 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Optimization Paradox in Clinical AI Multi-Agent Systems
Jun 06, 2025Multi-agent artificial intelligence systems are increasingly deployed in clinical settings, yet the relationship between component-level optimization and system-wide performance remains poorly understood. We evaluated this relationship using 2,400 real patient cases from the MIMIC-CDM dataset across four abdominal pathologies (appendicitis, pancreatitis, cholecystitis, diverticulitis), decomposing clinical diagnosis into information gathering, interpretation, and differential diagnosis. We evaluated single agent systems (one model performing all tasks) against multi-agent systems (specialized models for each task) using comprehensive metrics spanning diagnostic outcomes, process adherence, and cost efficiency. Our results reveal a paradox: while multi-agent systems generally outperformed single agents, the component-optimized or Best of Breed system with superior components and excellent process metrics (85.5% information accuracy) significantly underperformed in diagnostic accuracy (67.7% vs. 77.4% for a top multi-agent system). This finding underscores that successful integration of AI in healthcare requires not just component level optimization but also attention to information flow and compatibility between agents. Our findings highlight the need for end to end system validation rather than relying on component metrics alone.
Benchmarks and Algorithms for Offline Preference-Based Reward Learning
Jan 03, 2023



Learning a reward function from human preferences is challenging as it typically requires having a high-fidelity simulator or using expensive and potentially unsafe actual physical rollouts in the environment. However, in many tasks the agent might have access to offline data from related tasks in the same target environment. While offline data is increasingly being used to aid policy optimization via offline RL, our observation is that it can be a surprisingly rich source of information for preference learning as well. We propose an approach that uses an offline dataset to craft preference queries via pool-based active learning, learns a distribution over reward functions, and optimizes a corresponding policy via offline RL. Crucially, our proposed approach does not require actual physical rollouts or an accurate simulator for either the reward learning or policy optimization steps. To test our approach, we first evaluate existing offline RL benchmarks for their suitability for offline reward learning. Surprisingly, for many offline RL domains, we find that simply using a trivial reward function results good policy performance, making these domains ill-suited for evaluating learned rewards. To address this, we identify a subset of existing offline RL benchmarks that are well suited for offline reward learning and also propose new offline apprenticeship learning benchmarks which allow for more open-ended behaviors. When evaluated on this curated set of domains, our empirical results suggest that combining offline RL with learned human preferences can enable an agent to learn to perform novel tasks that were not explicitly shown in the offline data.
Hybrid Imitative Planning with Geometric and Predictive Costs in Off-road Environments
Nov 22, 2021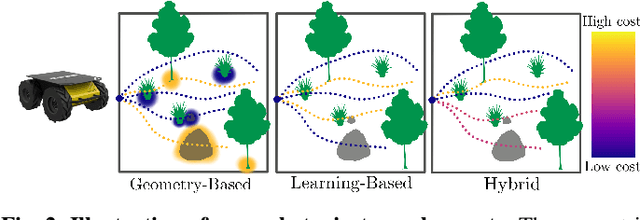
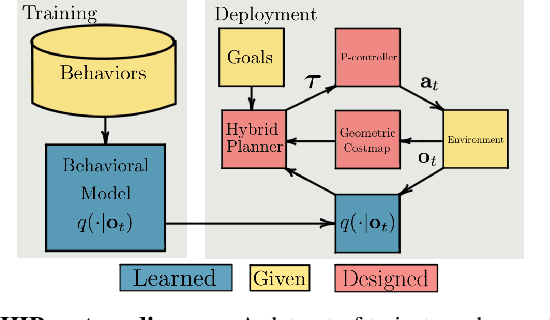
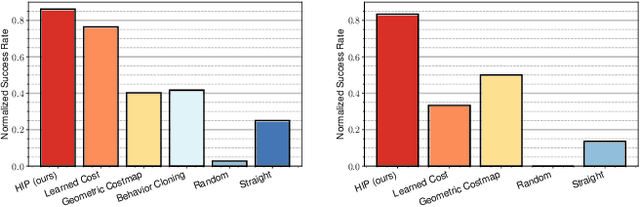

Geometric methods for solving open-world off-road navigation tasks, by learning occupancy and metric maps, provide good generalization but can be brittle in outdoor environments that violate their assumptions (e.g., tall grass). Learning-based methods can directly learn collision-free behavior from raw observations, but are difficult to integrate with standard geometry-based pipelines. This creates an unfortunate conflict -- either use learning and lose out on well-understood geometric navigational components, or do not use it, in favor of extensively hand-tuned geometry-based cost maps. In this work, we reject this dichotomy by designing the learning and non-learning-based components in a way such that they can be effectively combined in a self-supervised manner. Both components contribute to a planning criterion: the learned component contributes predicted traversability as rewards, while the geometric component contributes obstacle cost information. We instantiate and comparatively evaluate our system in both in-distribution and out-of-distribution environments, showing that this approach inherits complementary gains from the learned and geometric components and significantly outperforms either of them. Videos of our results are hosted at https://sites.google.com/view/hybrid-imitative-planning
Offline Preference-Based Apprenticeship Learning
Jul 22, 2021
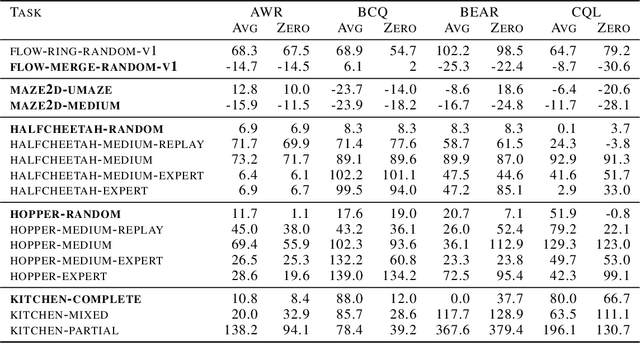


We study how an offline dataset of prior (possibly random) experience can be used to address two challenges that autonomous systems face when they endeavor to learn from, adapt to, and collaborate with humans : (1) identifying the human's intent and (2) safely optimizing the autonomous system's behavior to achieve this inferred intent. First, we use the offline dataset to efficiently infer the human's reward function via pool-based active preference learning. Second, given this learned reward function, we perform offline reinforcement learning to optimize a policy based on the inferred human intent. Crucially, our proposed approach does not require actual physical rollouts or an accurate simulator for either the reward learning or policy optimization steps, enabling both safe and efficient apprenticeship learning. We identify and evaluate our approach on a subset of existing offline RL benchmarks that are well suited for offline reward learning and also evaluate extensions of these benchmarks which allow more open-ended behaviors. Our experiments show that offline preference-based reward learning followed by offline reinforcement learning enables efficient and high-performing policies, while only requiring small numbers of preference queries. Videos available at https://sites.google.com/view/offline-prefs.