 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020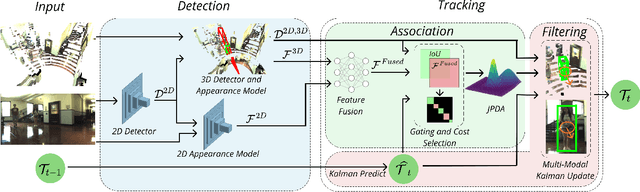
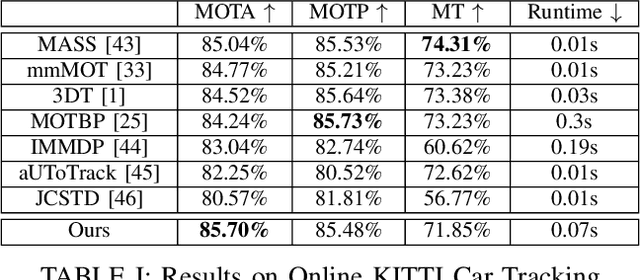
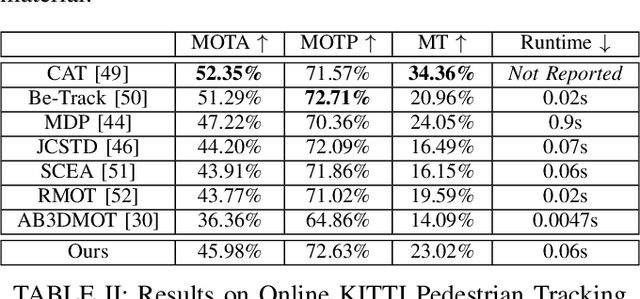
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction
Feb 20, 2020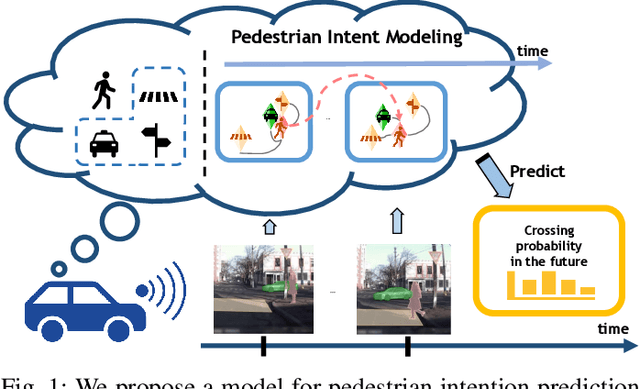
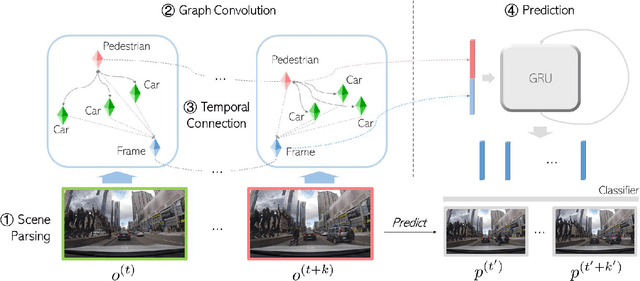


Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting of the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this paper, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is a very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomous-driving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on \rev{Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform the baseline and previous work. Please refer to http://stip.stanford.edu/ for the dataset and code.
JRDB: A Dataset and Benchmark for Visual Perception for Navigation in Human Environments
Oct 25, 2019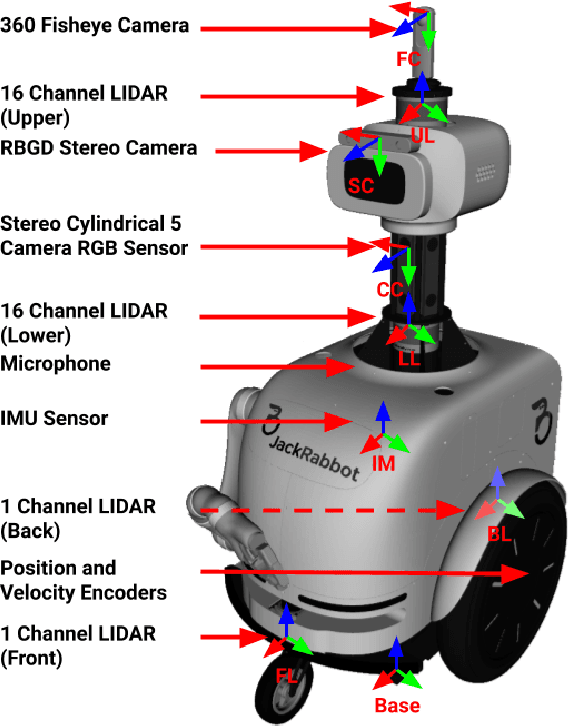
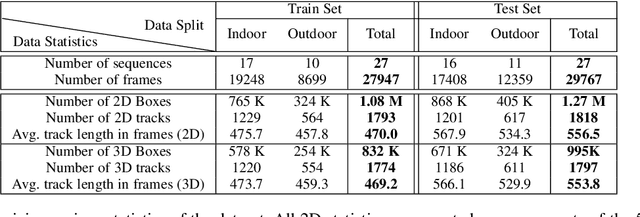
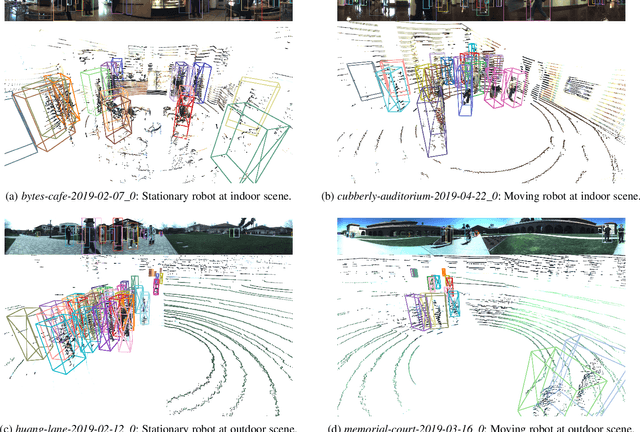
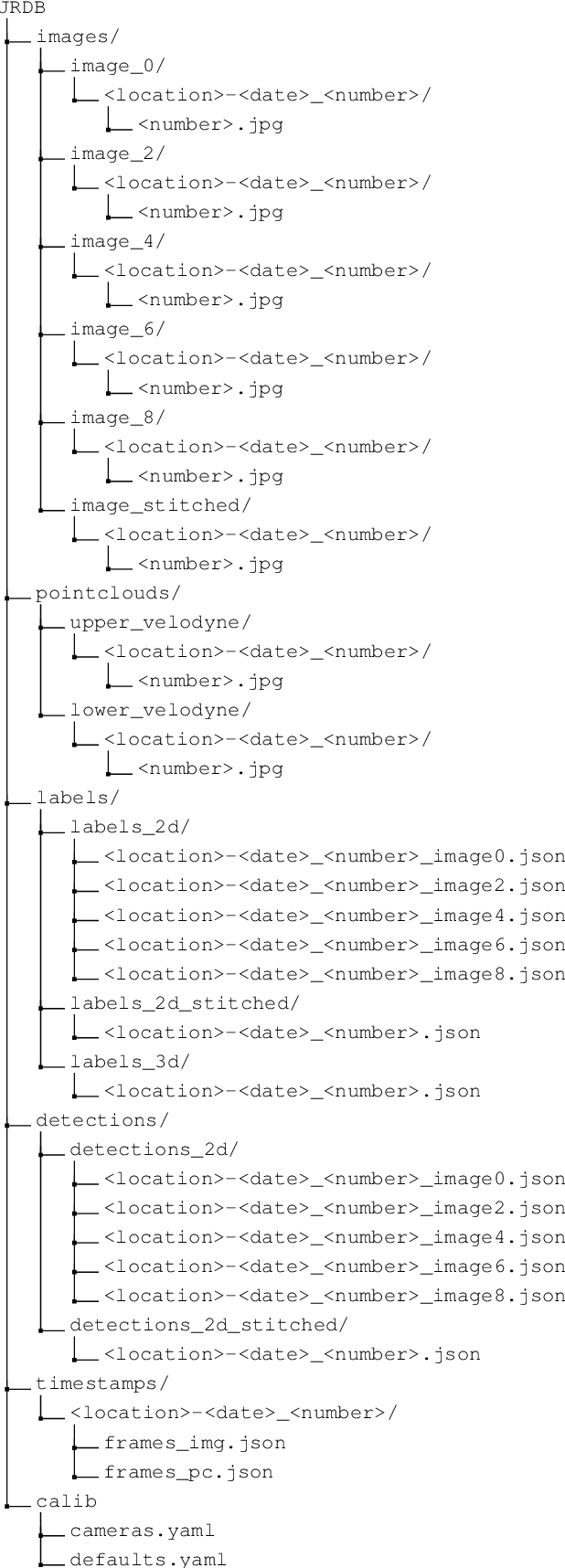
We present JRDB, a novel dataset collected from our social mobile manipulator JackRabbot. The dataset includes 64 minutes of multimodal sensor data including stereo cylindrical 360$^\circ$ RGB video at 15 fps, 3D point clouds from two Velodyne 16 Lidars, line 3D point clouds from two Sick Lidars, audio signal, RGBD video at 30 fps, 360$^\circ$ spherical image from a fisheye camera and encoder values from the robot's wheels. Our dataset includes data from traditionally underrepresented scenes such as indoor environments and pedestrian areas, from both stationary and navigating robot platform. The dataset has been annotated with over 2.3 million bounding boxes spread over 5 individual cameras and 1.8 million associated 3D cuboids around all people in the scenes totalling over 3500 time consistent trajectories. Together with our dataset and the annotations, we launch a benchmark and metrics for 2D and 3D person detection and tracking. With this dataset, that we plan on further annotating in the future, we hope to provide a new source of data and a test-bench for research in the areas of robot autonomous navigation and all perceptual tasks around social robotics in human environments.