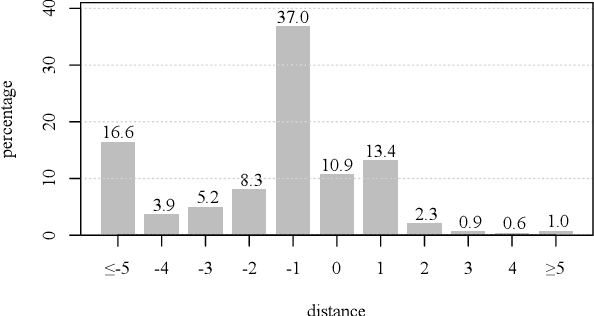
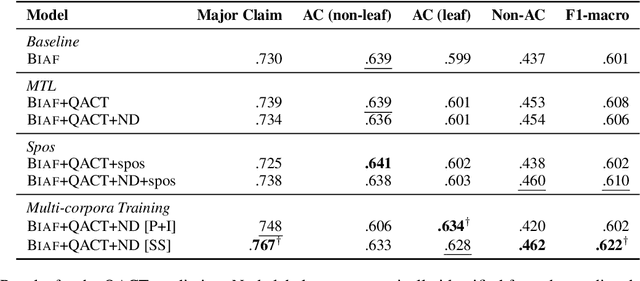
Argumentative structure prediction aims to establish links between textual units and label the relationship between them, forming a structured representation for a given input text. The former task, linking, has been identified by earlier works as particularly challenging, as it requires finding the most appropriate structure out of a very large search space of possible link combinations. In this paper, we improve a state-of-the-art linking model by using multi-task and multi-corpora training strategies. Our auxiliary tasks help the model to learn the role of each sentence in the argumentative structure. Combining multi-corpora training with a selective sampling strategy increases the training data size while ensuring that the model still learns the desired target distribution well. Experiments on essays written by English-as-a-foreign-language learners show that both strategies significantly improve the model's performance; for instance, we observe a 15.8% increase in the F1-macro for individual link predictions.
Selective Sampling for Example-based Word Sense Disambiguation
Oct 23, 1999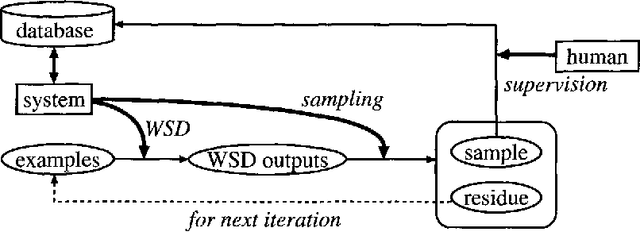
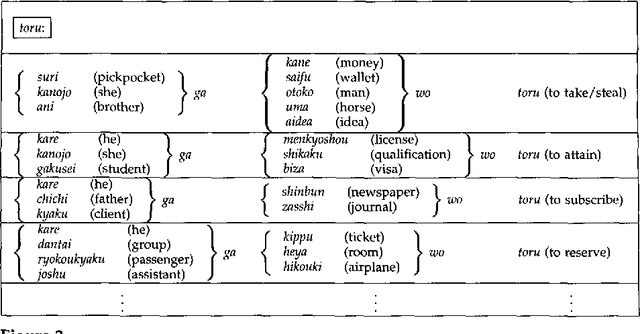
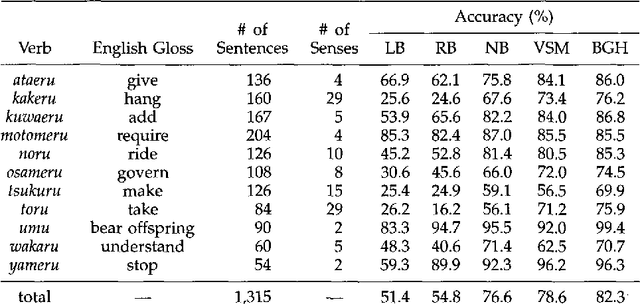
This paper proposes an efficient example sampling method for example-based word sense disambiguation systems. To construct a database of practical size, a considerable overhead for manual sense disambiguation (overhead for supervision) is required. In addition, the time complexity of searching a large-sized database poses a considerable problem (overhead for search). To counter these problems, our method selectively samples a smaller-sized effective subset from a given example set for use in word sense disambiguation. Our method is characterized by the reliance on the notion of training utility: the degree to which each example is informative for future example sampling when used for the training of the system. The system progressively collects examples by selecting those with greatest utility. The paper reports the effectiveness of our method through experiments on about one thousand sentences. Compared to experiments with other example sampling methods, our method reduced both the overhead for supervision and the overhead for search, without the degeneration of the performance of the system.
* 25 pages, 14 Postscript figures
Selective Sampling of Effective Example Sentence Sets for Word Sense Disambiguation
Feb 17, 1997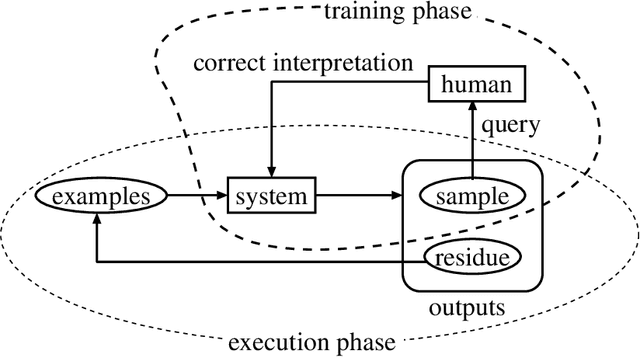
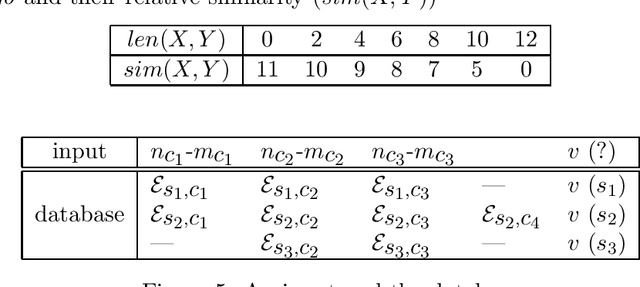
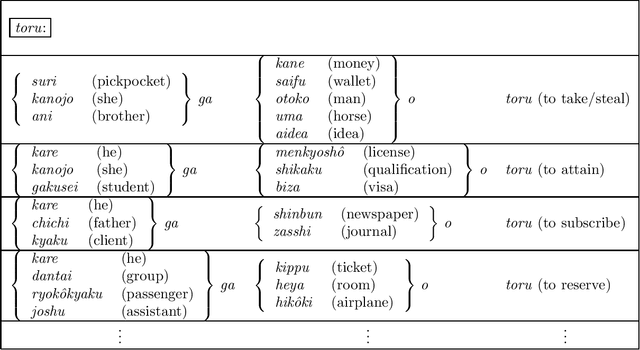
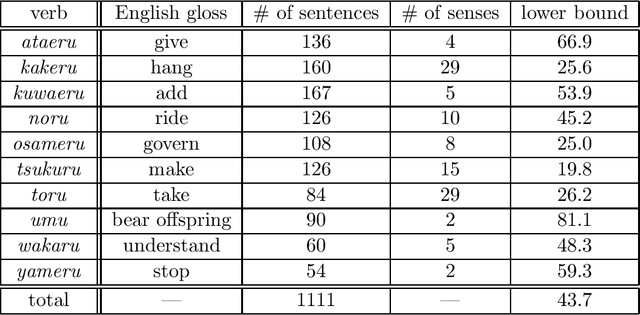
This paper proposes an efficient example selection method for example-based word sense disambiguation systems. To construct a practical size database, a considerable overhead for manual sense disambiguation is required. Our method is characterized by the reliance on the notion of the training utility: the degree to which each example is informative for future example selection when used for the training of the system. The system progressively collects examples by selecting those with greatest utility. The paper reports the effectivity of our method through experiments on about one thousand sentences. Compared to experiments with random example selection, our method reduced the overhead without the degeneration of the performance of the system.
* 14 pages, uses epsbox.sty