 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess or More: Towards Glanceable Explanations for LLM Recommendations Using Ultra-Small Devices
Feb 26, 2025Large Language Models (LLMs) have shown remarkable potential in recommending everyday actions as personal AI assistants, while Explainable AI (XAI) techniques are being increasingly utilized to help users understand why a recommendation is given. Personal AI assistants today are often located on ultra-small devices such as smartwatches, which have limited screen space. The verbosity of LLM-generated explanations, however, makes it challenging to deliver glanceable LLM explanations on such ultra-small devices. To address this, we explored 1) spatially structuring an LLM's explanation text using defined contextual components during prompting and 2) presenting temporally adaptive explanations to users based on confidence levels. We conducted a user study to understand how these approaches impacted user experiences when interacting with LLM recommendations and explanations on ultra-small devices. The results showed that structured explanations reduced users' time to action and cognitive load when reading an explanation. Always-on structured explanations increased users' acceptance of AI recommendations. However, users were less satisfied with structured explanations compared to unstructured ones due to their lack of sufficient, readable details. Additionally, adaptively presenting structured explanations was less effective at improving user perceptions of the AI compared to the always-on structured explanations. Together with users' interview feedback, the results led to design implications to be mindful of when personalizing the content and timing of LLM explanations that are displayed on ultra-small devices.
Towards Human-AI Deliberation: Design and Evaluation of LLM-Empowered Deliberative AI for AI-Assisted Decision-Making
Mar 25, 2024



In AI-assisted decision-making, humans often passively review AI's suggestion and decide whether to accept or reject it as a whole. In such a paradigm, humans are found to rarely trigger analytical thinking and face difficulties in communicating the nuances of conflicting opinions to the AI when disagreements occur. To tackle this challenge, we propose Human-AI Deliberation, a novel framework to promote human reflection and discussion on conflicting human-AI opinions in decision-making. Based on theories in human deliberation, this framework engages humans and AI in dimension-level opinion elicitation, deliberative discussion, and decision updates. To empower AI with deliberative capabilities, we designed Deliberative AI, which leverages large language models (LLMs) as a bridge between humans and domain-specific models to enable flexible conversational interactions and faithful information provision. An exploratory evaluation on a graduate admissions task shows that Deliberative AI outperforms conventional explainable AI (XAI) assistants in improving humans' appropriate reliance and task performance. Based on a mixed-methods analysis of participant behavior, perception, user experience, and open-ended feedback, we draw implications for future AI-assisted decision tool design.
Beyond Recommender: An Exploratory Study of the Effects of Different AI Roles in AI-Assisted Decision Making
Mar 04, 2024



Artificial Intelligence (AI) is increasingly employed in various decision-making tasks, typically as a Recommender, providing recommendations that the AI deems correct. However, recent studies suggest this may diminish human analytical thinking and lead to humans' inappropriate reliance on AI, impairing the synergy in human-AI teams. In contrast, human advisors in group decision-making perform various roles, such as analyzing alternative options or criticizing decision-makers to encourage their critical thinking. This diversity of roles has not yet been empirically explored in AI assistance. In this paper, we examine three AI roles: Recommender, Analyzer, and Devil's Advocate, and evaluate their effects across two AI performance levels. Our results show each role's distinct strengths and limitations in task performance, reliance appropriateness, and user experience. Notably, the Recommender role is not always the most effective, especially if the AI performance level is low, the Analyzer role may be preferable. These insights offer valuable implications for designing AI assistants with adaptive functional roles according to different situations.
Federated and distributed learning applications for electronic health records and structured medical data: A scoping review
Apr 14, 2023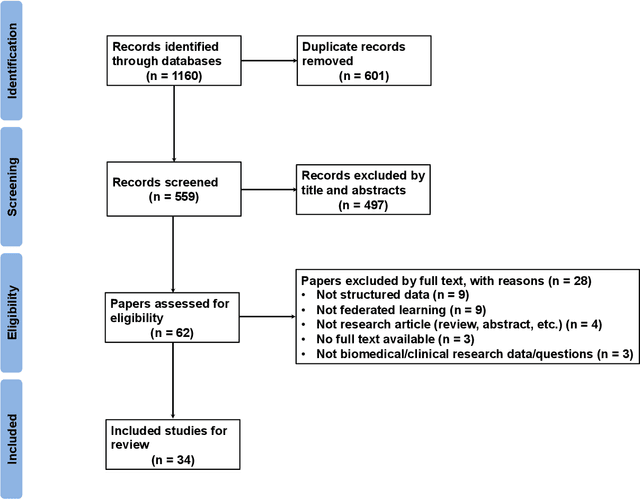


Federated learning (FL) has gained popularity in clinical research in recent years to facilitate privacy-preserving collaboration. Structured data, one of the most prevalent forms of clinical data, has experienced significant growth in volume concurrently, notably with the widespread adoption of electronic health records in clinical practice. This review examines FL applications on structured medical data, identifies contemporary limitations and discusses potential innovations. We searched five databases, SCOPUS, MEDLINE, Web of Science, Embase, and CINAHL, to identify articles that applied FL to structured medical data and reported results following the PRISMA guidelines. Each selected publication was evaluated from three primary perspectives, including data quality, modeling strategies, and FL frameworks. Out of the 1160 papers screened, 34 met the inclusion criteria, with each article consisting of one or more studies that used FL to handle structured clinical/medical data. Of these, 24 utilized data acquired from electronic health records, with clinical predictions and association studies being the most common clinical research tasks that FL was applied to. Only one article exclusively explored the vertical FL setting, while the remaining 33 explored the horizontal FL setting, with only 14 discussing comparisons between single-site (local) and FL (global) analysis. The existing FL applications on structured medical data lack sufficient evaluations of clinically meaningful benefits, particularly when compared to single-site analyses. Therefore, it is crucial for future FL applications to prioritize clinical motivations and develop designs and methodologies that can effectively support and aid clinical practice and research.
Who Should I Trust: AI or Myself? Leveraging Human and AI Correctness Likelihood to Promote Appropriate Trust in AI-Assisted Decision-Making
Jan 14, 2023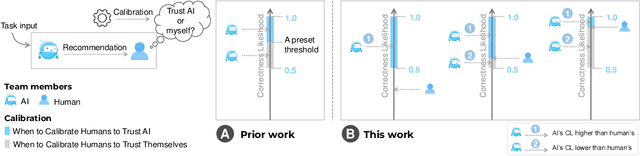
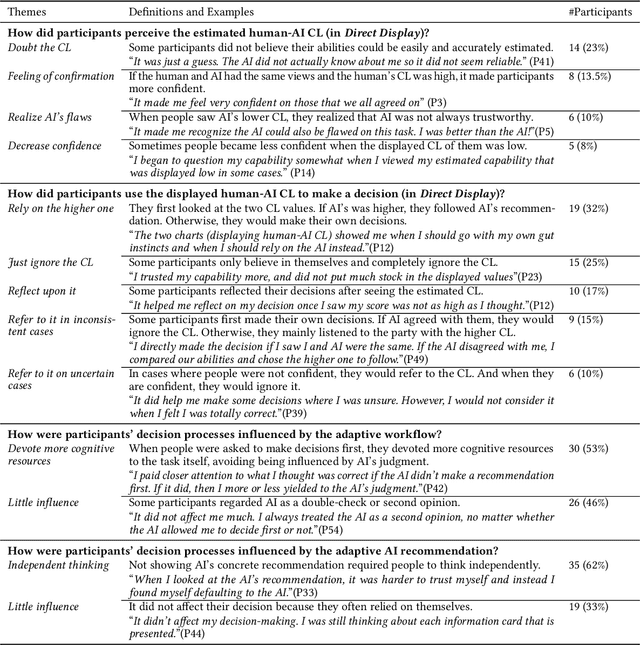
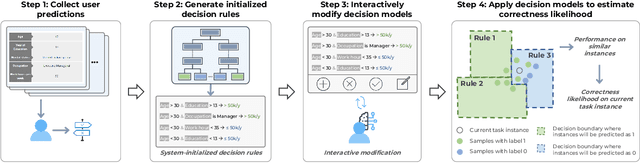
In AI-assisted decision-making, it is critical for human decision-makers to know when to trust AI and when to trust themselves. However, prior studies calibrated human trust only based on AI confidence indicating AI's correctness likelihood (CL) but ignored humans' CL, hindering optimal team decision-making. To mitigate this gap, we proposed to promote humans' appropriate trust based on the CL of both sides at a task-instance level. We first modeled humans' CL by approximating their decision-making models and computing their potential performance in similar instances. We demonstrated the feasibility and effectiveness of our model via two preliminary studies. Then, we proposed three CL exploitation strategies to calibrate users' trust explicitly/implicitly in the AI-assisted decision-making process. Results from a between-subjects experiment (N=293) showed that our CL exploitation strategies promoted more appropriate human trust in AI, compared with only using AI confidence. We further provided practical implications for more human-compatible AI-assisted decision-making.