 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Optimal Density Control of Linear Systems and Generalized Schrödinger Bridges with Reference Refinement
May 10, 2026We consider a mutual information (MI) regularized version of optimal density control of a discrete-time linear system. MI optimal control has been proposed as an extension of maximum entropy optimal control to trade off between control performance and benefits provided by stochastic inputs. MI regularization induces stochasticity in the policy, which poses challenges for applications of MI optimal control in safety-critical scenarios. To remedy this situation, we impose Gaussian density constraints at specified times to directly control state uncertainty. For this MI optimal density control problem, we propose an alternating optimization algorithm and derive the closed form of each step in the algorithm. In addition, we reveal that the alternating optimization of the MI optimal density control problem coincides with that of the so-called generalized Schrödinger bridge problem associated with the discrete-time linear system.
Globally Solving Unbalanced Optimal Transport and Density Control for Gaussian Distributions
May 05, 2026In this article, we study unbalanced optimal transport (UOT) and establish a control-theoretic dynamical extension, which we call the unbalanced density control (UDC), for a class of Gaussian reference measures. In the static setting, we consider UOT with quadratic transport cost and Kullback--Leibler penalties on the marginals relative to prescribed Gaussian measures. We show that the infinite-dimensional variational problem admits an exact Gaussian reduction, yielding a finite-dimensional optimization over masses, means, and covariances, together with a closed-form expression for the optimal transported mass. We then formulate UDC for discrete-time linear systems, where the initial and terminal state measures are imposed softly through KL penalties and the intermediate evolution is governed by controlled linear dynamics with quadratic control cost. For this problem, we prove that any feasible solution can be replaced, without loss of optimality, by a Gaussian initial measure and an affine-Gaussian control policy. This leads to an exact finite-dimensional reformulation and, after a standard covariance-steering lifting, to an SDP-based optimization for fixed mass, again coupled with a closed-form mass update. We further establish existence of optimal solutions and identify a sufficient condition under which the affine-Gaussian UDC policy is deterministic. These results provide globally optimal solution methods for both Gaussian UOT and Gaussian UDC. Finally, we illustrate our results with several numerical examples.
Convex Chance-Constrained Stochastic Control under Uncertain Specifications with Application to Learning-Based Hybrid Powertrain Control
Jan 26, 2026This paper presents a strictly convex chance-constrained stochastic control framework that accounts for uncertainty in control specifications such as reference trajectories and operational constraints. By jointly optimizing control inputs and risk allocation under general (possibly non-Gaussian) uncertainties, the proposed method guarantees probabilistic constraint satisfaction while ensuring strict convexity, leading to uniqueness and continuity of the optimal solution. The formulation is further extended to nonlinear model-based control using exactly linearizable models identified through machine learning. The effectiveness of the proposed approach is demonstrated through model predictive control applied to a hybrid powertrain system.
Robust maximum hands-off optimal control: existence, maximum principle, and $L^{0}$-$L^1$ equivalence
Jan 12, 2026This work advances the maximum hands-off sparse control framework by developing a robust counterpart for constrained linear systems with parametric uncertainties. The resulting optimal control problem minimizes an $L^{0}$ objective subject to an uncountable, compact family of constraints, and is therefore a nonconvex, nonsmooth robust optimization problem. To address this, we replace the $L^{0}$ objective with its convex $L^{1}$ surrogate and, using a nonsmooth variant of the robust Pontryagin maximum principle, show that the $L^{0}$ and $L^{1}$ formulations have identical sets of optimal solutions -- we call this the robust hands-off principle. Building on this equivalence, we propose an algorithmic framework -- drawing on numerically viable techniques from the semi-infinite robust optimization literature -- to solve the resulting problems. An illustrative example is provided to demonstrate the effectiveness of the approach.
Formation Shape Control using the Gromov-Wasserstein Metric
Mar 27, 2025
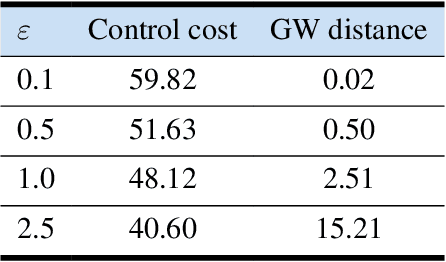
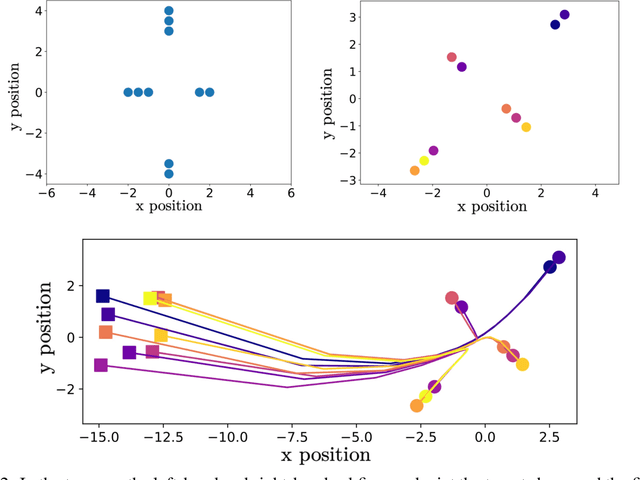
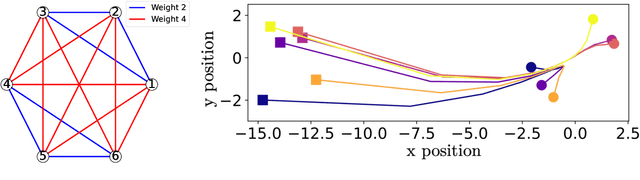
This article introduces a formation shape control algorithm, in the optimal control framework, for steering an initial population of agents to a desired configuration via employing the Gromov-Wasserstein distance. The underlying dynamical system is assumed to be a constrained linear system and the objective function is a sum of quadratic control-dependent stage cost and a Gromov-Wasserstein terminal cost. The inclusion of the Gromov-Wasserstein cost transforms the resulting optimal control problem into a well-known NP-hard problem, making it both numerically demanding and difficult to solve with high accuracy. Towards that end, we employ a recent semi-definite relaxation-driven technique to tackle the Gromov-Wasserstein distance. A numerical example is provided to illustrate our results.
Risk-sensitive control as inference with Rényi divergence
Nov 04, 2024This paper introduces the risk-sensitive control as inference (RCaI) that extends CaI by using R\'{e}nyi divergence variational inference. RCaI is shown to be equivalent to log-probability regularized risk-sensitive control, which is an extension of the maximum entropy (MaxEnt) control. We also prove that the risk-sensitive optimal policy can be obtained by solving a soft Bellman equation, which reveals several equivalences between RCaI, MaxEnt control, the optimal posterior for CaI, and linearly-solvable control. Moreover, based on RCaI, we derive the risk-sensitive reinforcement learning (RL) methods: the policy gradient and the soft actor-critic. As the risk-sensitivity parameter vanishes, we recover the risk-neutral CaI and RL, which means that RCaI is a unifying framework. Furthermore, we give another risk-sensitive generalization of the MaxEnt control using R\'{e}nyi entropy regularization. We show that in both of our extensions, the optimal policies have the same structure even though the derivations are very different.
Tsallis Entropy Regularization for Linearly Solvable MDP and Linear Quadratic Regulator
Mar 04, 2024Shannon entropy regularization is widely adopted in optimal control due to its ability to promote exploration and enhance robustness, e.g., maximum entropy reinforcement learning known as Soft Actor-Critic. In this paper, Tsallis entropy, which is a one-parameter extension of Shannon entropy, is used for the regularization of linearly solvable MDP and linear quadratic regulators. We derive the solution for these problems and demonstrate its usefulness in balancing between exploration and sparsity of the obtained control law.
Imitation-regularized Optimal Transport on Networks: Provable Robustness and Application to Logistics Planning
Feb 28, 2024Network systems form the foundation of modern society, playing a critical role in various applications. However, these systems are at significant risk of being adversely affected by unforeseen circumstances, such as disasters. Considering this, there is a pressing need for research to enhance the robustness of network systems. Recently, in reinforcement learning, the relationship between acquiring robustness and regularizing entropy has been identified. Additionally, imitation learning is used within this framework to reflect experts' behavior. However, there are no comprehensive studies on the use of a similar imitation framework for optimal transport on networks. Therefore, in this study, imitation-regularized optimal transport (I-OT) on networks was investigated. It encodes prior knowledge on the network by imitating a given prior distribution. The I-OT solution demonstrated robustness in terms of the cost defined on the network. Moreover, we applied the I-OT to a logistics planning problem using real data. We also examined the imitation and apriori risk information scenarios to demonstrate the usefulness and implications of the proposed method.
Learning Exactly Linearizable Deep Dynamics Models
Nov 30, 2023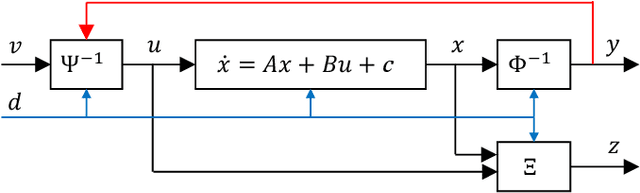
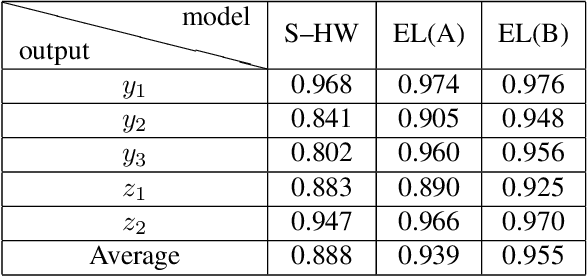
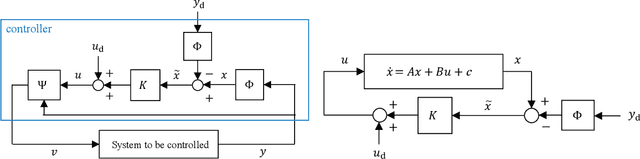
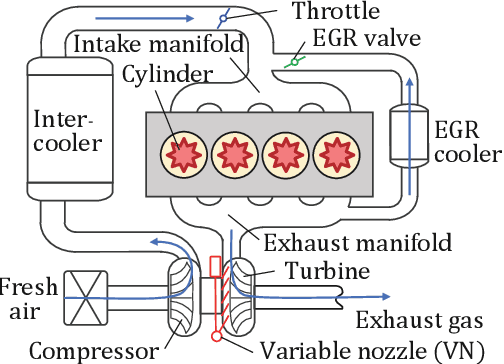
Research on control using models based on machine-learning methods has now shifted to the practical engineering stage. Achieving high performance and theoretically guaranteeing the safety of the system is critical for such applications. In this paper, we propose a learning method for exactly linearizable dynamical models that can easily apply various control theories to ensure stability, reliability, etc., and to provide a high degree of freedom of expression. As an example, we present a design that combines simple linear control and control barrier functions. The proposed model is employed for the real-time control of an automotive engine, and the results demonstrate good predictive performance and stable control under constraints.
Resilience Evaluation of Entropy Regularized Logistic Networks with Probabilistic Cost
Dec 05, 2022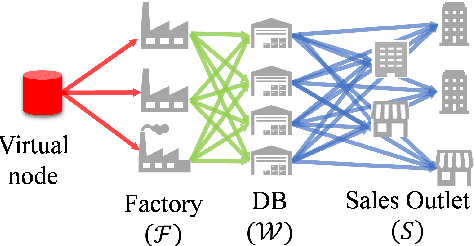
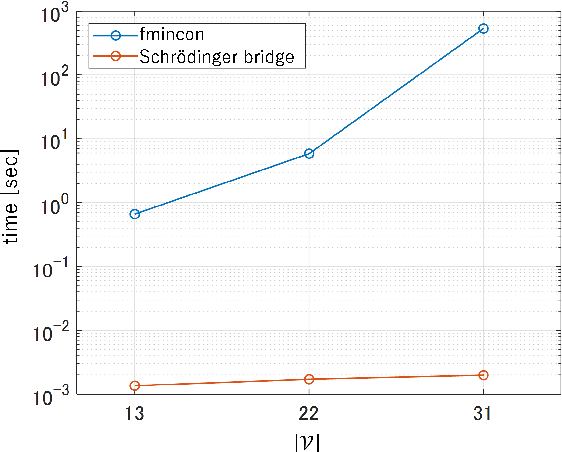
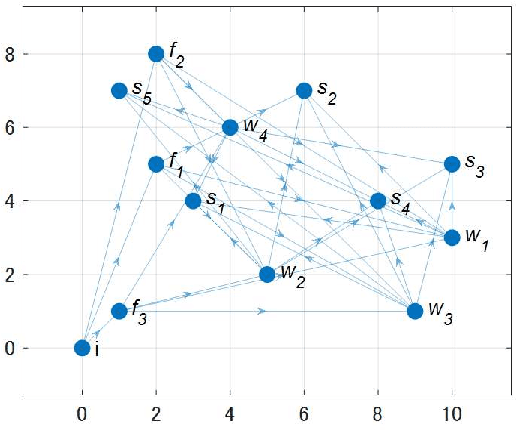
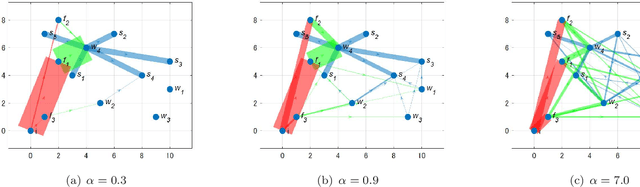
The demand for resilient logistics networks has increased because of recent disasters. When we consider optimization problems, entropy regularization is a powerful tool for the diversification of a solution. In this study, we proposed a method for designing a resilient logistics network based on entropy regularization. Moreover, we proposed a method for analytical resilience criteria to reduce the ambiguity of resilience. First, we modeled the logistics network, including factories, distribution bases, and sales outlets in an efficient framework using entropy regularization. Next, we formulated a resilience criterion based on probabilistic cost and Kullback--Leibler divergence. Finally, our method was performed using a simple logistics network, and the resilience of the three logistics plans designed by entropy regularization was demonstrated.