 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViNT: A Foundation Model for Visual Navigation
Paper and Code
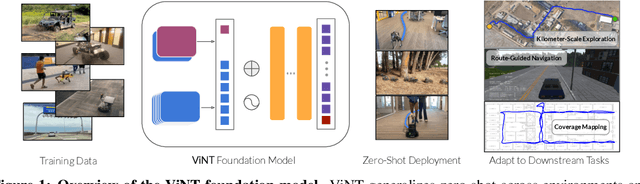
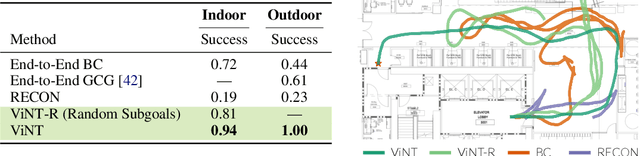
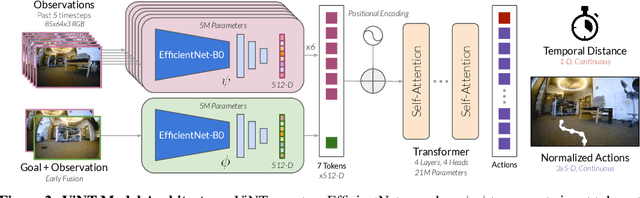

General-purpose pre-trained models ("foundation models") have enabled practitioners to produce generalizable solutions for individual machine learning problems with datasets that are significantly smaller than those required for learning from scratch. Such models are typically trained on large and diverse datasets with weak supervision, consuming much more training data than is available for any individual downstream application. In this paper, we describe the Visual Navigation Transformer (ViNT), a foundation model that aims to bring the success of general-purpose pre-trained models to vision-based robotic navigation. ViNT is trained with a general goal-reaching objective that can be used with any navigation dataset, and employs a flexible Transformer-based architecture to learn navigational affordances and enable efficient adaptation to a variety of downstream navigational tasks. ViNT is trained on a number of existing navigation datasets, comprising hundreds of hours of robotic navigation from a variety of different robotic platforms, and exhibits positive transfer, outperforming specialist models trained on singular datasets. ViNT can be augmented with diffusion-based subgoal proposals to explore novel environments, and can solve kilometer-scale navigation problems when equipped with long-range heuristics. ViNT can also be adapted to novel task specifications with a technique inspired by prompt-tuning, where the goal encoder is replaced by an encoding of another task modality (e.g., GPS waypoints or routing commands) embedded into the same space of goal tokens. This flexibility and ability to accommodate a variety of downstream problem domains establishes ViNT as an effective foundation model for mobile robotics. For videos, code, and model checkpoints, see our project page at https://visualnav-transformer.github.io.