 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation-regularized Optimal Transport on Networks: Provable Robustness and Application to Logistics Planning
Feb 28, 2024Network systems form the foundation of modern society, playing a critical role in various applications. However, these systems are at significant risk of being adversely affected by unforeseen circumstances, such as disasters. Considering this, there is a pressing need for research to enhance the robustness of network systems. Recently, in reinforcement learning, the relationship between acquiring robustness and regularizing entropy has been identified. Additionally, imitation learning is used within this framework to reflect experts' behavior. However, there are no comprehensive studies on the use of a similar imitation framework for optimal transport on networks. Therefore, in this study, imitation-regularized optimal transport (I-OT) on networks was investigated. It encodes prior knowledge on the network by imitating a given prior distribution. The I-OT solution demonstrated robustness in terms of the cost defined on the network. Moreover, we applied the I-OT to a logistics planning problem using real data. We also examined the imitation and apriori risk information scenarios to demonstrate the usefulness and implications of the proposed method.
Resilience Evaluation of Entropy Regularized Logistic Networks with Probabilistic Cost
Dec 05, 2022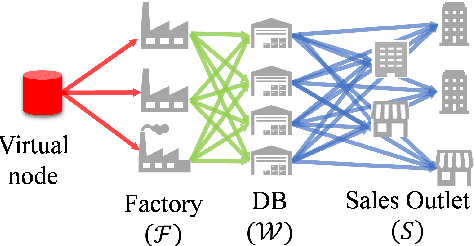
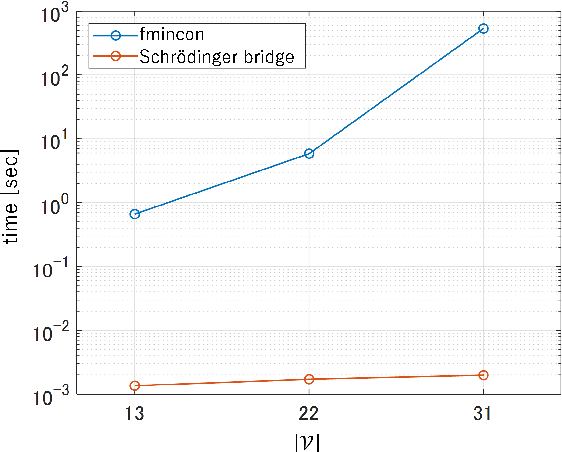
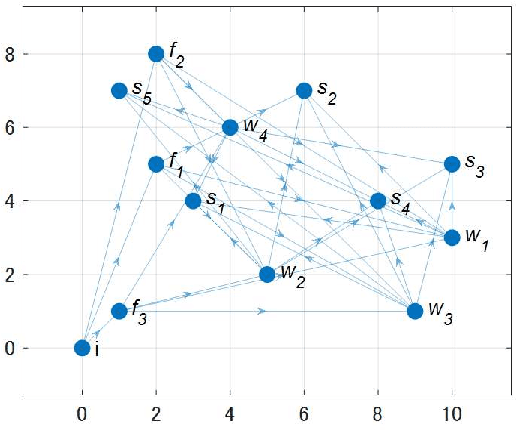
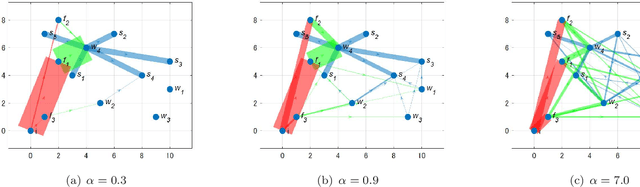
The demand for resilient logistics networks has increased because of recent disasters. When we consider optimization problems, entropy regularization is a powerful tool for the diversification of a solution. In this study, we proposed a method for designing a resilient logistics network based on entropy regularization. Moreover, we proposed a method for analytical resilience criteria to reduce the ambiguity of resilience. First, we modeled the logistics network, including factories, distribution bases, and sales outlets in an efficient framework using entropy regularization. Next, we formulated a resilience criterion based on probabilistic cost and Kullback--Leibler divergence. Finally, our method was performed using a simple logistics network, and the resilience of the three logistics plans designed by entropy regularization was demonstrated.
Binary Classification from Positive Data with Skewed Confidence
Jan 29, 2020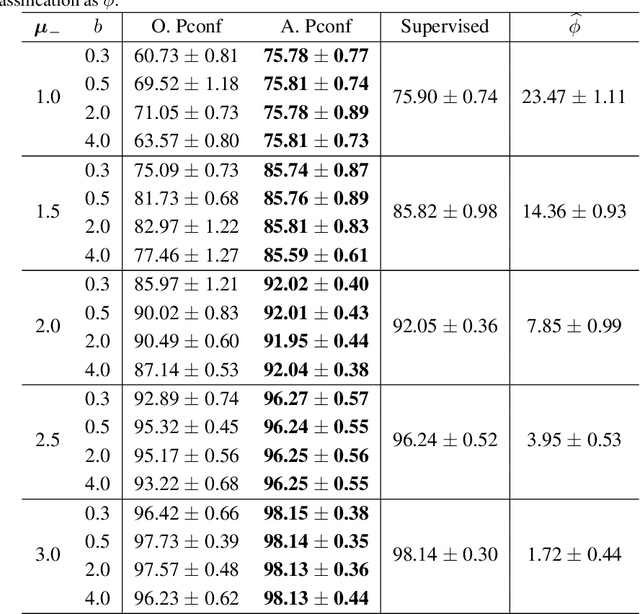
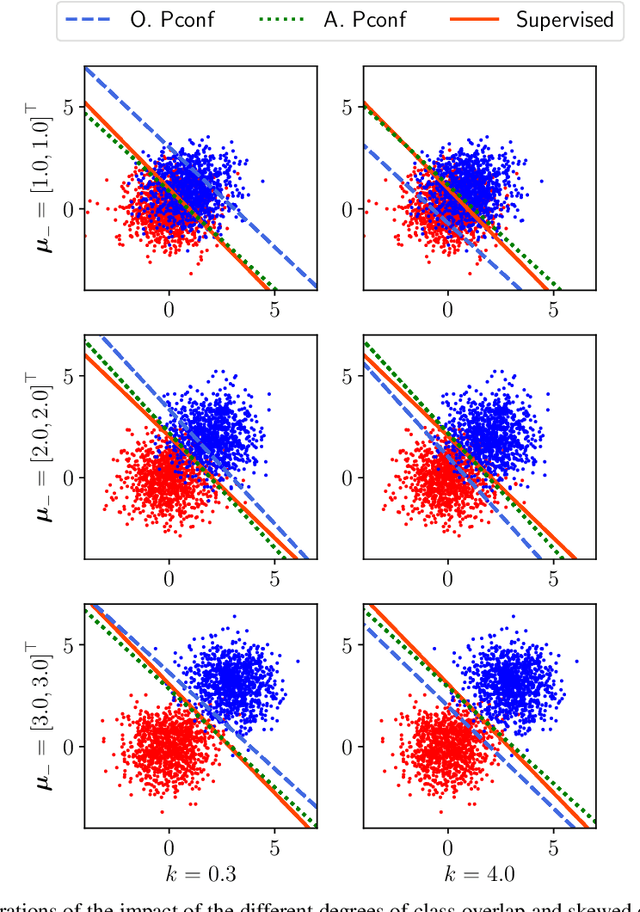
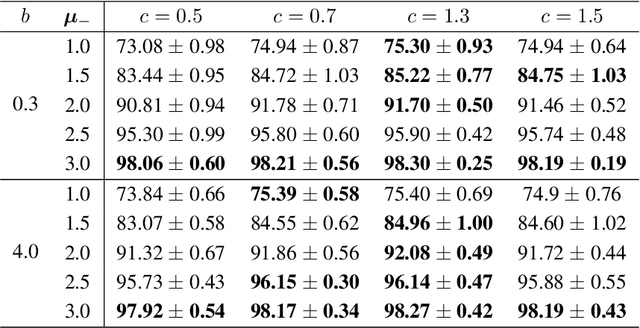

Positive-confidence (Pconf) classification [Ishida et al., 2018] is a promising weakly-supervised learning method which trains a binary classifier only from positive data equipped with confidence. However, in practice, the confidence may be skewed by bias arising in an annotation process. The Pconf classifier cannot be properly learned with skewed confidence, and consequently, the classification performance might be deteriorated. In this paper, we introduce the parameterized model of the skewed confidence, and propose the method for selecting the hyperparameter which cancels out the negative impact of skewed confidence under the assumption that we have the misclassification rate of positive samples as a prior knowledge. We demonstrate the effectiveness of the proposed method through a synthetic experiment with simple linear models and benchmark problems with neural network models. We also apply our method to drivers' drowsiness prediction to show that it works well with a real-world problem where confidence is obtained based on manual annotation.