 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Multi-Task and Multi-Corpora Training Strategies to Enhance Argumentative Sentence Linking Performance
Sep 27, 2021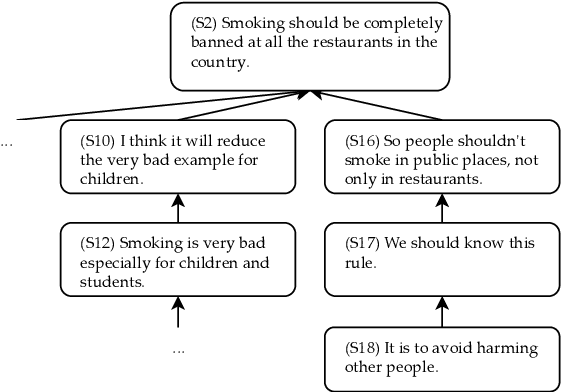
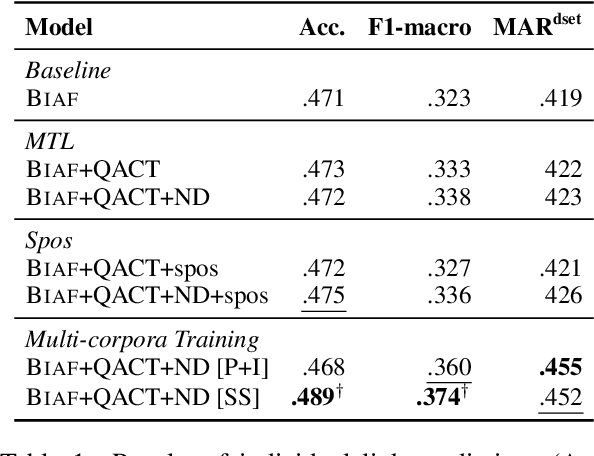
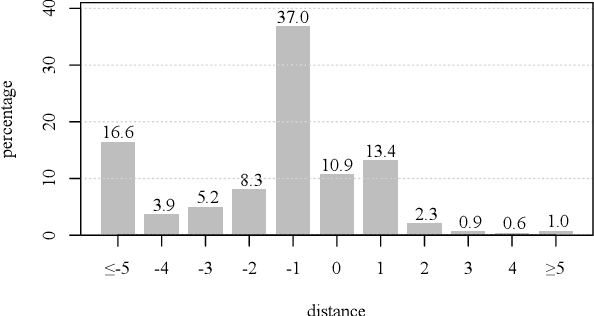
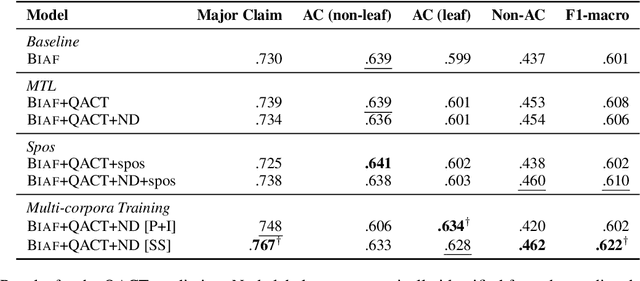
Argumentative structure prediction aims to establish links between textual units and label the relationship between them, forming a structured representation for a given input text. The former task, linking, has been identified by earlier works as particularly challenging, as it requires finding the most appropriate structure out of a very large search space of possible link combinations. In this paper, we improve a state-of-the-art linking model by using multi-task and multi-corpora training strategies. Our auxiliary tasks help the model to learn the role of each sentence in the argumentative structure. Combining multi-corpora training with a selective sampling strategy increases the training data size while ensuring that the model still learns the desired target distribution well. Experiments on essays written by English-as-a-foreign-language learners show that both strategies significantly improve the model's performance; for instance, we observe a 15.8% increase in the F1-macro for individual link predictions.