 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViNT: A Foundation Model for Visual Navigation
Jun 26, 2023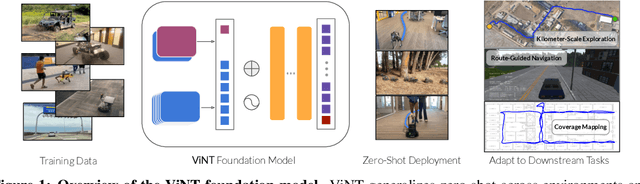
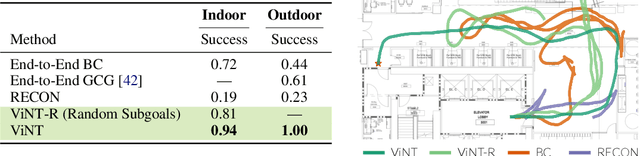
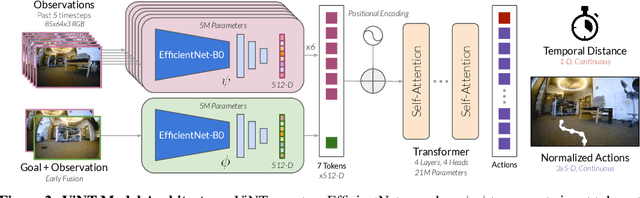

General-purpose pre-trained models ("foundation models") have enabled practitioners to produce generalizable solutions for individual machine learning problems with datasets that are significantly smaller than those required for learning from scratch. Such models are typically trained on large and diverse datasets with weak supervision, consuming much more training data than is available for any individual downstream application. In this paper, we describe the Visual Navigation Transformer (ViNT), a foundation model that aims to bring the success of general-purpose pre-trained models to vision-based robotic navigation. ViNT is trained with a general goal-reaching objective that can be used with any navigation dataset, and employs a flexible Transformer-based architecture to learn navigational affordances and enable efficient adaptation to a variety of downstream navigational tasks. ViNT is trained on a number of existing navigation datasets, comprising hundreds of hours of robotic navigation from a variety of different robotic platforms, and exhibits positive transfer, outperforming specialist models trained on singular datasets. ViNT can be augmented with diffusion-based subgoal proposals to explore novel environments, and can solve kilometer-scale navigation problems when equipped with long-range heuristics. ViNT can also be adapted to novel task specifications with a technique inspired by prompt-tuning, where the goal encoder is replaced by an encoding of another task modality (e.g., GPS waypoints or routing commands) embedded into the same space of goal tokens. This flexibility and ability to accommodate a variety of downstream problem domains establishes ViNT as an effective foundation model for mobile robotics. For videos, code, and model checkpoints, see our project page at https://visualnav-transformer.github.io.
Hybrid Imitative Planning with Geometric and Predictive Costs in Off-road Environments
Nov 22, 2021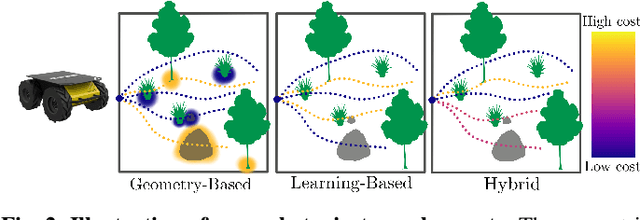
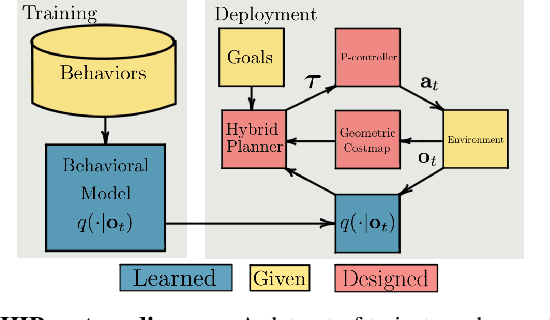
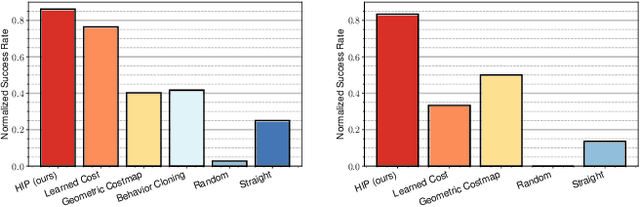

Geometric methods for solving open-world off-road navigation tasks, by learning occupancy and metric maps, provide good generalization but can be brittle in outdoor environments that violate their assumptions (e.g., tall grass). Learning-based methods can directly learn collision-free behavior from raw observations, but are difficult to integrate with standard geometry-based pipelines. This creates an unfortunate conflict -- either use learning and lose out on well-understood geometric navigational components, or do not use it, in favor of extensively hand-tuned geometry-based cost maps. In this work, we reject this dichotomy by designing the learning and non-learning-based components in a way such that they can be effectively combined in a self-supervised manner. Both components contribute to a planning criterion: the learned component contributes predicted traversability as rewards, while the geometric component contributes obstacle cost information. We instantiate and comparatively evaluate our system in both in-distribution and out-of-distribution environments, showing that this approach inherits complementary gains from the learned and geometric components and significantly outperforms either of them. Videos of our results are hosted at https://sites.google.com/view/hybrid-imitative-planning