 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Language Modeling on Speech-driven Question Answering
Jul 10, 2004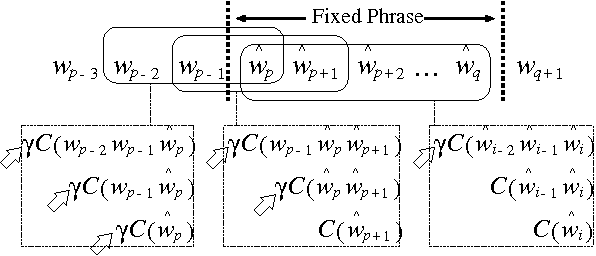
We integrate automatic speech recognition (ASR) and question answering (QA) to realize a speech-driven QA system, and evaluate its performance. We adapt an N-gram language model to natural language questions, so that the input of our system can be recognized with a high accuracy. We target WH-questions which consist of the topic part and fixed phrase used to ask about something. We first produce a general N-gram model intended to recognize the topic and emphasize the counts of the N-grams that correspond to the fixed phrases. Given a transcription by the ASR engine, the QA engine extracts the answer candidates from target documents. We propose a passage retrieval method robust against recognition errors in the transcription. We use the QA test collection produced in NTCIR, which is a TREC-style evaluation workshop, and show the effectiveness of our method by means of experiments.
* 4 pages, Proceedings of the 8th International Conference on Spoken Language Processing (to appear)
Unsupervised Topic Adaptation for Lecture Speech Retrieval
Jul 10, 2004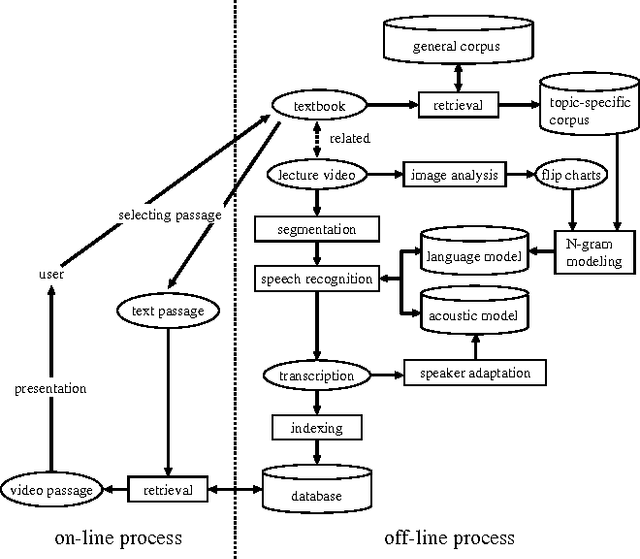

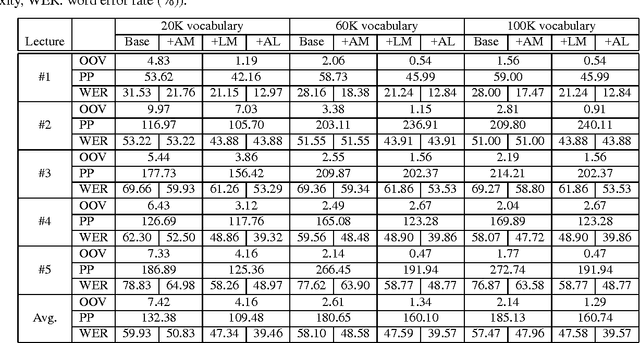
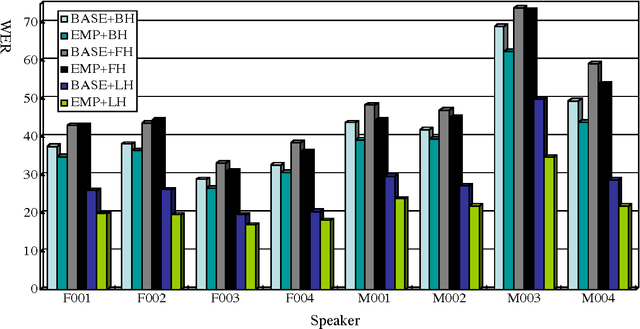
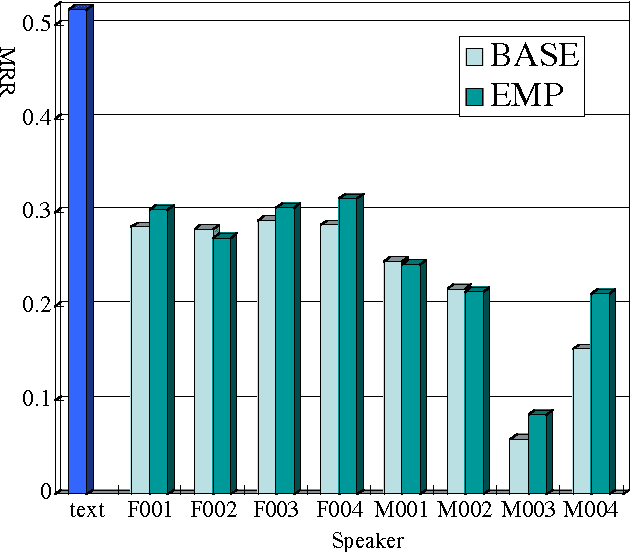
We are developing a cross-media information retrieval system, in which users can view specific segments of lecture videos by submitting text queries. To produce a text index, the audio track is extracted from a lecture video and a transcription is generated by automatic speech recognition. In this paper, to improve the quality of our retrieval system, we extensively investigate the effects of adapting acoustic and language models on speech recognition. We perform an MLLR-based method to adapt an acoustic model. To obtain a corpus for language model adaptation, we use the textbook for a target lecture to search a Web collection for the pages associated with the lecture topic. We show the effectiveness of our method by means of experiments.
* 4 pages, Proceedings of the 8th International Conference on Spoken Language Processing (to appear)
Summarizing Encyclopedic Term Descriptions on the Web
Jul 10, 2004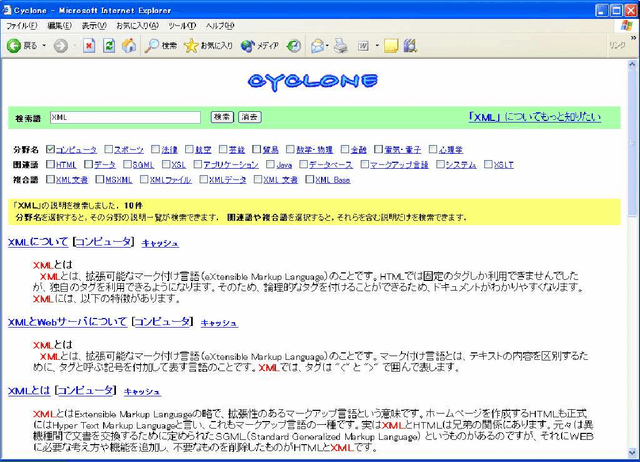

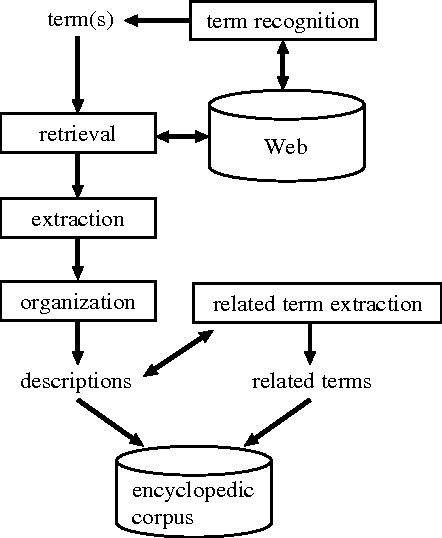
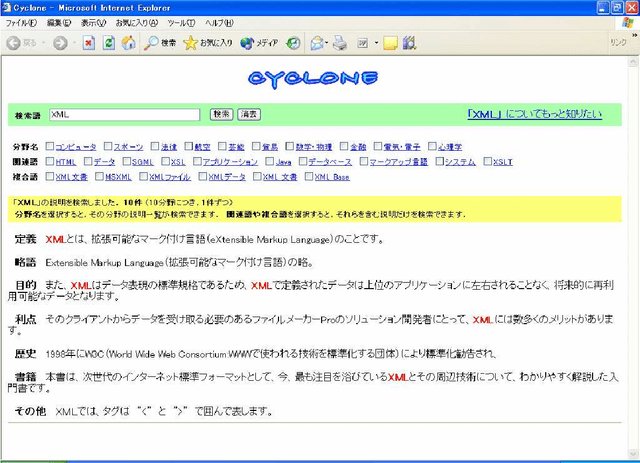
We are developing an automatic method to compile an encyclopedic corpus from the Web. In our previous work, paragraph-style descriptions for a term are extracted from Web pages and organized based on domains. However, these descriptions are independent and do not comprise a condensed text as in hand-crafted encyclopedias. To resolve this problem, we propose a summarization method, which produces a single text from multiple descriptions. The resultant summary concisely describes a term from different viewpoints. We also show the effectiveness of our method by means of experiments.
* 7 pages, Proceedings of the 20th International Conference on Computational Linguistics (to appear)
Test Collections for Patent-to-Patent Retrieval and Patent Map Generation in NTCIR-4 Workshop
Apr 10, 2004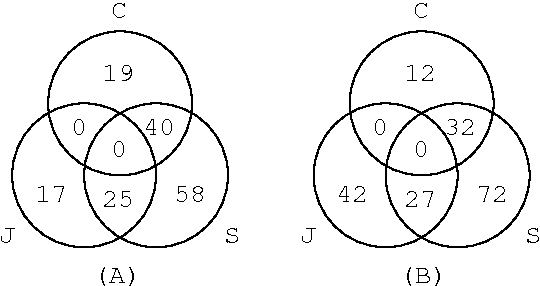
This paper describes the Patent Retrieval Task in the Fourth NTCIR Workshop, and the test collections produced in this task. We perform the invalidity search task, in which each participant group searches a patent collection for the patents that can invalidate the demand in an existing claim. We also perform the automatic patent map generation task, in which the patents associated with a specific topic are organized in a multi-dimensional matrix.
* 4 pages, Proceedings of the 4th International Conference on Language Resources and Evaluation (to appear)
A Cross-media Retrieval System for Lecture Videos
Sep 13, 2003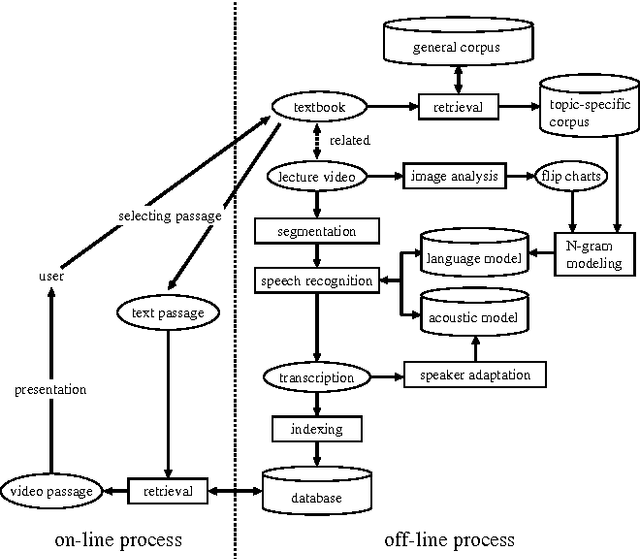
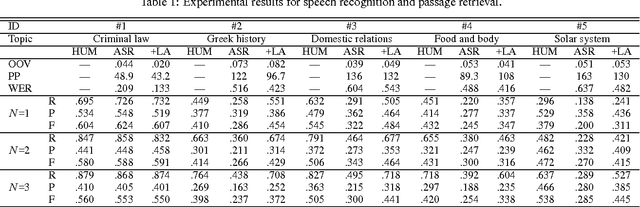
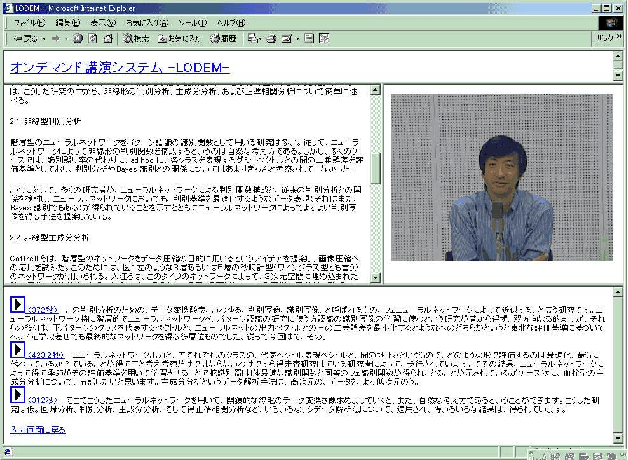
We propose a cross-media lecture-on-demand system, in which users can selectively view specific segments of lecture videos by submitting text queries. Users can easily formulate queries by using the textbook associated with a target lecture, even if they cannot come up with effective keywords. Our system extracts the audio track from a target lecture video, generates a transcription by large vocabulary continuous speech recognition, and produces a text index. Experimental results showed that by adapting speech recognition to the topic of the lecture, the recognition accuracy increased and the retrieval accuracy was comparable with that obtained by human transcription.
Building a Test Collection for Speech-Driven Web Retrieval
Sep 12, 2003

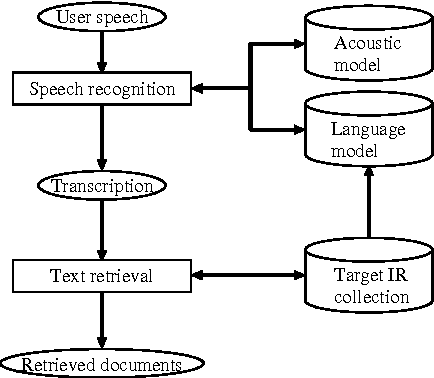

This paper describes a test collection (benchmark data) for retrieval systems driven by spoken queries. This collection was produced in the subtask of the NTCIR-3 Web retrieval task, which was performed in a TREC-style evaluation workshop. The search topics and document collection for the Web retrieval task were used to produce spoken queries and language models for speech recognition, respectively. We used this collection to evaluate the performance of our retrieval system. Experimental results showed that (a) the use of target documents for language modeling and (b) enhancement of the vocabulary size in speech recognition were effective in improving the system performance.
Speech-Driven Text Retrieval: Using Target IR Collections for Statistical Language Model Adaptation in Speech Recognition
Jun 24, 2002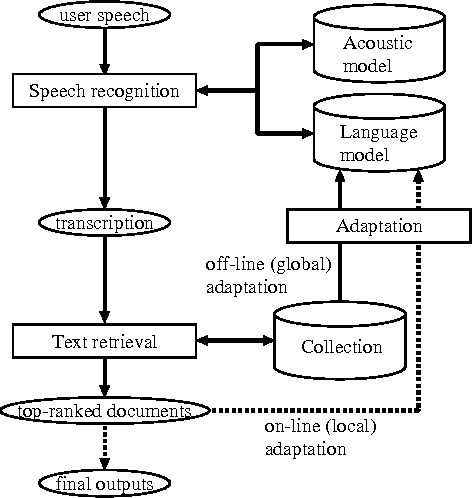

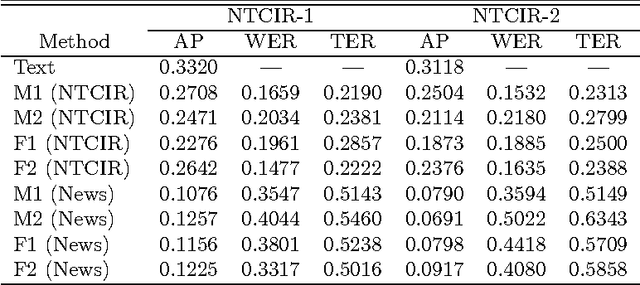
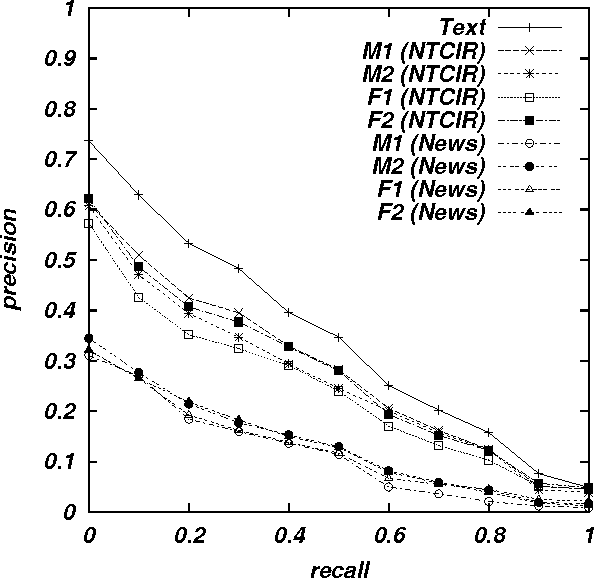
Speech recognition has of late become a practical technology for real world applications. Aiming at speech-driven text retrieval, which facilitates retrieving information with spoken queries, we propose a method to integrate speech recognition and retrieval methods. Since users speak contents related to a target collection, we adapt statistical language models used for speech recognition based on the target collection, so as to improve both the recognition and retrieval accuracy. Experiments using existing test collections combined with dictated queries showed the effectiveness of our method.
Language Modeling for Multi-Domain Speech-Driven Text Retrieval
Jun 24, 2002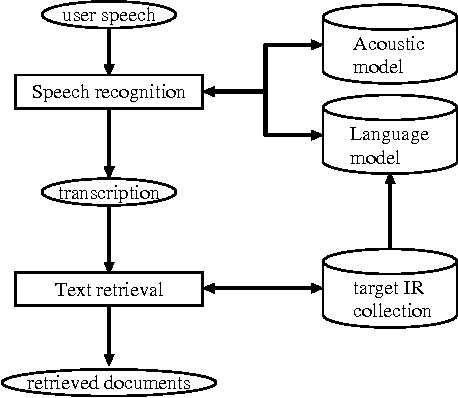
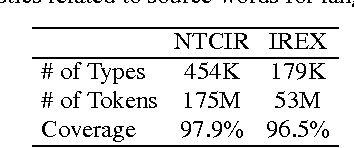

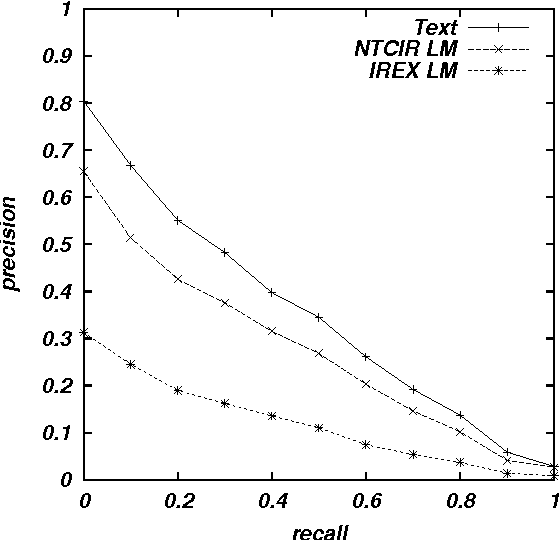
We report experimental results associated with speech-driven text retrieval, which facilitates retrieving information in multiple domains with spoken queries. Since users speak contents related to a target collection, we produce language models used for speech recognition based on the target collection, so as to improve both the recognition and retrieval accuracy. Experiments using existing test collections combined with dictated queries showed the effectiveness of our method.
PRIME: A System for Multi-lingual Patent Retrieval
Jun 24, 2002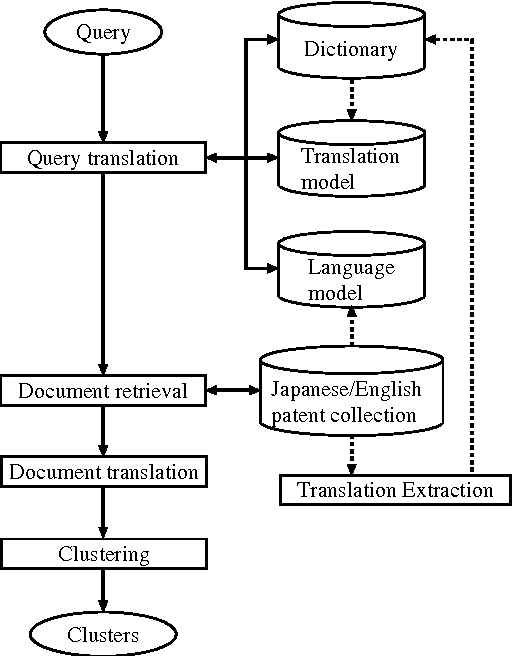
Given the growing number of patents filed in multiple countries, users are interested in retrieving patents across languages. We propose a multi-lingual patent retrieval system, which translates a user query into the target language, searches a multilingual database for patents relevant to the query, and improves the browsing efficiency by way of machine translation and clustering. Our system also extracts new translations from patent families consisting of comparable patents, to enhance the translation dictionary.
Applying a Hybrid Query Translation Method to Japanese/English Cross-Language Patent Retrieval
Jun 24, 2002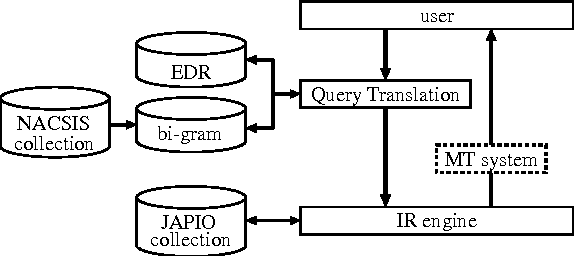


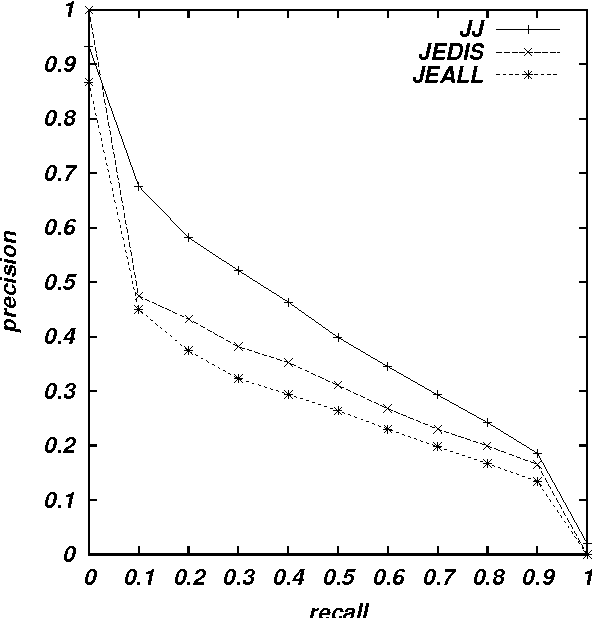
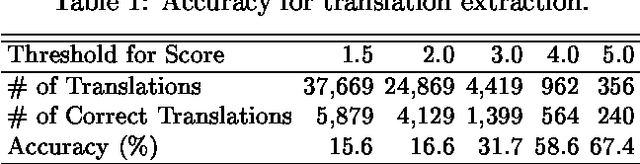
This paper applies an existing query translation method to cross-language patent retrieval. In our method, multiple dictionaries are used to derive all possible translations for an input query, and collocational statistics are used to resolve translation ambiguity. We used Japanese/English parallel patent abstracts to perform comparative experiments, where our method outperformed a simple dictionary-based query translation method, and achieved 76% of monolingual retrieval in terms of average precision.