 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIRECT: When and Where Should You Allocate Test-Time Compute in Embodied Planners?
Jun 10, 2026Vision-Language Models (VLMs) are increasingly deployed as high-level planners for embodied agents, with an emerging strategy of scaling test-time compute to improve capability. However, we observe that doing so increases latency, token usage, and FLOPs while yielding uneven, often diminishing gains in downstream success, limiting where embodied agents can be deployed. We argue that choosing when and where to spend test-time compute is central to bringing frontier performance to the real world. We introduce DIRECT, a routing framework that uses multimodal scene context to allocate compute per prompt, improving the success--cost Pareto frontier over fixed model selection. Across three dominant scaling axes, namely chain-of-thought depth, model size, and memory history, our experiments on VLABench and RoboMME show that test-time compute is not a uniform lever: different axes yield qualitatively distinct capability gains. We validate these insights on a physical Franka arm in a DROID setup spanning zero-shot manipulation and long-horizon chaining, where our router matches or exceeds a stronger model's success rate at up to 65% lower average latency. Ultimately, our results show that naively scaling test-time compute is wasteful, and that DIRECT can provide frontier-level embodied planning in robotic systems at a fraction of the cost. Project page can be found at jadee-dao.github.io/direct/.
LeLaN: Learning A Language-Conditioned Navigation Policy from In-the-Wild Videos
Oct 04, 2024The world is filled with a wide variety of objects. For robots to be useful, they need the ability to find arbitrary objects described by people. In this paper, we present LeLaN(Learning Language-conditioned Navigation policy), a novel approach that consumes unlabeled, action-free egocentric data to learn scalable, language-conditioned object navigation. Our framework, LeLaN leverages the semantic knowledge of large vision-language models, as well as robotic foundation models, to label in-the-wild data from a variety of indoor and outdoor environments. We label over 130 hours of data collected in real-world indoor and outdoor environments, including robot observations, YouTube video tours, and human walking data. Extensive experiments with over 1000 real-world trials show that our approach enables training a policy from unlabeled action-free videos that outperforms state-of-the-art robot navigation methods, while being capable of inference at 4 times their speed on edge compute. We open-source our models, datasets and provide supplementary videos on our project page (https://learning-language-navigation.github.io/).
SELFI: Autonomous Self-Improvement with Reinforcement Learning for Social Navigation
Mar 01, 2024Autonomous self-improving robots that interact and improve with experience are key to the real-world deployment of robotic systems. In this paper, we propose an online learning method, SELFI, that leverages online robot experience to rapidly fine-tune pre-trained control policies efficiently. SELFI applies online model-free reinforcement learning on top of offline model-based learning to bring out the best parts of both learning paradigms. Specifically, SELFI stabilizes the online learning process by incorporating the same model-based learning objective from offline pre-training into the Q-values learned with online model-free reinforcement learning. We evaluate SELFI in multiple real-world environments and report improvements in terms of collision avoidance, as well as more socially compliant behavior, measured by a human user study. SELFI enables us to quickly learn useful robotic behaviors with less human interventions such as pre-emptive behavior for the pedestrians, collision avoidance for small and transparent objects, and avoiding travel on uneven floor surfaces. We provide supplementary videos to demonstrate the performance of our fine-tuned policy on our project page.
NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
Oct 11, 2023



Robotic learning for navigation in unfamiliar environments needs to provide policies for both task-oriented navigation (i.e., reaching a goal that the robot has located), and task-agnostic exploration (i.e., searching for a goal in a novel setting). Typically, these roles are handled by separate models, for example by using subgoal proposals, planning, or separate navigation strategies. In this paper, we describe how we can train a single unified diffusion policy to handle both goal-directed navigation and goal-agnostic exploration, with the latter providing the ability to search novel environments, and the former providing the ability to reach a user-specified goal once it has been located. We show that this unified policy results in better overall performance when navigating to visually indicated goals in novel environments, as compared to approaches that use subgoal proposals from generative models, or prior methods based on latent variable models. We instantiate our method by using a large-scale Transformer-based policy trained on data from multiple ground robots, with a diffusion model decoder to flexibly handle both goal-conditioned and goal-agnostic navigation. Our experiments, conducted on a real-world mobile robot platform, show effective navigation in unseen environments in comparison with five alternative methods, and demonstrate significant improvements in performance and lower collision rates, despite utilizing smaller models than state-of-the-art approaches. For more videos, code, and pre-trained model checkpoints, see https://general-navigation-models.github.io/nomad/
ViNT: A Foundation Model for Visual Navigation
Jun 26, 2023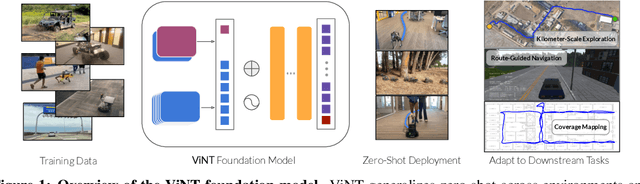
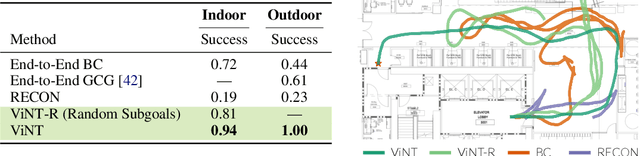
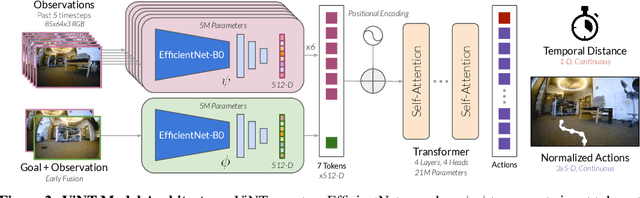

General-purpose pre-trained models ("foundation models") have enabled practitioners to produce generalizable solutions for individual machine learning problems with datasets that are significantly smaller than those required for learning from scratch. Such models are typically trained on large and diverse datasets with weak supervision, consuming much more training data than is available for any individual downstream application. In this paper, we describe the Visual Navigation Transformer (ViNT), a foundation model that aims to bring the success of general-purpose pre-trained models to vision-based robotic navigation. ViNT is trained with a general goal-reaching objective that can be used with any navigation dataset, and employs a flexible Transformer-based architecture to learn navigational affordances and enable efficient adaptation to a variety of downstream navigational tasks. ViNT is trained on a number of existing navigation datasets, comprising hundreds of hours of robotic navigation from a variety of different robotic platforms, and exhibits positive transfer, outperforming specialist models trained on singular datasets. ViNT can be augmented with diffusion-based subgoal proposals to explore novel environments, and can solve kilometer-scale navigation problems when equipped with long-range heuristics. ViNT can also be adapted to novel task specifications with a technique inspired by prompt-tuning, where the goal encoder is replaced by an encoding of another task modality (e.g., GPS waypoints or routing commands) embedded into the same space of goal tokens. This flexibility and ability to accommodate a variety of downstream problem domains establishes ViNT as an effective foundation model for mobile robotics. For videos, code, and model checkpoints, see our project page at https://visualnav-transformer.github.io.
SACSoN: Scalable Autonomous Data Collection for Social Navigation
Jun 02, 2023Machine learning provides a powerful tool for building socially compliant robotic systems that go beyond simple predictive models of human behavior. By observing and understanding human interactions from past experiences, learning can enable effective social navigation behaviors directly from data. However, collecting navigation data in human-occupied environments may require teleoperation or continuous monitoring, making the process prohibitively expensive to scale. In this paper, we present a scalable data collection system for vision-based navigation, SACSoN, that can autonomously navigate around pedestrians in challenging real-world environments while encouraging rich interactions. SACSoN uses visual observations to observe and react to humans in its vicinity. It couples this visual understanding with continual learning and an autonomous collision recovery system that limits the involvement of a human operator, allowing for better dataset scaling. We use a this system to collect the SACSoN dataset, the largest-of-its-kind visual navigation dataset of autonomous robots operating in human-occupied spaces, spanning over 75 hours and 4000 rich interactions with humans. Our experiments show that collecting data with a novel objective that encourages interactions, leads to significant improvements in downstream tasks such as inferring pedestrian dynamics and learning socially compliant navigation behaviors. We make videos of our autonomous data collection system and the SACSoN dataset publicly available on our project page.
ExAug: Robot-Conditioned Navigation Policies via Geometric Experience Augmentation
Oct 14, 2022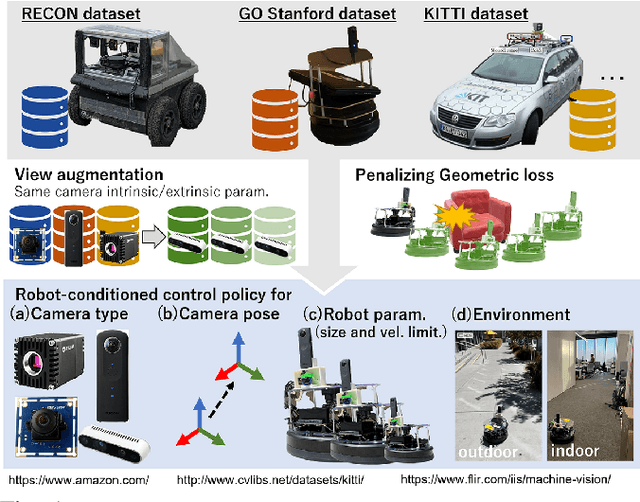
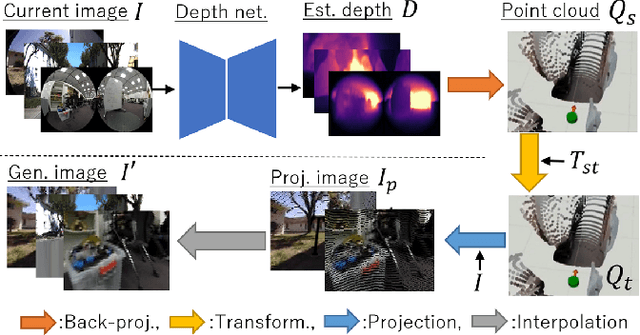
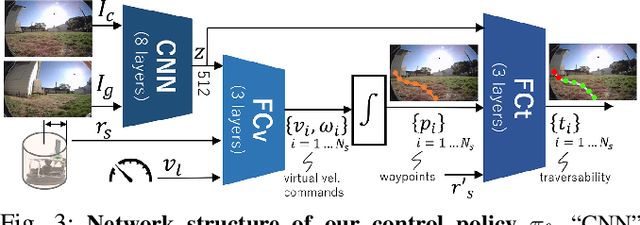

Machine learning techniques rely on large and diverse datasets for generalization. Computer vision, natural language processing, and other applications can often reuse public datasets to train many different models. However, due to differences in physical configurations, it is challenging to leverage public datasets for training robotic control policies on new robot platforms or for new tasks. In this work, we propose a novel framework, ExAug to augment the experiences of different robot platforms from multiple datasets in diverse environments. ExAug leverages a simple principle: by extracting 3D information in the form of a point cloud, we can create much more complex and structured augmentations, utilizing both generating synthetic images and geometric-aware penalization that would have been suitable in the same situation for a different robot, with different size, turning radius, and camera placement. The trained policy is evaluated on two new robot platforms with three different cameras in indoor and outdoor environments with obstacles.
GNM: A General Navigation Model to Drive Any Robot
Oct 07, 2022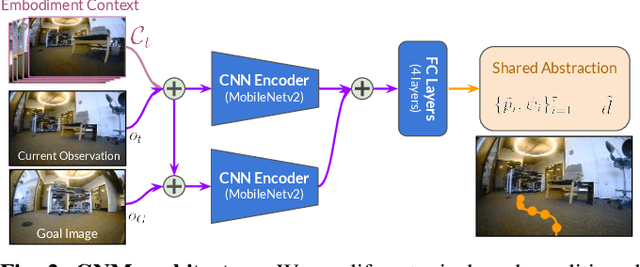

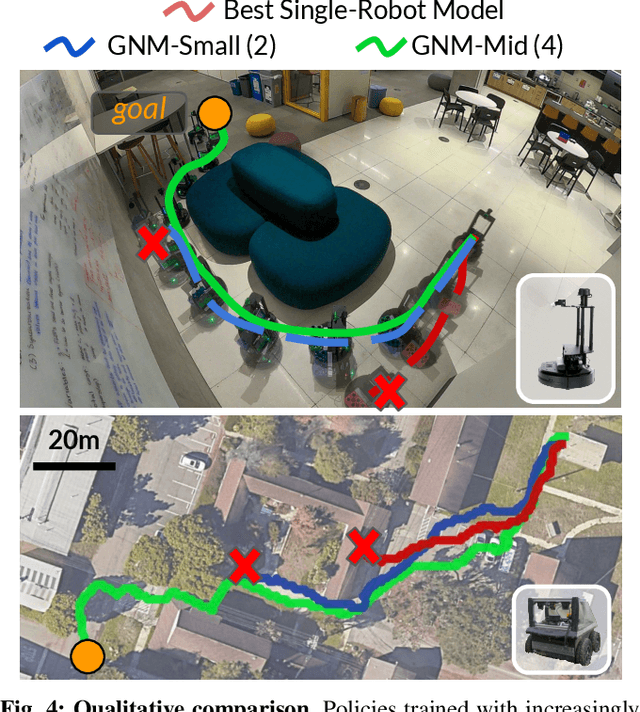
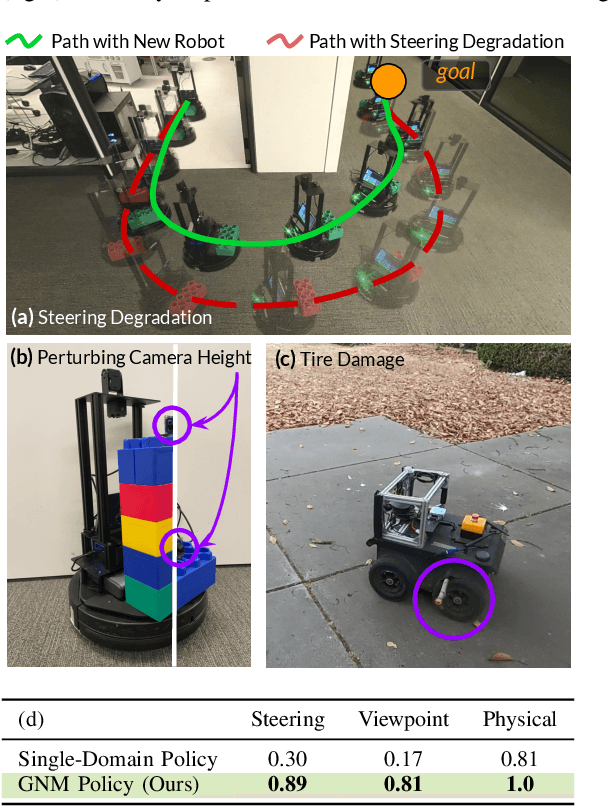
Learning provides a powerful tool for vision-based navigation, but the capabilities of learning-based policies are constrained by limited training data. If we could combine data from all available sources, including multiple kinds of robots, we could train more powerful navigation models. In this paper, we study how a general goal-conditioned model for vision-based navigation can be trained on data obtained from many distinct but structurally similar robots, and enable broad generalization across environments and embodiments. We analyze the necessary design decisions for effective data sharing across robots, including the use of temporal context and standardized action spaces, and demonstrate that an omnipolicy trained from heterogeneous datasets outperforms policies trained on any single dataset. We curate 60 hours of navigation trajectories from 6 distinct robots, and deploy the trained GNM on a range of new robots, including an underactuated quadrotor. We find that training on diverse data leads to robustness against degradation in sensing and actuation. Using a pre-trained navigation model with broad generalization capabilities can bootstrap applications on novel robots going forward, and we hope that the GNM represents a step in that direction. For more information on the datasets, code, and videos, please check out http://sites.google.com/view/drive-any-robot.