 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHO-3D_v3: Improving the Accuracy of Hand-Object Annotations of the HO-3D Dataset
Paper and Code
Jul 02, 2021
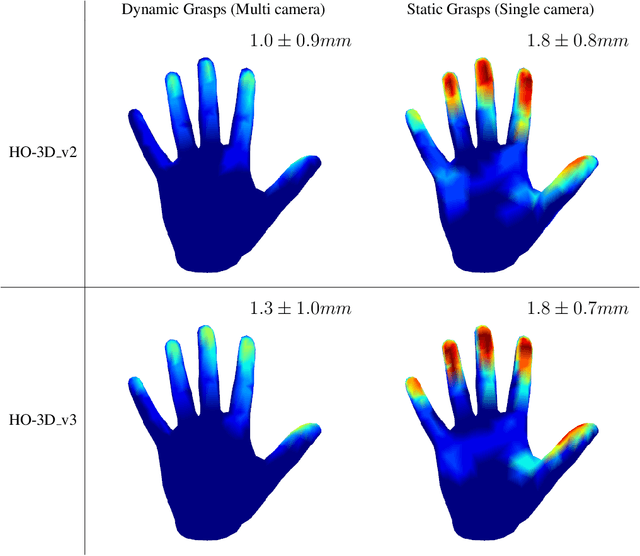
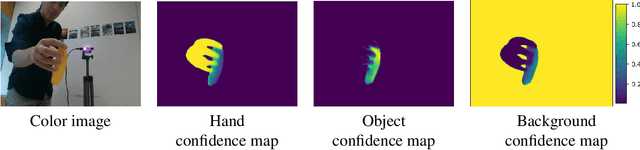
HO-3D is a dataset providing image sequences of various hand-object interaction scenarios annotated with the 3D pose of the hand and the object and was originally introduced as HO-3D_v2. The annotations were obtained automatically using an optimization method, 'HOnnotate', introduced in the original paper. HO-3D_v3 provides more accurate annotations for both the hand and object poses thus resulting in better estimates of contact regions between the hand and the object. In this report, we elaborate on the improvements to the HOnnotate method and provide evaluations to compare the accuracy of HO-3D_v2 and HO-3D_v3. HO-3D_v3 results in 4mm higher accuracy compared to HO-3D_v2 for hand poses while exhibiting higher contact regions with the object surface.