 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsect-Scale Tailless Robot with Flapping Wings: A Simple Structure and Drive for Yaw Control
Jul 09, 2024



Insect-scale micro-aerial vehicles, especially, lightweight, flapping-wing robots, are becoming increasingly important for safe motion sensing in spatially constrained environments such as living spaces. However, yaw control using flapping wings is fundamentally more difficult than using rotating wings. In this study, an insect-scale, tailless robot with four paired tilted flapping wings (weighing 1.52 g) to enable yaw control was fabricated. It benefits from the simplicity of a directly driven wing actuator with no transmission and a lift control signal; however, it still has an offset in the lift force. Therefore, an adaptive controller was designed to alleviate the offset. Numerical experiments confirm that the proposed controller outperforms the linear quadratic integral controller. Finally, in a tethered and controlled demonstration flight, the yaw drift was suppressed by the wing-tilting arrangement and the proposed controller. The simple structure drive system demonstrates the potential for future controlled flights of battery-powered, tailless, flapping-wing robots weighing less than 10 grams.
Reinforcement Learning of Multi-robot Task Allocation for Multi-object Transportation with Infeasible Tasks
Apr 18, 2024Multi-object transport using multi-robot systems has the potential for diverse practical applications such as delivery services owing to its efficient individual and scalable cooperative transport. However, allocating transportation tasks of objects with unknown weights remains challenging. Moreover, the presence of infeasible tasks (untransportable objects) can lead to robot stoppage (deadlock). This paper proposes a framework for dynamic task allocation that involves storing task experiences for each task in a scalable manner with respect to the number of robots. First, these experiences are broadcasted from the cloud server to the entire robot system. Subsequently, each robot learns the exclusion levels for each task based on those task experiences, enabling it to exclude infeasible tasks and reset its task priorities. Finally, individual transportation, cooperative transportation, and the temporary exclusion of tasks considered infeasible are achieved. The scalability and versatility of the proposed method were confirmed through numerical experiments with an increased number of robots and objects, including unlearned weight objects. The effectiveness of the temporary deadlock avoidance was also confirmed by introducing additional robots within an episode. The proposed method enables the implementation of task allocation strategies that are feasible for different numbers of robots and various transport tasks without prior consideration of feasibility.
Task-priority Intermediated Hierarchical Distributed Policies: Reinforcement Learning of Adaptive Multi-robot Cooperative Transport
Apr 02, 2024Multi-robot cooperative transport is crucial in logistics, housekeeping, and disaster response. However, it poses significant challenges in environments where objects of various weights are mixed and the number of robots and objects varies. This paper presents Task-priority Intermediated Hierarchical Distributed Policies (TIHDP), a multi-agent Reinforcement Learning (RL) framework that addresses these challenges through a hierarchical policy structure. TIHDP consists of three layers: task allocation policy (higher layer), dynamic task priority (intermediate layer), and robot control policy (lower layer). Whereas the dynamic task priority layer can manipulate the priority of any object to be transported by receiving global object information and communicating with other robots, the task allocation and robot control policies are restricted by local observations/actions so that they are not affected by changes in the number of objects and robots. Through simulations and real-robot demonstrations, TIHDP shows promising adaptability and performance of the learned multi-robot cooperative transport, even in environments with varying numbers of robots and objects. Video is available at https://youtu.be/Rmhv5ovj0xM
Imitation-regularized Optimal Transport on Networks: Provable Robustness and Application to Logistics Planning
Feb 28, 2024Network systems form the foundation of modern society, playing a critical role in various applications. However, these systems are at significant risk of being adversely affected by unforeseen circumstances, such as disasters. Considering this, there is a pressing need for research to enhance the robustness of network systems. Recently, in reinforcement learning, the relationship between acquiring robustness and regularizing entropy has been identified. Additionally, imitation learning is used within this framework to reflect experts' behavior. However, there are no comprehensive studies on the use of a similar imitation framework for optimal transport on networks. Therefore, in this study, imitation-regularized optimal transport (I-OT) on networks was investigated. It encodes prior knowledge on the network by imitating a given prior distribution. The I-OT solution demonstrated robustness in terms of the cost defined on the network. Moreover, we applied the I-OT to a logistics planning problem using real data. We also examined the imitation and apriori risk information scenarios to demonstrate the usefulness and implications of the proposed method.
Learning Locally, Communicating Globally: Reinforcement Learning of Multi-robot Task Allocation for Cooperative Transport
Dec 06, 2022



We consider task allocation for multi-object transport using a multi-robot system, in which each robot selects one object among multiple objects with different and unknown weights. The existing centralized methods assume the number of robots and tasks to be fixed, which is inapplicable to scenarios that differ from the learning environment. Meanwhile, the existing distributed methods limit the minimum number of robots and tasks to a constant value, making them applicable to various numbers of robots and tasks. However, they cannot transport an object whose weight exceeds the load capacity of robots observing the object. To make it applicable to various numbers of robots and objects with different and unknown weights, we propose a framework using multi-agent reinforcement learning for task allocation. First, we introduce a structured policy model consisting of 1) predesigned dynamic task priorities with global communication and 2) a neural network-based distributed policy model that determines the timing for coordination. The distributed policy builds consensus on the high-priority object under local observations and selects cooperative or independent actions. Then, the policy is optimized by multi-agent reinforcement learning through trial and error. This structured policy of local learning and global communication makes our framework applicable to various numbers of robots and objects with different and unknown weights, as demonstrated by numerical simulations.
Resilience Evaluation of Entropy Regularized Logistic Networks with Probabilistic Cost
Dec 05, 2022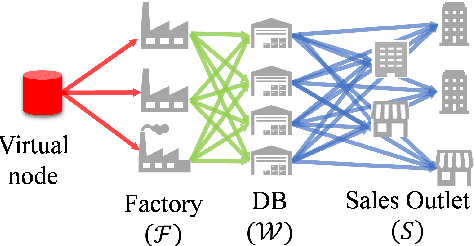
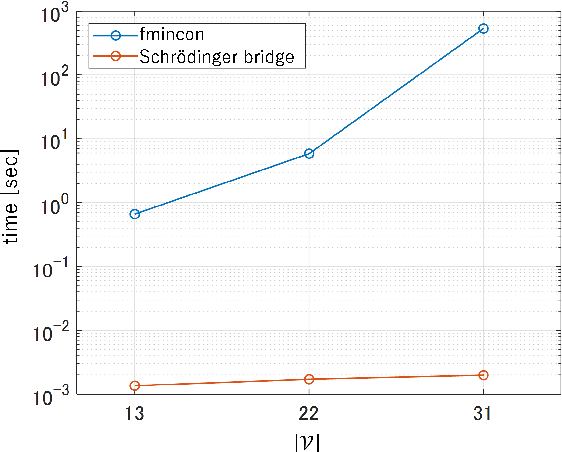
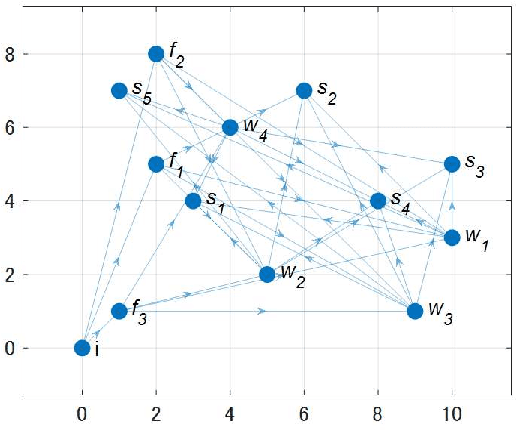
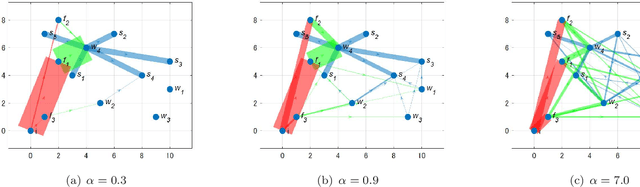
The demand for resilient logistics networks has increased because of recent disasters. When we consider optimization problems, entropy regularization is a powerful tool for the diversification of a solution. In this study, we proposed a method for designing a resilient logistics network based on entropy regularization. Moreover, we proposed a method for analytical resilience criteria to reduce the ambiguity of resilience. First, we modeled the logistics network, including factories, distribution bases, and sales outlets in an efficient framework using entropy regularization. Next, we formulated a resilience criterion based on probabilistic cost and Kullback--Leibler divergence. Finally, our method was performed using a simple logistics network, and the resilience of the three logistics plans designed by entropy regularization was demonstrated.
Deep reinforcement learning of event-triggered communication and consensus-based control for distributed cooperative transport
Dec 05, 2022



In this paper, we present a solution to a design problem of control strategies for multi-agent cooperative transport. Although existing learning-based methods assume that the number of agents is the same as that in the training environment, the number might differ in reality considering that the robots' batteries may completely discharge, or additional robots may be introduced to reduce the time required to complete a task. Therefore, it is crucial that the learned strategy be applicable to scenarios wherein the number of agents differs from that in the training environment. In this paper, we propose a novel multi-agent reinforcement learning framework of event-triggered communication and consensus-based control for distributed cooperative transport. The proposed policy model estimates the resultant force and torque in a consensus manner using the estimates of the resultant force and torque with the neighborhood agents. Moreover, it computes the control and communication inputs to determine when to communicate with the neighboring agents under local observations and estimates of the resultant force and torque. Therefore, the proposed framework can balance the control performance and communication savings in scenarios wherein the number of agents differs from that in the training environment. We confirm the effectiveness of our approach by using a maximum of eight and six robots in the simulations and experiments, respectively.
* 14 pages, 14 figures
Cooperative Transportation with Multiple Aerial Robots and Decentralized Control for Unknown Payloads
Nov 03, 2021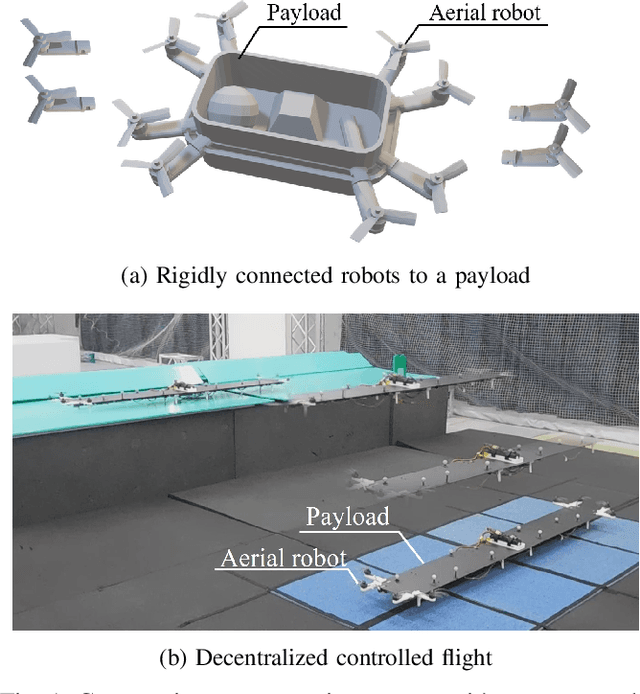
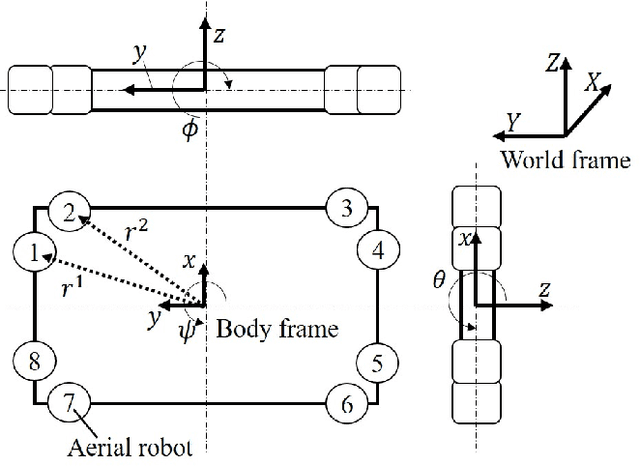
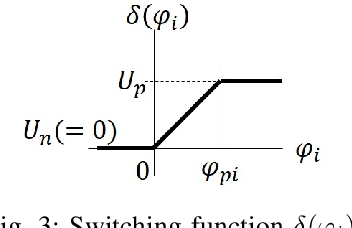
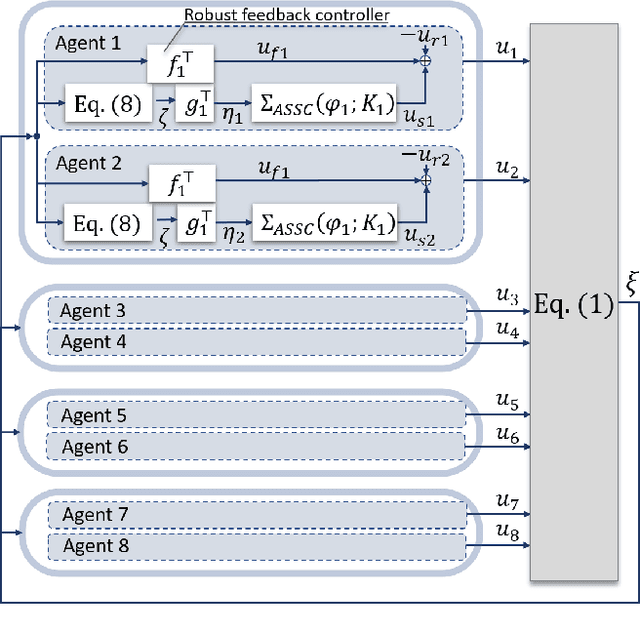
Cooperative transportation by multiple aerial robots has the potential to support various payloads and to reduce the chance of them being dropped. Furthermore, autonomously controlled robots make the system scalable with respect to the payload. In this study, a cooperative transportation system was developed using rigidly attached aerial robots, and a decentralized controller was proposed to guarantee asymptotic stability of the tracking error for unknown strictly positive real systems. A feedback controller was used to transform unstable systems into strictly positive real ones using the shared attachment positions. First, the cooperative transportation of unknown payloads with different shapes larger than the carrier robots was investigated through numerical simulations. Second, cooperative transportation of an unknown payload (with a weight of about 2.7 kg and maximum length of 1.6 m) was demonstrated using eight robots, even under robot failure. Finally, it was shown that the proposed system carried an unknown payload, even if the attachment positions were not shared, that is, even if the asymptotic stability was not strictly guaranteed.
Autonomous Cooperative Transportation System involving Multi-Aerial Robots with Variable Attachment Mechanism
Sep 22, 2021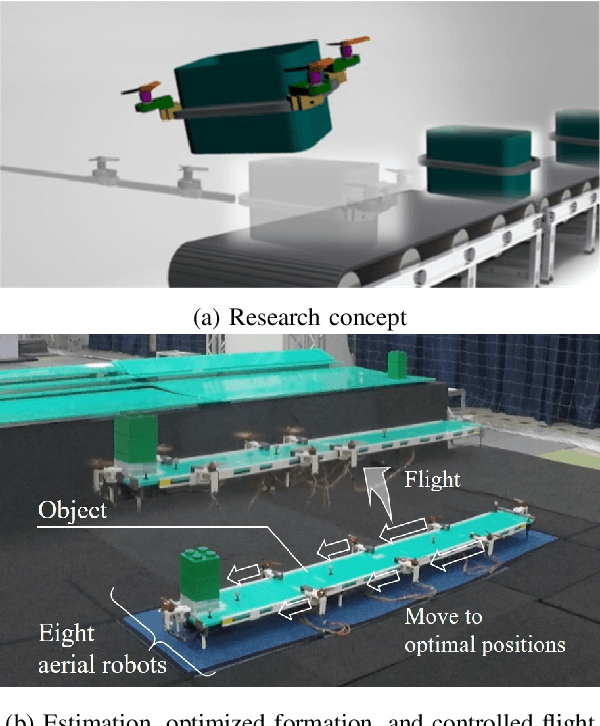
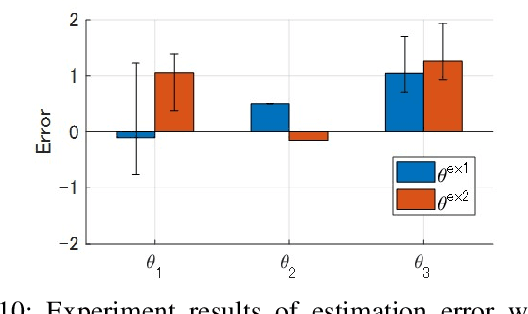

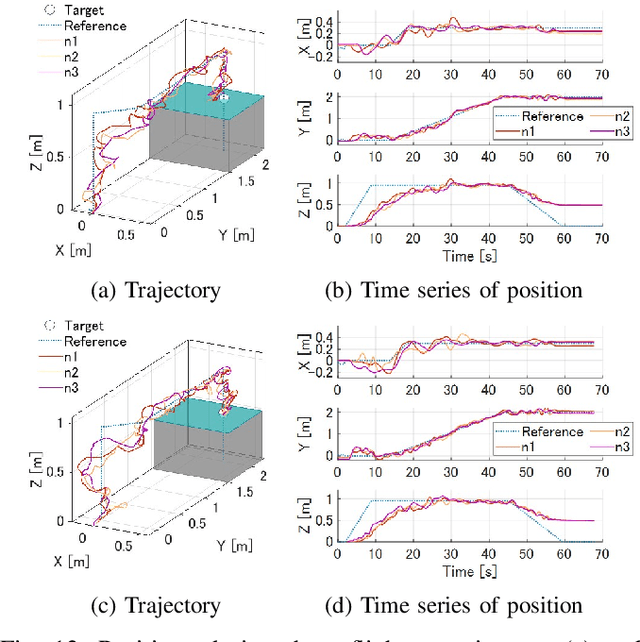
Cooperative transportation by multi-aerial robots has the potential to support various payloads and improve failsafe against dropping. Furthermore, changing the attachment positions of robots according payload characteristics increases the stability of transportation. However, there are almost no transportation systems capable of scaling to the payload weight and size and changing the optimal attachment positions. To address this issue, we propose a cooperative transportation system comprising autonomously executable software and suitable hardware, covering the entire process, from pre-takeoff setting to controlled flight. The proposed system decides the formation of the attachment positions by prioritizing controllability based on the center of gravity obtained from Bayesian estimations with robot pairs. We investigated the cooperative transportation of an unknown payload larger than that of whole carrier robots through numerical simulations. Furthermore, we performed cooperative transportation of an unknown payload (with a weight of about 3.2 kg and maximum length of 1.76 m) using eight robots. The proposed system was found to be versatile with regard to handling unknown payloads with different shapes and center-of-gravity positions.
Tracking Control foe Multi-Agent Systems Using Broadcast Signals Based on Positive Realness
Sep 14, 2021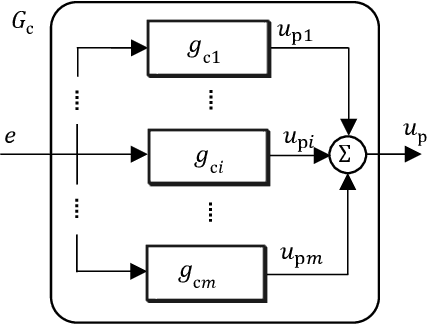
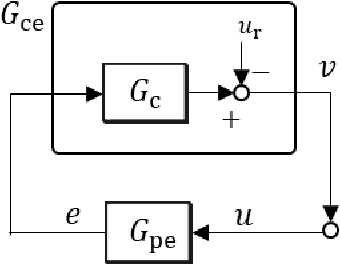
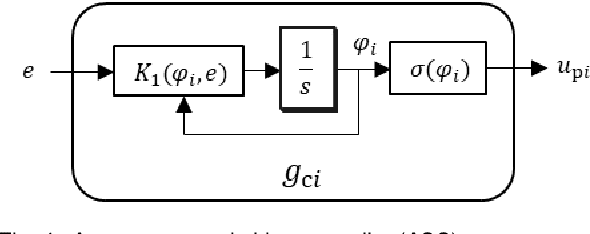
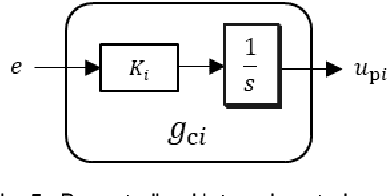
Broadcast control is one of decentralized control methods for networked multi-agent systems. In this method, each agent does not communicate with the others, and autonomously determines its own action using only the same signal sent from a central controller. Therefore, it is effective for systems with numerous agents or no-communication between agents. However, it is difficult to manage the stochastic action process of agents considering engineering applications. This paper proposes a decentralized control such that agents autonomously select the deterministic actions. Firstly, a non-linear controller with a binary output of each agent including 0 is introduced in order to express stop actions autonomously when the target is achieved. The asymptotic stability to the target is proved. Secondly, the controller can adjust the tendency of actions in order to make it easier to manage the actions. Thirdly, the controller is extended to that with a continuous output in order to reduce the tracking error to the target and the output vibration. Finally, the effectiveness of the proposed control is verified by numerical experiments.