 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Topic Adaptation for Lecture Speech Retrieval
Jul 10, 2004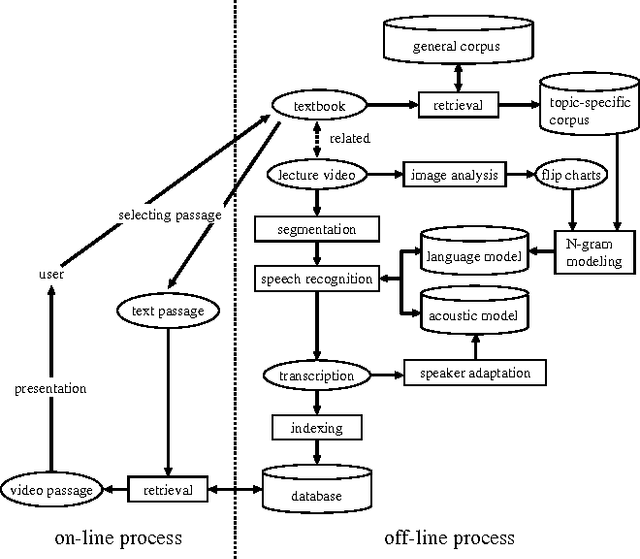

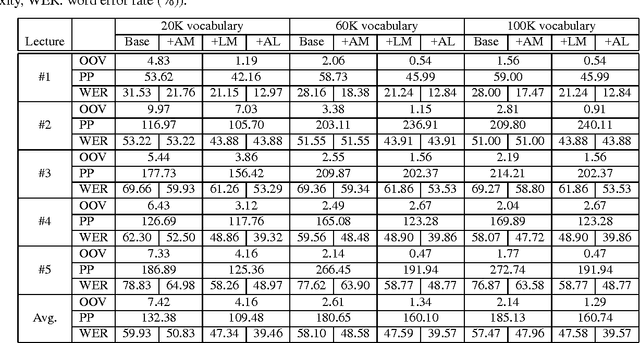
We are developing a cross-media information retrieval system, in which users can view specific segments of lecture videos by submitting text queries. To produce a text index, the audio track is extracted from a lecture video and a transcription is generated by automatic speech recognition. In this paper, to improve the quality of our retrieval system, we extensively investigate the effects of adapting acoustic and language models on speech recognition. We perform an MLLR-based method to adapt an acoustic model. To obtain a corpus for language model adaptation, we use the textbook for a target lecture to search a Web collection for the pages associated with the lecture topic. We show the effectiveness of our method by means of experiments.
* 4 pages, Proceedings of the 8th International Conference on Spoken Language Processing (to appear)
Summarizing Encyclopedic Term Descriptions on the Web
Jul 10, 2004

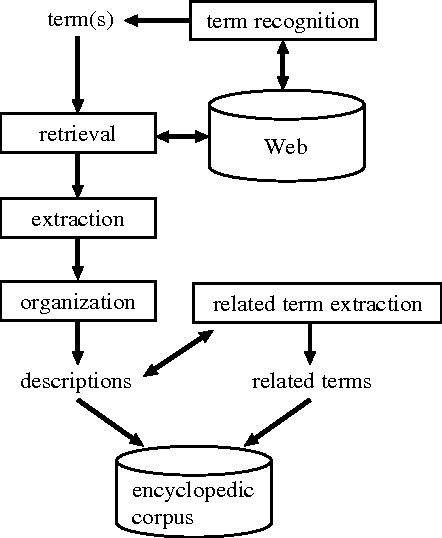
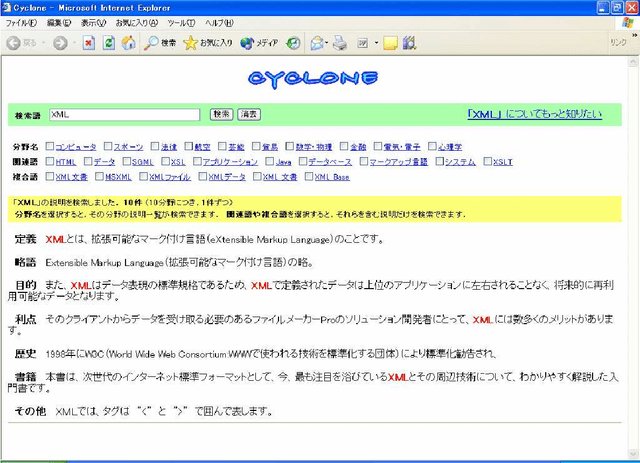
We are developing an automatic method to compile an encyclopedic corpus from the Web. In our previous work, paragraph-style descriptions for a term are extracted from Web pages and organized based on domains. However, these descriptions are independent and do not comprise a condensed text as in hand-crafted encyclopedias. To resolve this problem, we propose a summarization method, which produces a single text from multiple descriptions. The resultant summary concisely describes a term from different viewpoints. We also show the effectiveness of our method by means of experiments.
* 7 pages, Proceedings of the 20th International Conference on Computational Linguistics (to appear)
A Cross-media Retrieval System for Lecture Videos
Sep 13, 2003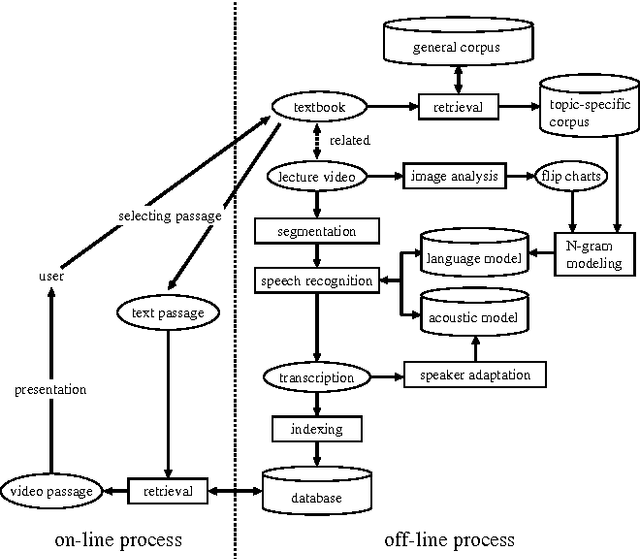
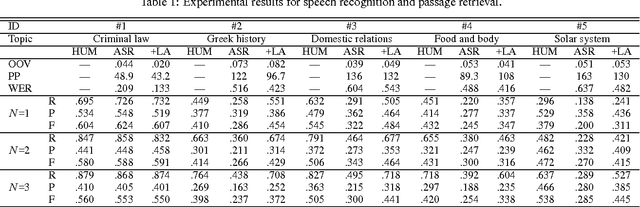
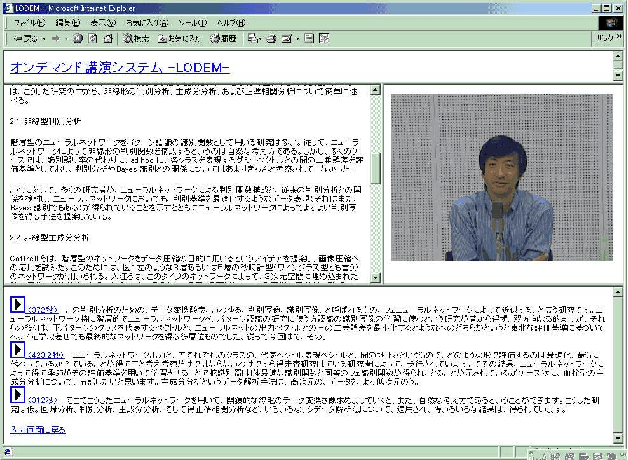
We propose a cross-media lecture-on-demand system, in which users can selectively view specific segments of lecture videos by submitting text queries. Users can easily formulate queries by using the textbook associated with a target lecture, even if they cannot come up with effective keywords. Our system extracts the audio track from a target lecture video, generates a transcription by large vocabulary continuous speech recognition, and produces a text index. Experimental results showed that by adapting speech recognition to the topic of the lecture, the recognition accuracy increased and the retrieval accuracy was comparable with that obtained by human transcription.
Speech-Driven Text Retrieval: Using Target IR Collections for Statistical Language Model Adaptation in Speech Recognition
Jun 24, 2002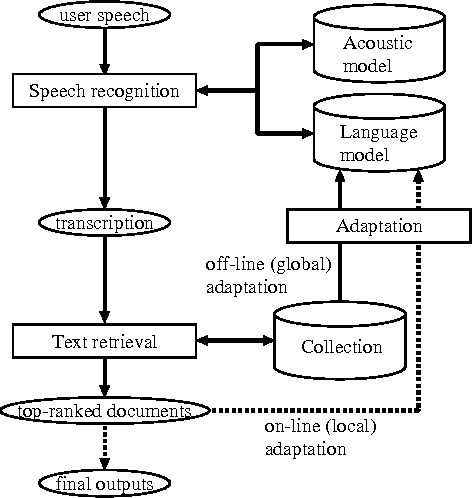

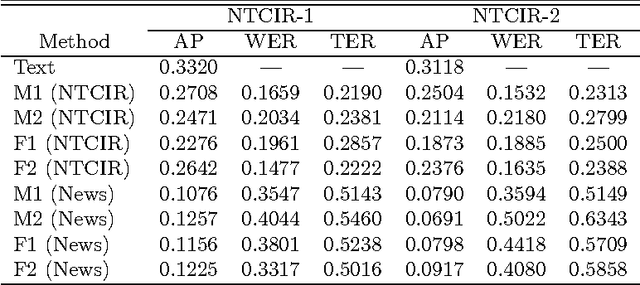
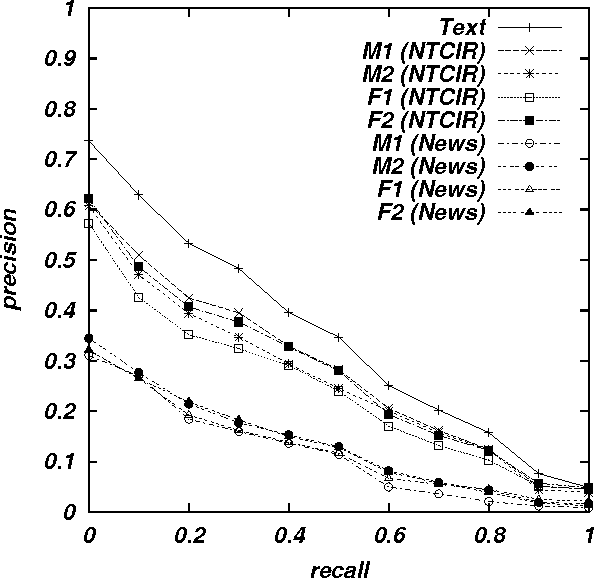
Speech recognition has of late become a practical technology for real world applications. Aiming at speech-driven text retrieval, which facilitates retrieving information with spoken queries, we propose a method to integrate speech recognition and retrieval methods. Since users speak contents related to a target collection, we adapt statistical language models used for speech recognition based on the target collection, so as to improve both the recognition and retrieval accuracy. Experiments using existing test collections combined with dictated queries showed the effectiveness of our method.
Language Modeling for Multi-Domain Speech-Driven Text Retrieval
Jun 24, 2002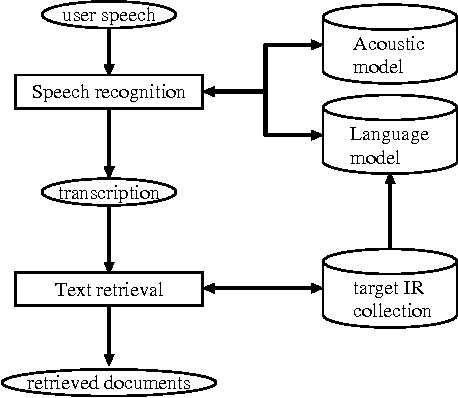
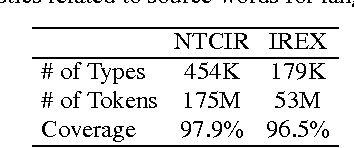

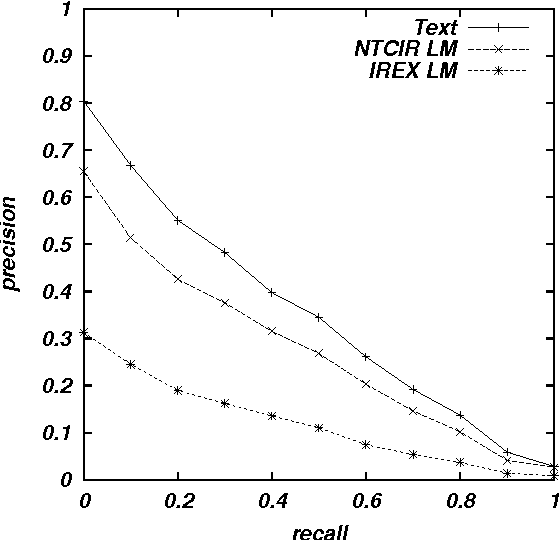
We report experimental results associated with speech-driven text retrieval, which facilitates retrieving information in multiple domains with spoken queries. Since users speak contents related to a target collection, we produce language models used for speech recognition based on the target collection, so as to improve both the recognition and retrieval accuracy. Experiments using existing test collections combined with dictated queries showed the effectiveness of our method.
PRIME: A System for Multi-lingual Patent Retrieval
Jun 24, 2002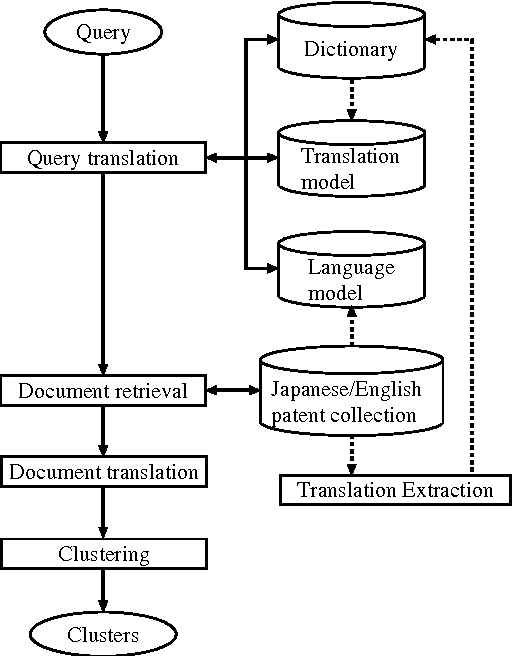
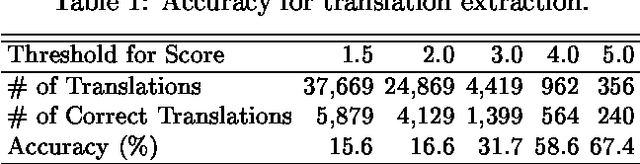
Given the growing number of patents filed in multiple countries, users are interested in retrieving patents across languages. We propose a multi-lingual patent retrieval system, which translates a user query into the target language, searches a multilingual database for patents relevant to the query, and improves the browsing efficiency by way of machine translation and clustering. Our system also extracts new translations from patent families consisting of comparable patents, to enhance the translation dictionary.
Applying a Hybrid Query Translation Method to Japanese/English Cross-Language Patent Retrieval
Jun 24, 2002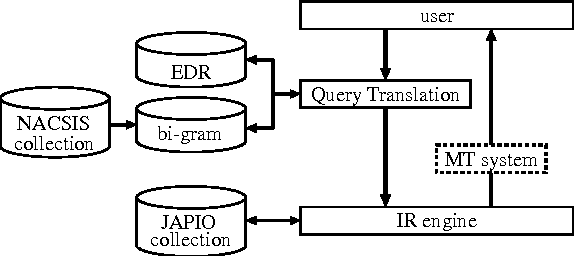


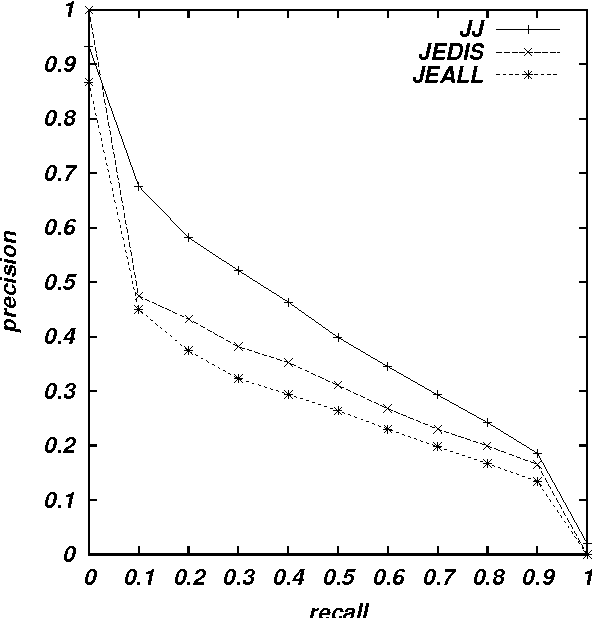
This paper applies an existing query translation method to cross-language patent retrieval. In our method, multiple dictionaries are used to derive all possible translations for an input query, and collocational statistics are used to resolve translation ambiguity. We used Japanese/English parallel patent abstracts to perform comparative experiments, where our method outperformed a simple dictionary-based query translation method, and achieved 76% of monolingual retrieval in terms of average precision.
A Probabilistic Method for Analyzing Japanese Anaphora Integrating Zero Pronoun Detection and Resolution
Jun 20, 2002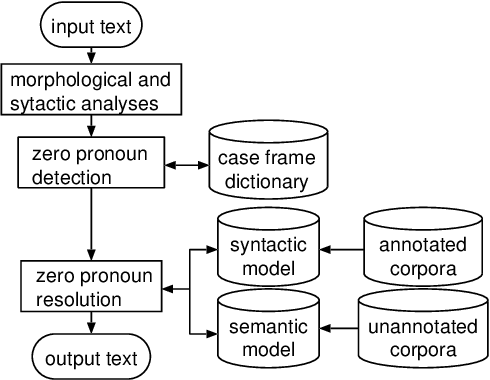

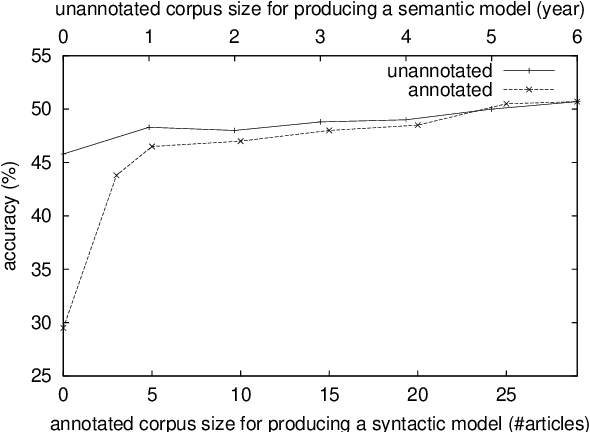
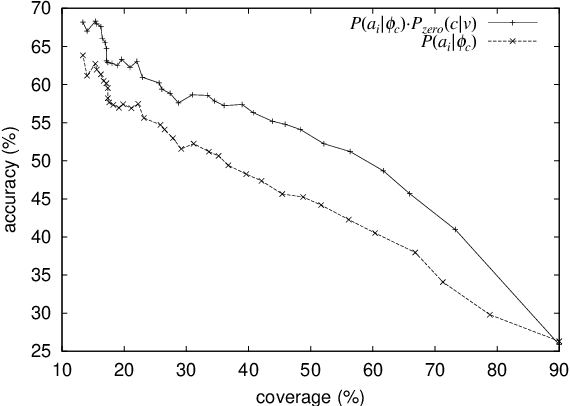
This paper proposes a method to analyze Japanese anaphora, in which zero pronouns (omitted obligatory cases) are used to refer to preceding entities (antecedents). Unlike the case of general coreference resolution, zero pronouns have to be detected prior to resolution because they are not expressed in discourse. Our method integrates two probability parameters to perform zero pronoun detection and resolution in a single framework. The first parameter quantifies the degree to which a given case is a zero pronoun. The second parameter quantifies the degree to which a given entity is the antecedent for a detected zero pronoun. To compute these parameters efficiently, we use corpora with/without annotations of anaphoric relations. We show the effectiveness of our method by way of experiments.
* Proceedings of the 19th International Conference on Computational Linguistics (To appear)
Japanese/English Cross-Language Information Retrieval: Exploration of Query Translation and Transliteration
Jun 09, 2002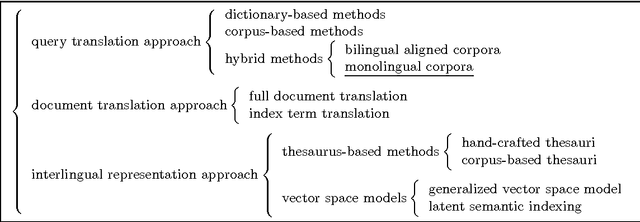

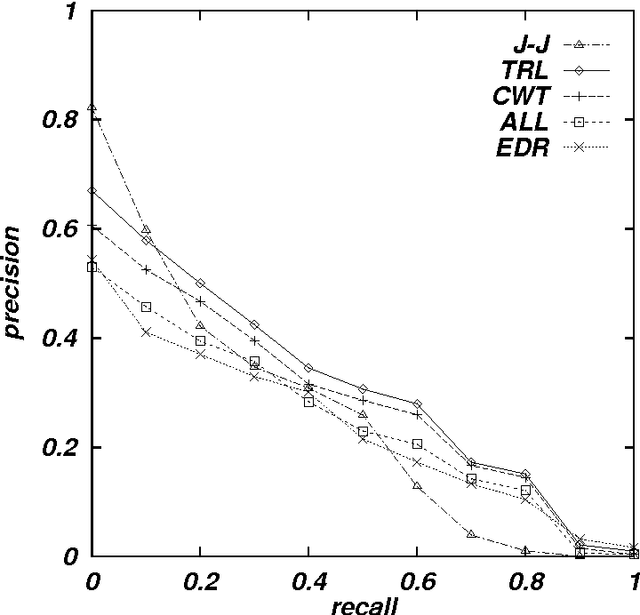
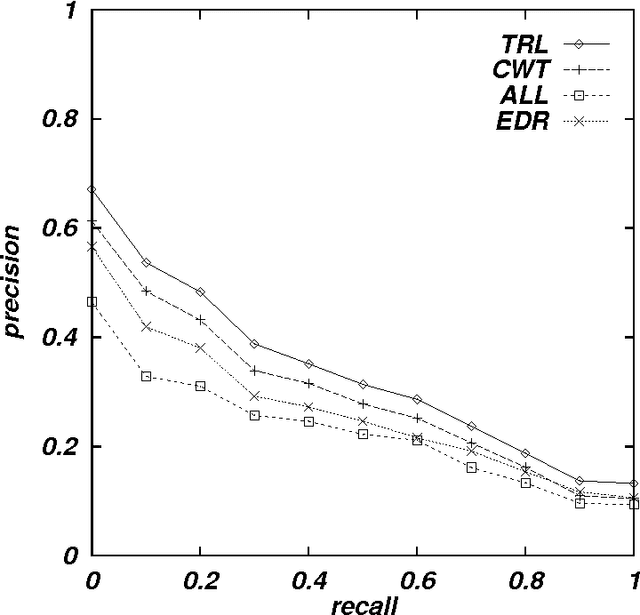
Cross-language information retrieval (CLIR), where queries and documents are in different languages, has of late become one of the major topics within the information retrieval community. This paper proposes a Japanese/English CLIR system, where we combine a query translation and retrieval modules. We currently target the retrieval of technical documents, and therefore the performance of our system is highly dependent on the quality of the translation of technical terms. However, the technical term translation is still problematic in that technical terms are often compound words, and thus new terms are progressively created by combining existing base words. In addition, Japanese often represents loanwords based on its special phonogram. Consequently, existing dictionaries find it difficult to achieve sufficient coverage. To counter the first problem, we produce a Japanese/English dictionary for base words, and translate compound words on a word-by-word basis. We also use a probabilistic method to resolve translation ambiguity. For the second problem, we use a transliteration method, which corresponds words unlisted in the base word dictionary to their phonetic equivalents in the target language. We evaluate our system using a test collection for CLIR, and show that both the compound word translation and transliteration methods improve the system performance.
A Method for Open-Vocabulary Speech-Driven Text Retrieval
Jun 09, 2002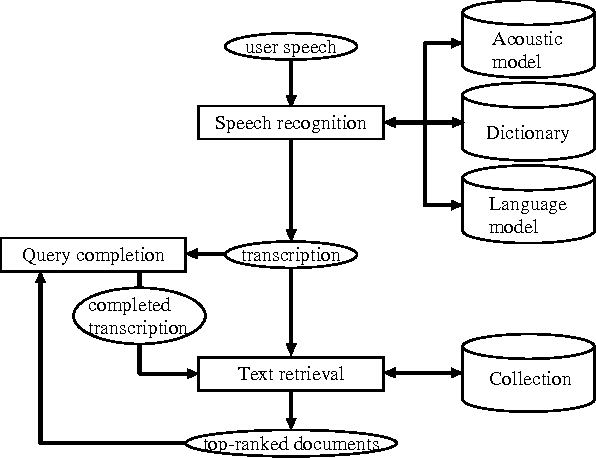
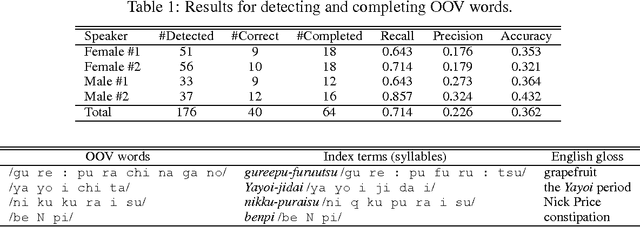
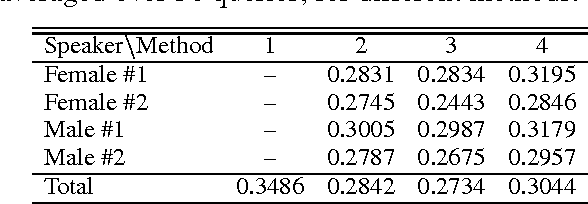
While recent retrieval techniques do not limit the number of index terms, out-of-vocabulary (OOV) words are crucial in speech recognition. Aiming at retrieving information with spoken queries, we fill the gap between speech recognition and text retrieval in terms of the vocabulary size. Given a spoken query, we generate a transcription and detect OOV words through speech recognition. We then correspond detected OOV words to terms indexed in a target collection to complete the transcription, and search the collection for documents relevant to the completed transcription. We show the effectiveness of our method by way of experiments.
* Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (To appear)