 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry Fidelity for Spherical Images
Jul 25, 2024



Spherical or omni-directional images offer an immersive visual format appealing to a wide range of computer vision applications. However, geometric properties of spherical images pose a major challenge for models and metrics designed for ordinary 2D images. Here, we show that direct application of Fr\'echet Inception Distance (FID) is insufficient for quantifying geometric fidelity in spherical images. We introduce two quantitative metrics accounting for geometric constraints, namely Omnidirectional FID (OmniFID) and Discontinuity Score (DS). OmniFID is an extension of FID tailored to additionally capture field-of-view requirements of the spherical format by leveraging cubemap projections. DS is a kernel-based seam alignment score of continuity across borders of 2D representations of spherical images. In experiments, OmniFID and DS quantify geometry fidelity issues that are undetected by FID.
CvS: Classification via Segmentation For Small Datasets
Oct 29, 2021
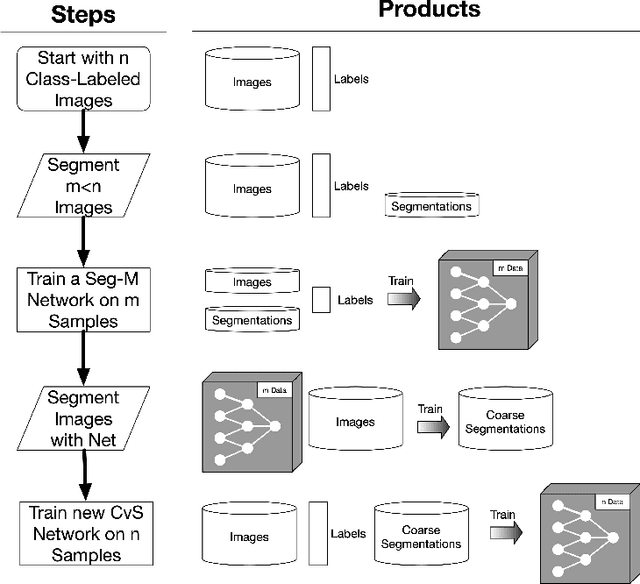
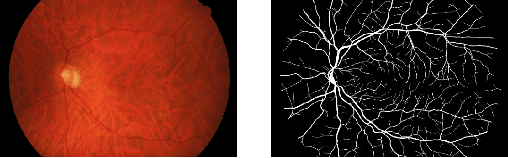
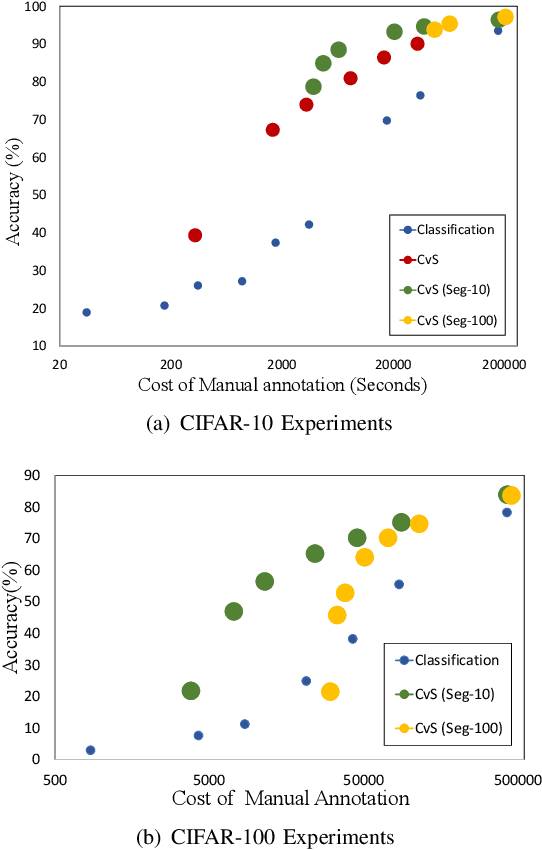
Deep learning models have shown promising results in a wide range of computer vision applications across various domains. The success of deep learning methods relies heavily on the availability of a large amount of data. Deep neural networks are prone to overfitting when data is scarce. This problem becomes even more severe for neural network with classification head with access to only a few data points. However, acquiring large-scale datasets is very challenging, laborious, or even infeasible in some domains. Hence, developing classifiers that are able to perform well in small data regimes is crucial for applications with limited data. This paper presents CvS, a cost-effective classifier for small datasets that derives the classification labels from predicting the segmentation maps. We employ the label propagation method to achieve a fully segmented dataset with only a handful of manually segmented data. We evaluate the effectiveness of our framework on diverse problems showing that CvS is able to achieve much higher classification results compared to previous methods when given only a handful of examples.
I-ODA, Real-World Multi-modal Longitudinal Data for OphthalmicApplications
Mar 30, 2021
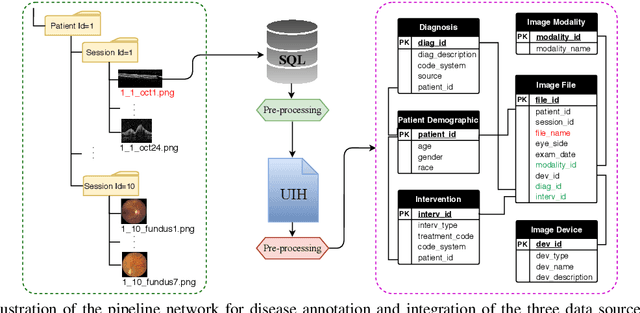
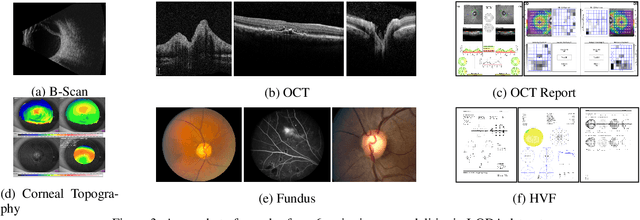
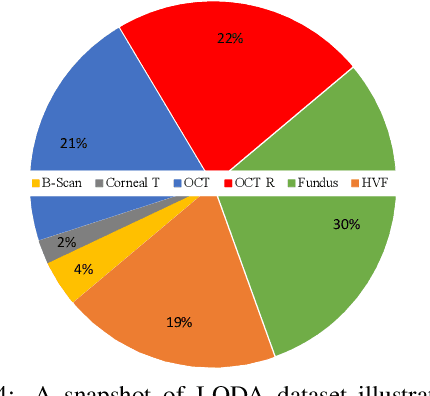
Data from clinical real-world settings is characterized by variability in quality, machine-type, setting, and source. One of the primary goals of medical computer vision is to develop and validate artificial intelligence (AI) based algorithms on real-world data enabling clinical translations. However, despite the exponential growth in AI based applications in healthcare, specifically in ophthalmology, translations to clinical settings remain challenging. Limited access to adequate and diverse real-world data inhibits the development and validation of translatable algorithms. In this paper, we present a new multi-modal longitudinal ophthalmic imaging dataset, the Illinois Ophthalmic Database Atlas (I-ODA), with the goal of advancing state-of-the-art computer vision applications in ophthalmology, and improving upon the translatable capacity of AI based applications across different clinical settings. We present the infrastructure employed to collect, annotate, and anonymize images from multiple sources, demonstrating the complexity of real-world retrospective data and its limitations. I-ODA includes 12 imaging modalities with a total of 3,668,649 ophthalmic images of 33,876 individuals from the Department of Ophthalmology and Visual Sciences at the Illinois Eye and Ear Infirmary of the University of Illinois Chicago (UIC) over the course of 12 years.
Real-World Multi-Domain Data Applications for Generalizations to Clinical Settings
Jul 24, 2020
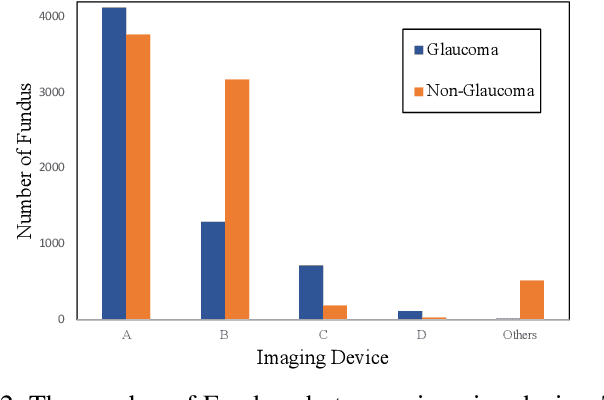
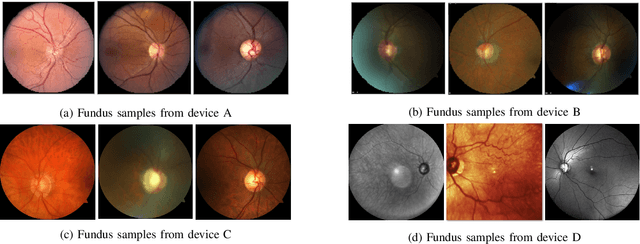

With promising results of machine learning based models in computer vision, applications on medical imaging data have been increasing exponentially. However, generalizations to complex real-world clinical data is a persistent problem. Deep learning models perform well when trained on standardized datasets from artificial settings, such as clinical trials. However, real-world data is different and translations are yielding varying results. The complexity of real-world applications in healthcare could emanate from a mixture of different data distributions across multiple device domains alongside the inevitable noise sourced from varying image resolutions, human errors, and the lack of manual gradings. In addition, healthcare applications not only suffer from the scarcity of labeled data, but also face limited access to unlabeled data due to HIPAA regulations, patient privacy, ambiguity in data ownership, and challenges in collecting data from different sources. These limitations pose additional challenges to applying deep learning algorithms in healthcare and clinical translations. In this paper, we utilize self-supervised representation learning methods, formulated effectively in transfer learning settings, to address limited data availability. Our experiments verify the importance of diverse real-world data for generalization to clinical settings. We show that by employing a self-supervised approach with transfer learning on a multi-domain real-world dataset, we can achieve 16% relative improvement on a standardized dataset over supervised baselines.
Leveraging Semi-Supervised Learning for Fairness using Neural Networks
Dec 31, 2019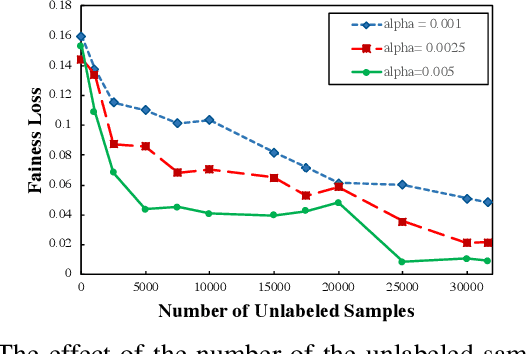
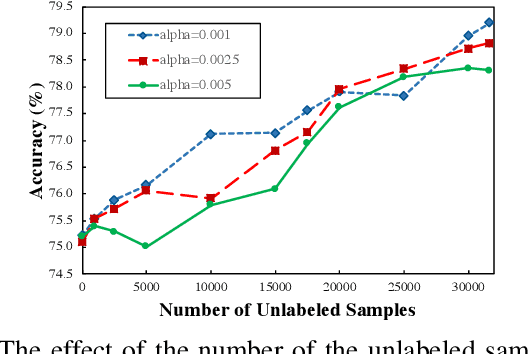
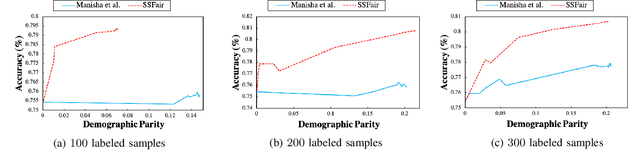
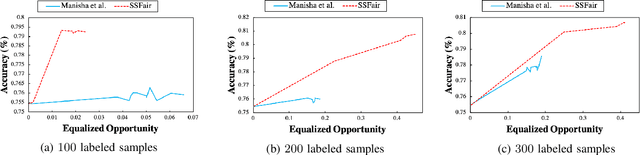
There has been a growing concern about the fairness of decision-making systems based on machine learning. The shortage of labeled data has been always a challenging problem facing machine learning based systems. In such scenarios, semi-supervised learning has shown to be an effective way of exploiting unlabeled data to improve upon the performance of model. Notably, unlabeled data do not contain label information which itself can be a significant source of bias in training machine learning systems. This inspired us to tackle the challenge of fairness by formulating the problem in a semi-supervised framework. In this paper, we propose a semi-supervised algorithm using neural networks benefiting from unlabeled data to not just improve the performance but also improve the fairness of the decision-making process. The proposed model, called SSFair, exploits the information in the unlabeled data to mitigate the bias in the training data.