 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Preference-Based Apprenticeship Learning
Paper and Code
Jul 22, 2021
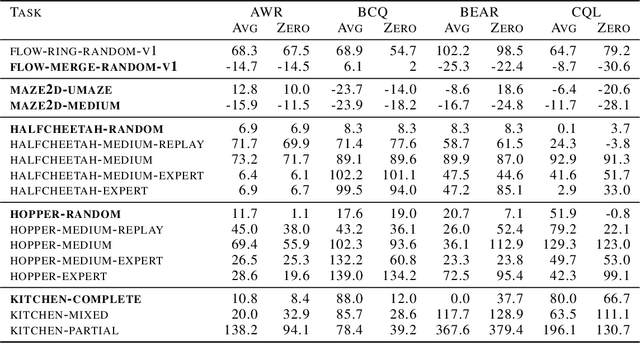


We study how an offline dataset of prior (possibly random) experience can be used to address two challenges that autonomous systems face when they endeavor to learn from, adapt to, and collaborate with humans : (1) identifying the human's intent and (2) safely optimizing the autonomous system's behavior to achieve this inferred intent. First, we use the offline dataset to efficiently infer the human's reward function via pool-based active preference learning. Second, given this learned reward function, we perform offline reinforcement learning to optimize a policy based on the inferred human intent. Crucially, our proposed approach does not require actual physical rollouts or an accurate simulator for either the reward learning or policy optimization steps, enabling both safe and efficient apprenticeship learning. We identify and evaluate our approach on a subset of existing offline RL benchmarks that are well suited for offline reward learning and also evaluate extensions of these benchmarks which allow more open-ended behaviors. Our experiments show that offline preference-based reward learning followed by offline reinforcement learning enables efficient and high-performing policies, while only requiring small numbers of preference queries. Videos available at https://sites.google.com/view/offline-prefs.