 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Neutralizing Subjective Bias in Text
Dec 12, 2019


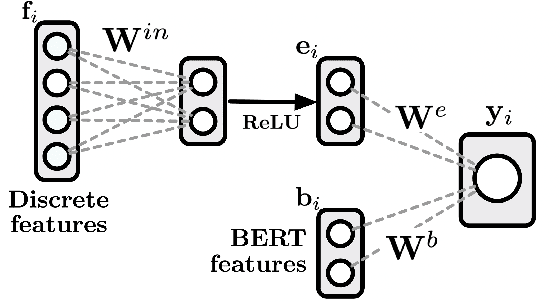
Texts like news, encyclopedias, and some social media strive for objectivity. Yet bias in the form of inappropriate subjectivity - introducing attitudes via framing, presupposing truth, and casting doubt - remains ubiquitous. This kind of bias erodes our collective trust and fuels social conflict. To address this issue, we introduce a novel testbed for natural language generation: automatically bringing inappropriately subjective text into a neutral point of view ("neutralizing" biased text). We also offer the first parallel corpus of biased language. The corpus contains 180,000 sentence pairs and originates from Wikipedia edits that removed various framings, presuppositions, and attitudes from biased sentences. Last, we propose two strong encoder-decoder baselines for the task. A straightforward yet opaque CONCURRENT system uses a BERT encoder to identify subjective words as part of the generation process. An interpretable and controllable MODULAR algorithm separates these steps, using (1) a BERT-based classifier to identify problematic words and (2) a novel join embedding through which the classifier can edit the hidden states of the encoder. Large-scale human evaluation across four domains (encyclopedias, news headlines, books, and political speeches) suggests that these algorithms are a first step towards the automatic identification and reduction of bias.
JRDB: A Dataset and Benchmark for Visual Perception for Navigation in Human Environments
Oct 25, 2019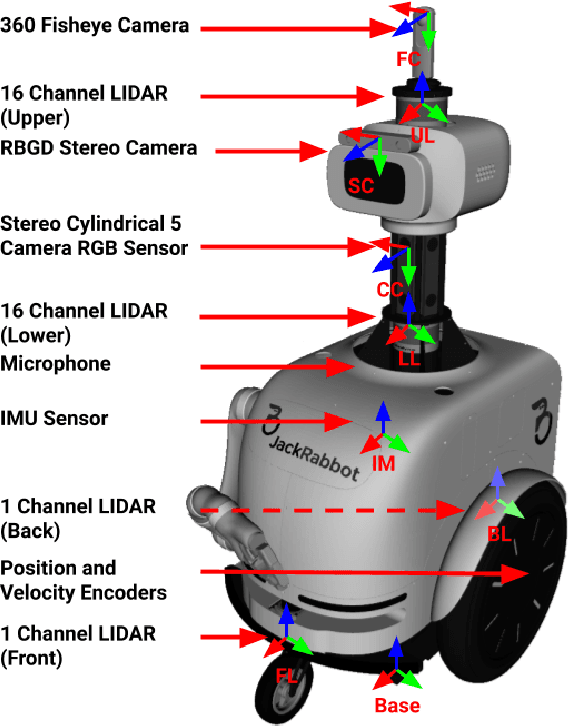
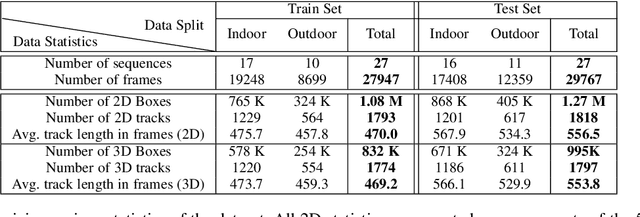
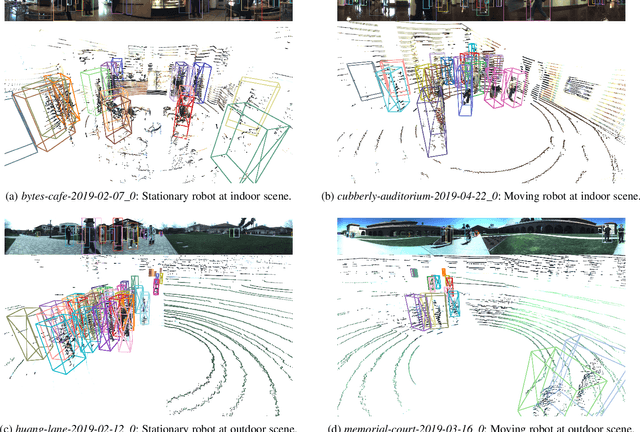
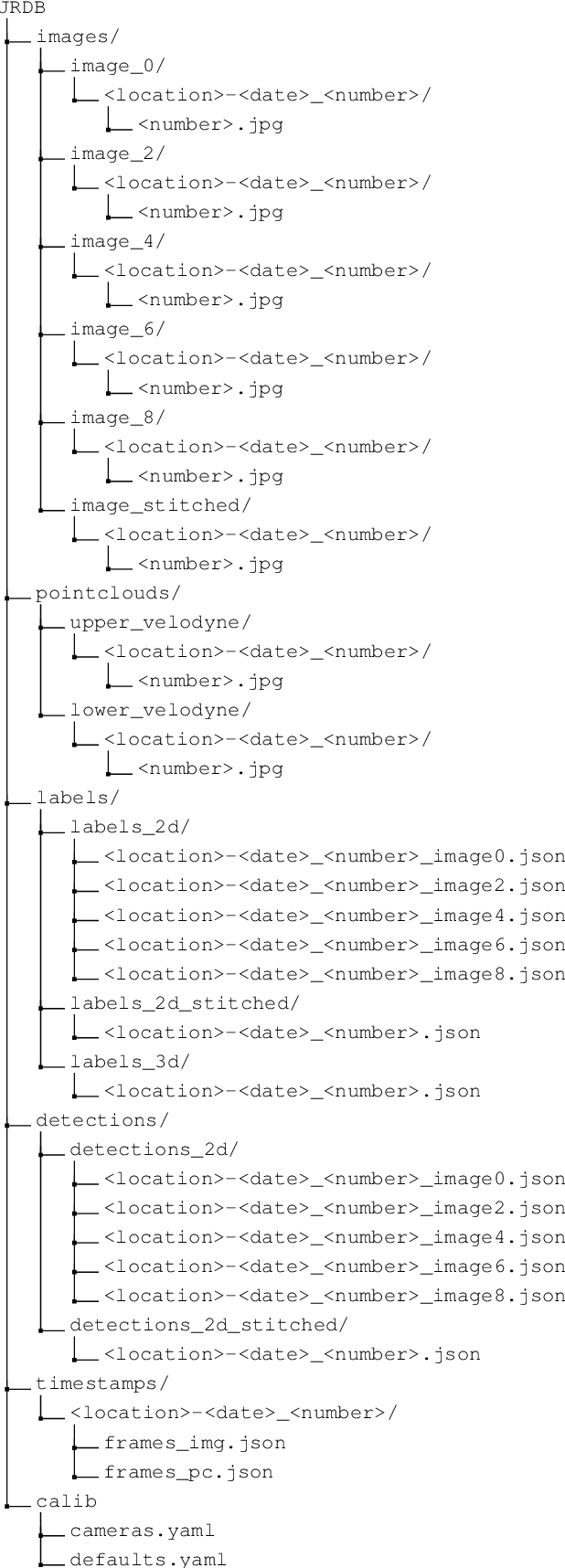
We present JRDB, a novel dataset collected from our social mobile manipulator JackRabbot. The dataset includes 64 minutes of multimodal sensor data including stereo cylindrical 360$^\circ$ RGB video at 15 fps, 3D point clouds from two Velodyne 16 Lidars, line 3D point clouds from two Sick Lidars, audio signal, RGBD video at 30 fps, 360$^\circ$ spherical image from a fisheye camera and encoder values from the robot's wheels. Our dataset includes data from traditionally underrepresented scenes such as indoor environments and pedestrian areas, from both stationary and navigating robot platform. The dataset has been annotated with over 2.3 million bounding boxes spread over 5 individual cameras and 1.8 million associated 3D cuboids around all people in the scenes totalling over 3500 time consistent trajectories. Together with our dataset and the annotations, we launch a benchmark and metrics for 2D and 3D person detection and tracking. With this dataset, that we plan on further annotating in the future, we hope to provide a new source of data and a test-bench for research in the areas of robot autonomous navigation and all perceptual tasks around social robotics in human environments.