Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Topic Adaptation for Lecture Speech Retrieval
Paper and Code
Jul 10, 2004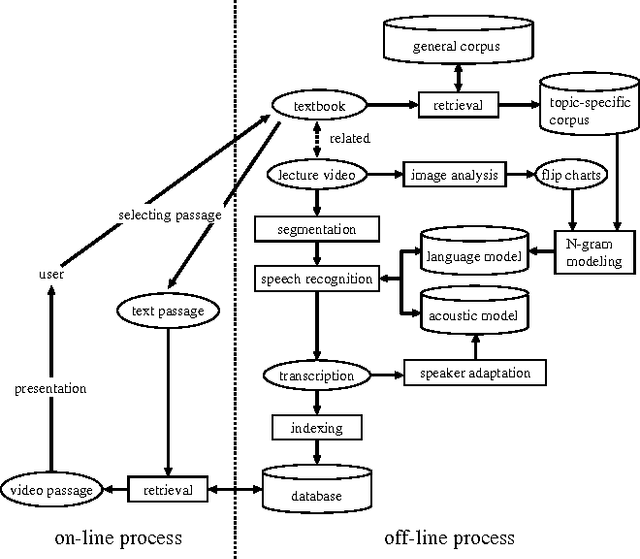

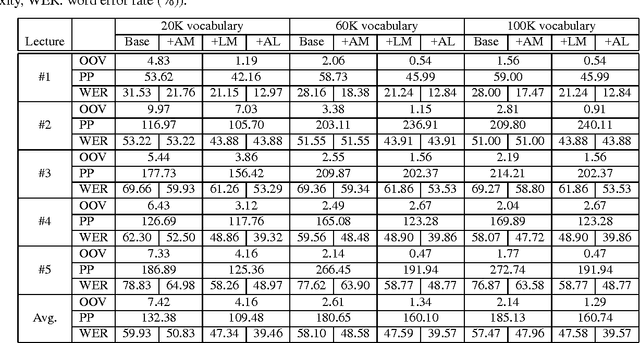
We are developing a cross-media information retrieval system, in which users can view specific segments of lecture videos by submitting text queries. To produce a text index, the audio track is extracted from a lecture video and a transcription is generated by automatic speech recognition. In this paper, to improve the quality of our retrieval system, we extensively investigate the effects of adapting acoustic and language models on speech recognition. We perform an MLLR-based method to adapt an acoustic model. To obtain a corpus for language model adaptation, we use the textbook for a target lecture to search a Web collection for the pages associated with the lecture topic. We show the effectiveness of our method by means of experiments.
* Proceedings of the 8th International Conference on Spoken Language
Processing (ICSLP 2004), pp.2957-2960, Oct. 2004 * 4 pages, Proceedings of the 8th International Conference on Spoken
Language Processing (to appear)
View paper on