 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews-based Business Sentiment and its Properties as an Economic Index
Oct 20, 2021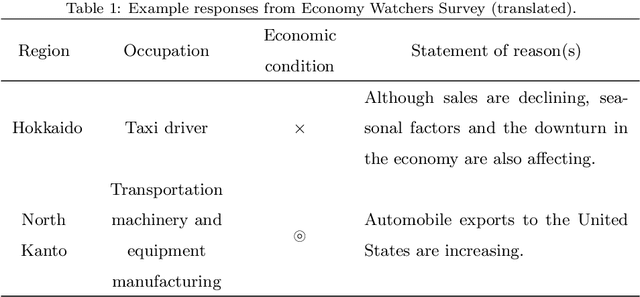

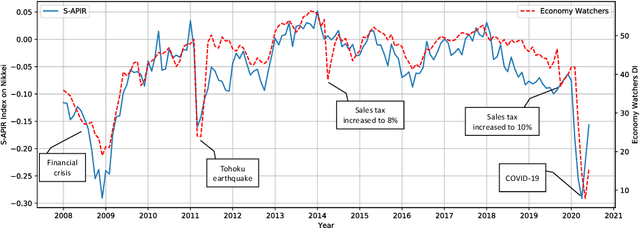
This paper presents an approach to measuring business sentiment based on textual data. Business sentiment has been measured by traditional surveys, which are costly and time-consuming to conduct. To address the issues, we take advantage of daily newspaper articles and adopt a self-attention-based model to define a business sentiment index, named S-APIR, where outlier detection models are investigated to properly handle various genres of news articles. Moreover, we propose a simple approach to temporally analyzing how much any given event contributed to the predicted business sentiment index. To demonstrate the validity of the proposed approach, an extensive analysis is carried out on 12 years' worth of newspaper articles. The analysis shows that the S-APIR index is strongly and positively correlated with established survey-based index (up to correlation coefficient r=0.937) and that the outlier detection is effective especially for a general newspaper. Also, S-APIR is compared with a variety of economic indices, revealing the properties of S-APIR that it reflects the trend of the macroeconomy as well as the economic outlook and sentiment of economic agents. Moreover, to illustrate how S-APIR could benefit economists and policymakers, several events are analyzed with respect to their impacts on business sentiment over time.
S-APIR: News-based Business Sentiment Index
Mar 06, 2020
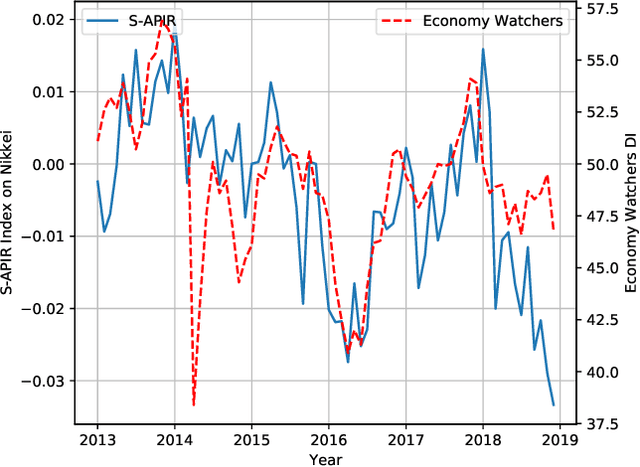


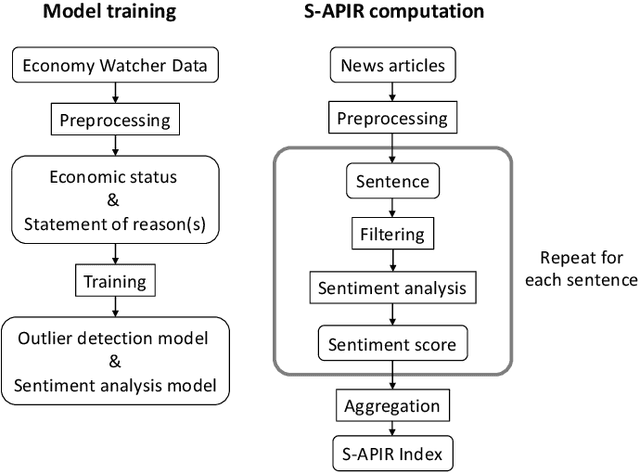
This paper describes our work on developing a new business sentiment index using daily newspaper articles. We adopt a recurrent neural network (RNN) with Gated Recurrent Units to predict the business sentiment of a given text. An RNN is initially trained on Economy Watchers Survey and then fine-tuned on news texts for domain adaptation. Also, a one-class support vector machine is applied to filter out texts deemed irrelevant to business sentiment. Moreover, we propose a simple approach to temporally analyzing how much and when any given factor influences the predicted business sentiment. The validity and utility of the proposed approaches are empirically demonstrated through a series of experiments on Nikkei Newspaper articles published from 2013 to 2018.
Semantic Web Today: From Oil Rigs to Panama Papers
Nov 05, 2017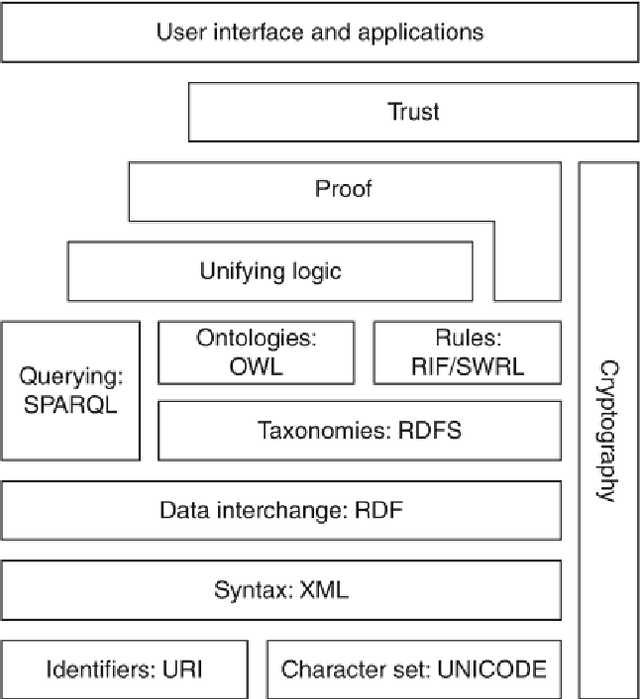

The next leap on the internet has already started as Semantic Web. At its core, Semantic Web transforms the document oriented web to a data oriented web enriched with semantics embedded as metadata. This change in perspective towards the web offers numerous benefits for vast amount of data intensive industries that are bound to the web and its related applications. The industries are diverse as they range from Oil & Gas exploration to the investigative journalism, and everything in between. This paper discusses eight different industries which currently reap the benefits of Semantic Web. The paper also offers a future outlook into Semantic Web applications and discusses the areas in which Semantic Web would play a key role in the future.
A Probabilistic Method for Analyzing Japanese Anaphora Integrating Zero Pronoun Detection and Resolution
Jun 20, 2002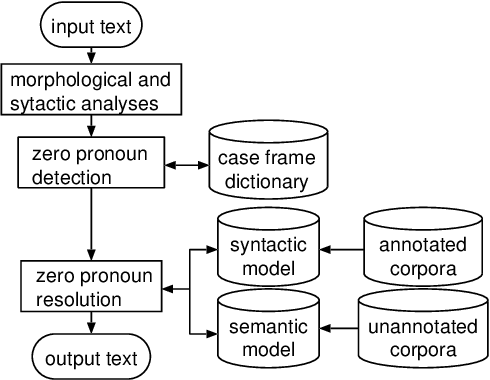

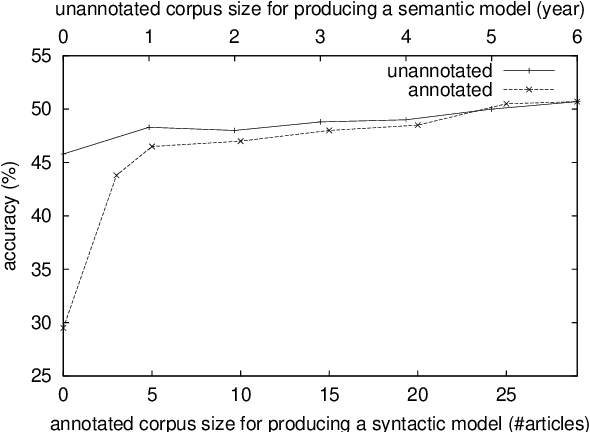
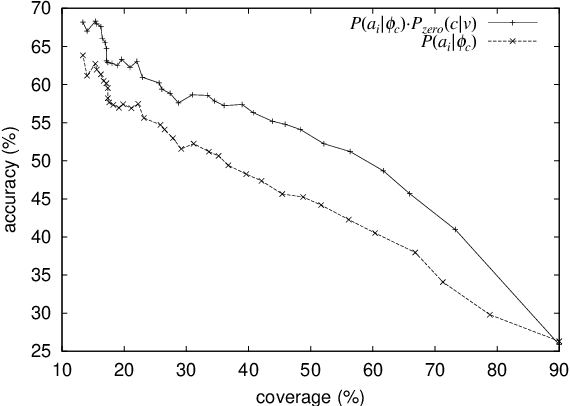
This paper proposes a method to analyze Japanese anaphora, in which zero pronouns (omitted obligatory cases) are used to refer to preceding entities (antecedents). Unlike the case of general coreference resolution, zero pronouns have to be detected prior to resolution because they are not expressed in discourse. Our method integrates two probability parameters to perform zero pronoun detection and resolution in a single framework. The first parameter quantifies the degree to which a given case is a zero pronoun. The second parameter quantifies the degree to which a given entity is the antecedent for a detected zero pronoun. To compute these parameters efficiently, we use corpora with/without annotations of anaphoric relations. We show the effectiveness of our method by way of experiments.
* Proceedings of the 19th International Conference on Computational Linguistics (To appear)