 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Series Estimation for the Ratio of Conditional Expectation Functions
Dec 26, 2022In various fields of data science, researchers are often interested in estimating the ratio of conditional expectation functions (CEFR). Specifically in causal inference problems, it is sometimes natural to consider ratio-based treatment effects, such as odds ratios and hazard ratios, and even difference-based treatment effects are identified as CEFR in some empirically relevant settings. This chapter develops the general framework for estimation and inference on CEFR, which allows the use of flexible machine learning for infinite-dimensional nuisance parameters. In the first stage of the framework, the orthogonal signals are constructed using debiased machine learning techniques to mitigate the negative impacts of the regularization bias in the nuisance estimates on the target estimates. The signals are then combined with a novel series estimator tailored for CEFR. We derive the pointwise and uniform asymptotic results for estimation and inference on CEFR, including the validity of the Gaussian bootstrap, and provide low-level sufficient conditions to apply the proposed framework to some specific examples. We demonstrate the finite-sample performance of the series estimator constructed under the proposed framework by numerical simulations. Finally, we apply the proposed method to estimate the causal effect of the 401(k) program on household assets.
Estimation of Local Average Treatment Effect by Data Combination
Sep 11, 2021



It is important to estimate the local average treatment effect (LATE) when compliance with a treatment assignment is incomplete. The previously proposed methods for LATE estimation required all relevant variables to be jointly observed in a single dataset; however, it is sometimes difficult or even impossible to collect such data in many real-world problems for technical or privacy reasons. We consider a novel problem setting in which LATE, as a function of covariates, is nonparametrically identified from the combination of separately observed datasets. For estimation, we show that the direct least squares method, which was originally developed for estimating the average treatment effect under complete compliance, is applicable to our setting. However, model selection and hyperparameter tuning for the direct least squares estimator can be unstable in practice since it is defined as a solution to the minimax problem. We then propose a weighted least squares estimator that enables simpler model selection by avoiding the minimax objective formulation. Unlike the inverse probability weighted (IPW) estimator, the proposed estimator directly uses the pre-estimated weight without inversion, avoiding the problems caused by the IPW methods. We demonstrate the effectiveness of our method through experiments using synthetic and real-world datasets.
Binary Classification from Positive Data with Skewed Confidence
Jan 29, 2020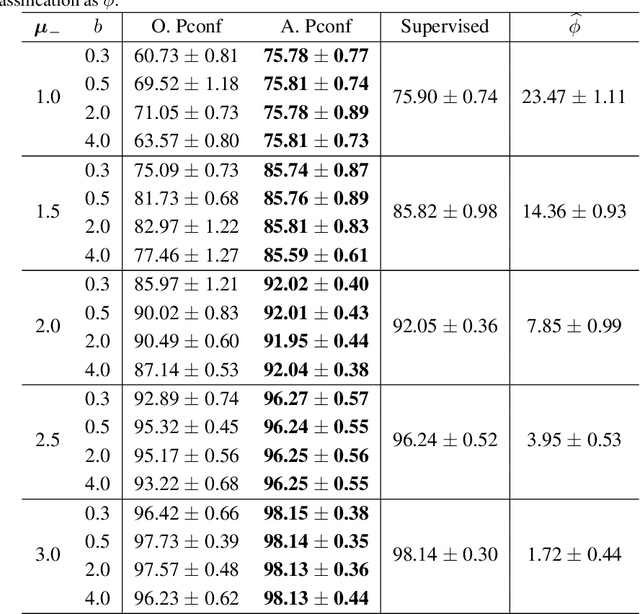
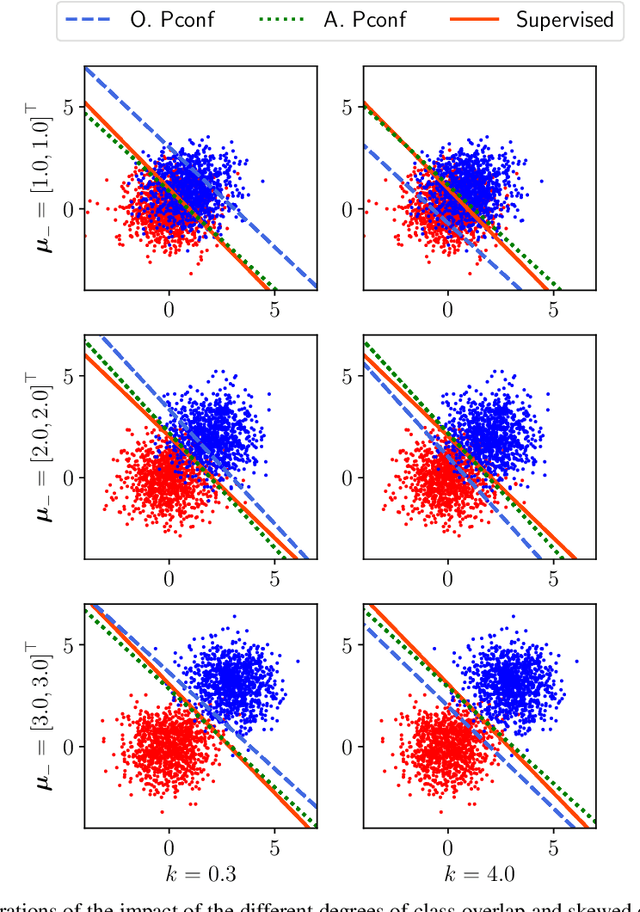
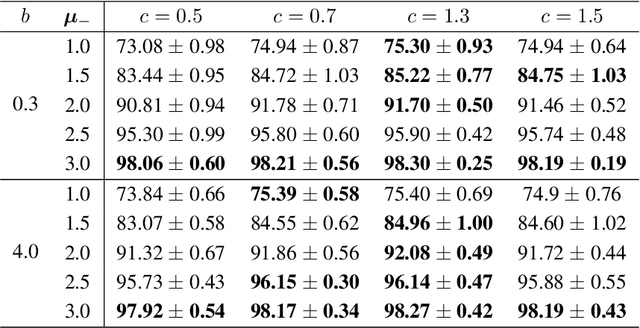

Positive-confidence (Pconf) classification [Ishida et al., 2018] is a promising weakly-supervised learning method which trains a binary classifier only from positive data equipped with confidence. However, in practice, the confidence may be skewed by bias arising in an annotation process. The Pconf classifier cannot be properly learned with skewed confidence, and consequently, the classification performance might be deteriorated. In this paper, we introduce the parameterized model of the skewed confidence, and propose the method for selecting the hyperparameter which cancels out the negative impact of skewed confidence under the assumption that we have the misclassification rate of positive samples as a prior knowledge. We demonstrate the effectiveness of the proposed method through a synthetic experiment with simple linear models and benchmark problems with neural network models. We also apply our method to drivers' drowsiness prediction to show that it works well with a real-world problem where confidence is obtained based on manual annotation.