 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Mental Manipulation in Speech via Synthetic Multi-Speaker Dialogue
Jan 13, 2026Mental manipulation, the strategic use of language to covertly influence or exploit others, is a newly emerging task in computational social reasoning. Prior work has focused exclusively on textual conversations, overlooking how manipulative tactics manifest in speech. We present the first study of mental manipulation detection in spoken dialogues, introducing a synthetic multi-speaker benchmark SPEECHMENTALMANIP that augments a text-based dataset with high-quality, voice-consistent Text-to-Speech rendered audio. Using few-shot large audio-language models and human annotation, we evaluate how modality affects detection accuracy and perception. Our results reveal that models exhibit high specificity but markedly lower recall on speech compared to text, suggesting sensitivity to missing acoustic or prosodic cues in training. Human raters show similar uncertainty in the audio setting, underscoring the inherent ambiguity of manipulative speech. Together, these findings highlight the need for modality-aware evaluation and safety alignment in multimodal dialogue systems.
External Prompt Features Enhanced Parameter-efficient Fine-tuning for Salient Object Detection
Apr 23, 2024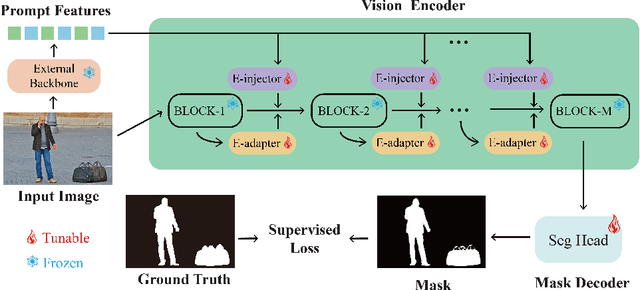
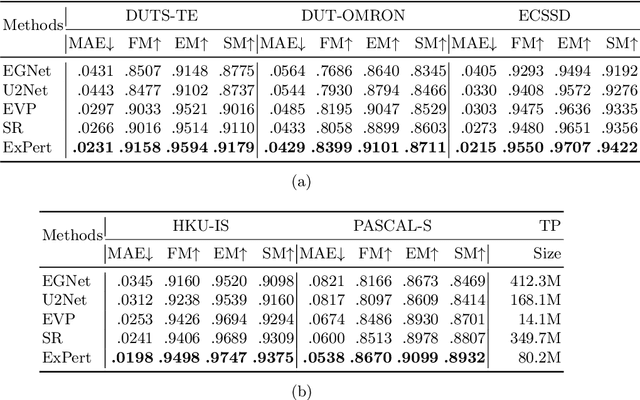
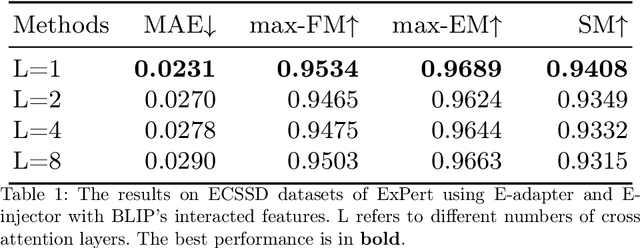

Salient object detection (SOD) aims at finding the most salient objects in images and outputs pixel-level binary masks. Transformer-based methods achieve promising performance due to their global semantic understanding, crucial for identifying salient objects. However, these models tend to be large and require numerous training parameters. To better harness the potential of transformers for SOD, we propose a novel parameter-efficient fine-tuning method aimed at reducing the number of training parameters while enhancing the salient object detection capability. Our model, termed EXternal Prompt features Enhanced adapteR Tuning (ExPert), features an encoder-decoder structure with adapters and injectors interspersed between the layers of a frozen transformer encoder. The adapter modules adapt the pre-trained backbone to SOD while the injector modules incorporate external prompt features to enhance the awareness of salient objects. Comprehensive experiments demonstrate the superiority of our method. Surpassing former state-of-the-art (SOTA) models across five SOD datasets, ExPert achieves 0.215 mean absolute error (MAE) in ECSSD dataset with 80.2M trained parameters, 21% better than transformer-based SOTA model and 47% better than CNN-based SOTA model.
Harnessing Intra-group Variations Via a Population-Level Context for Pathology Detection
Mar 04, 2024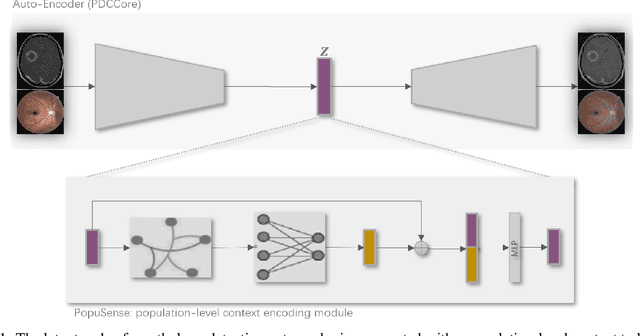
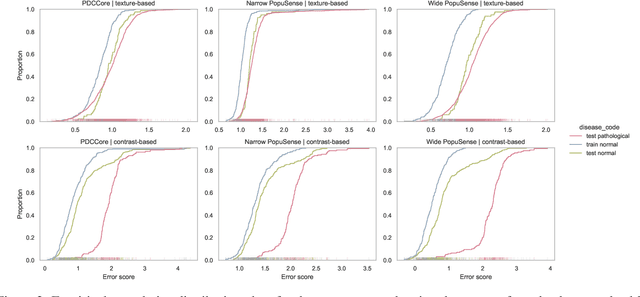
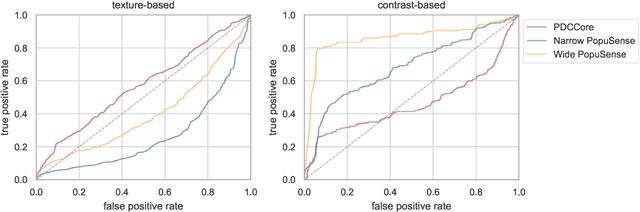
Realizing sufficient separability between the distributions of healthy and pathological samples is a critical obstacle for pathology detection convolutional models. Moreover, these models exhibit a bias for contrast-based images, with diminished performance on texture-based medical images. This study introduces the notion of a population-level context for pathology detection and employs a graph theoretic approach to model and incorporate it into the latent code of an autoencoder via a refinement module we term PopuSense. PopuSense seeks to capture additional intra-group variations inherent in biomedical data that a local or global context of the convolutional model might miss or smooth out. Experiments on contrast-based and texture-based images, with minimal adaptation, encounter the existing preference for intensity-based input. Nevertheless, PopuSense demonstrates improved separability in contrast-based images, presenting an additional avenue for refining representations learned by a model.
DrBERT: Unveiling the Potential of Masked Language Modeling Decoder in BERT pretraining
Jan 29, 2024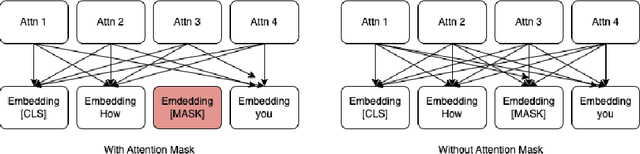

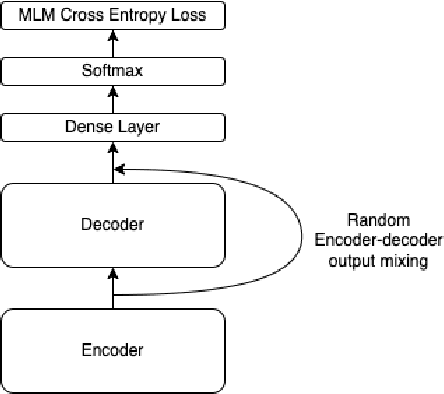
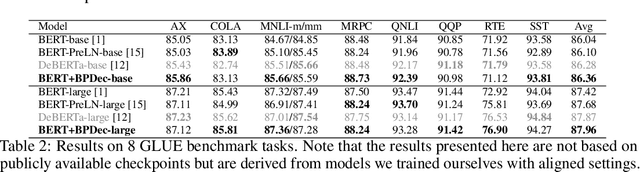
BERT (Bidirectional Encoder Representations from Transformers) has revolutionized the field of natural language processing through its exceptional performance on numerous tasks. Yet, the majority of researchers have mainly concentrated on enhancements related to the model structure, such as relative position embedding and more efficient attention mechanisms. Others have delved into pretraining tricks associated with Masked Language Modeling, including whole word masking. DeBERTa introduced an enhanced decoder adapted for BERT's encoder model for pretraining, proving to be highly effective. We argue that the design and research around enhanced masked language modeling decoders have been underappreciated. In this paper, we propose several designs of enhanced decoders and introduce DrBERT (Decoder-refined BERT), a novel method for modeling training. Typically, a pretrained BERT model is fine-tuned for specific Natural Language Understanding (NLU) tasks. In our approach, we utilize the original BERT model as the encoder, making only changes to the decoder without altering the encoder. This approach does not necessitate extensive modifications to the model's architecture and can be seamlessly integrated into existing fine-tuning pipelines and services, offering an efficient and effective enhancement strategy. Compared to other methods, while we also incur a moderate training cost for the decoder during the pretraining process, our approach does not introduce additional training costs during the fine-tuning phase. We test multiple enhanced decoder structures after pretraining and evaluate their performance on the GLUE benchmark. Our results demonstrate that DrBERT, having only undergone subtle refinements to the model structure during pretraining, significantly enhances model performance without escalating the inference time and serving budget.
A Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.
AlphaZero Gomoku
Sep 04, 2023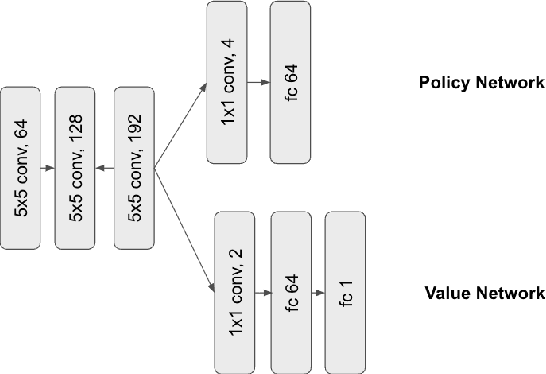
In the past few years, AlphaZero's exceptional capability in mastering intricate board games has garnered considerable interest. Initially designed for the game of Go, this revolutionary algorithm merges deep learning techniques with the Monte Carlo tree search (MCTS) to surpass earlier top-tier methods. In our study, we broaden the use of AlphaZero to Gomoku, an age-old tactical board game also referred to as "Five in a Row." Intriguingly, Gomoku has innate challenges due to a bias towards the initial player, who has a theoretical advantage. To add value, we strive for a balanced game-play. Our tests demonstrate AlphaZero's versatility in adapting to games other than Go. MCTS has become a predominant algorithm for decision processes in intricate scenarios, especially board games. MCTS creates a search tree by examining potential future actions and uses random sampling to predict possible results. By leveraging the best of both worlds, the AlphaZero technique fuses deep learning from Reinforcement Learning with the balancing act of MCTS, establishing a fresh standard in game-playing AI. Its triumph is notably evident in board games such as Go, chess, and shogi.
MiAMix: Enhancing Image Classification through a Multi-stage Augmented Mixed Sample Data Augmentation Method
Aug 15, 2023
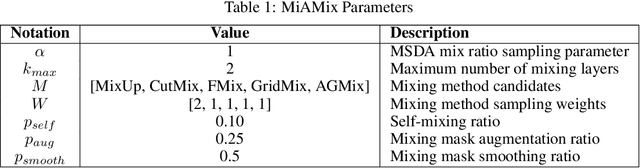
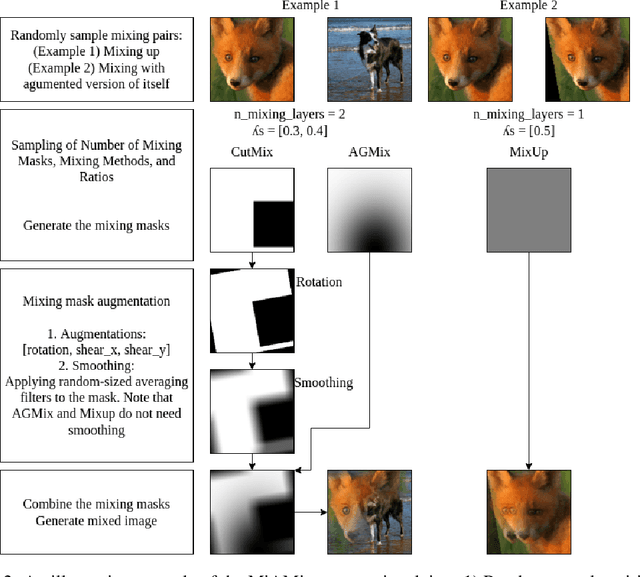
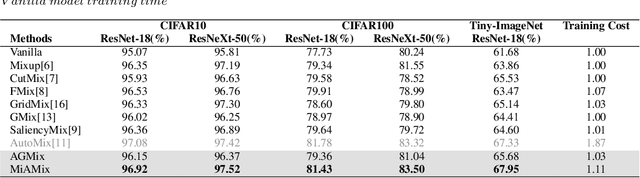
Despite substantial progress in the field of deep learning, overfitting persists as a critical challenge, and data augmentation has emerged as a particularly promising approach due to its capacity to enhance model generalization in various computer vision tasks. While various strategies have been proposed, Mixed Sample Data Augmentation (MSDA) has shown great potential for enhancing model performance and generalization. We introduce a novel mixup method called MiAMix, which stands for Multi-stage Augmented Mixup. MiAMix integrates image augmentation into the mixup framework, utilizes multiple diversified mixing methods concurrently, and improves the mixing method by randomly selecting mixing mask augmentation methods. Recent methods utilize saliency information and the MiAMix is designed for computational efficiency as well, reducing additional overhead and offering easy integration into existing training pipelines. We comprehensively evaluate MiaMix using four image benchmarks and pitting it against current state-of-the-art mixed sample data augmentation techniques to demonstrate that MIAMix improves performance without heavy computational overhead.
Cross-Attribute Matrix Factorization Model with Shared User Embedding
Aug 14, 2023
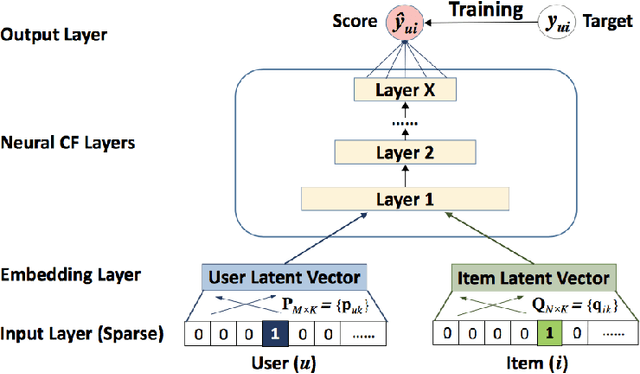
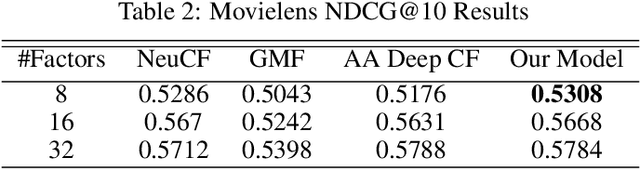
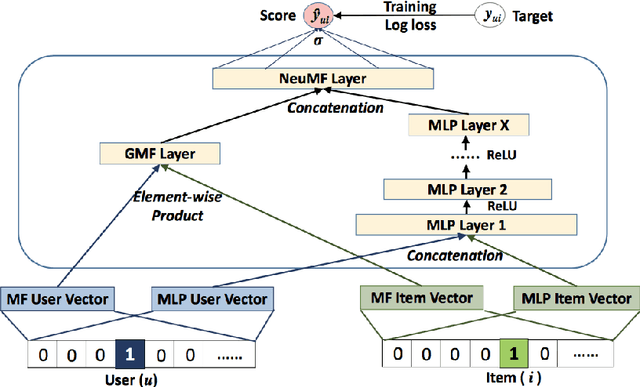
Over the past few years, deep learning has firmly established its prowess across various domains, including computer vision, speech recognition, and natural language processing. Motivated by its outstanding success, researchers have been directing their efforts towards applying deep learning techniques to recommender systems. Neural collaborative filtering (NCF) and Neural Matrix Factorization (NeuMF) refreshes the traditional inner product in matrix factorization with a neural architecture capable of learning complex and data-driven functions. While these models effectively capture user-item interactions, they overlook the specific attributes of both users and items. This can lead to robustness issues, especially for items and users that belong to the "long tail". Such challenges are commonly recognized in recommender systems as a part of the cold-start problem. A direct and intuitive approach to address this issue is by leveraging the features and attributes of the items and users themselves. In this paper, we introduce a refined NeuMF model that considers not only the interaction between users and items, but also acrossing associated attributes. Moreover, our proposed architecture features a shared user embedding, seamlessly integrating with user embeddings to imporve the robustness and effectively address the cold-start problem. Rigorous experiments on both the Movielens and Pinterest datasets demonstrate the superiority of our Cross-Attribute Matrix Factorization model, particularly in scenarios characterized by higher dataset sparsity.
ResWCAE: Biometric Pattern Image Denoising Using Residual Wavelet-Conditioned Autoencoder
Jul 23, 2023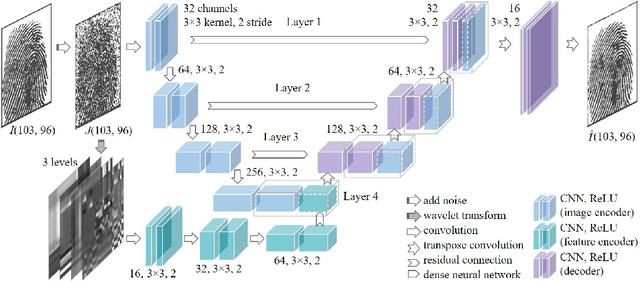
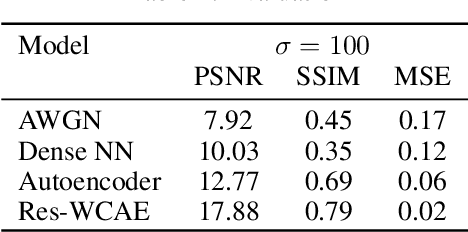
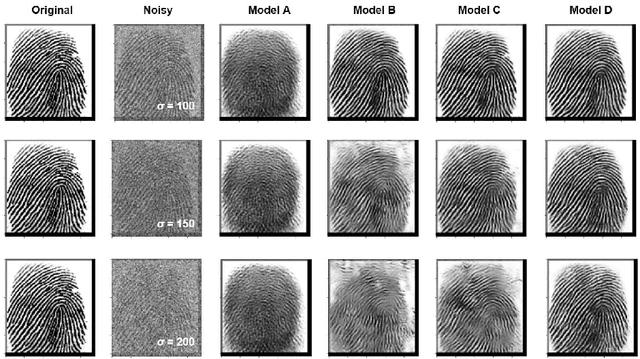
The utilization of biometric authentication with pattern images is increasingly popular in compact Internet of Things (IoT) devices. However, the reliability of such systems can be compromised by image quality issues, particularly in the presence of high levels of noise. While state-of-the-art deep learning algorithms designed for generic image denoising have shown promise, their large number of parameters and lack of optimization for unique biometric pattern retrieval make them unsuitable for these devices and scenarios. In response to these challenges, this paper proposes a lightweight and robust deep learning architecture, the Residual Wavelet-Conditioned Convolutional Autoencoder (Res-WCAE) with a Kullback-Leibler divergence (KLD) regularization, designed specifically for fingerprint image denoising. Res-WCAE comprises two encoders - an image encoder and a wavelet encoder - and one decoder. Residual connections between the image encoder and decoder are leveraged to preserve fine-grained spatial features, where the bottleneck layer conditioned on the compressed representation of features obtained from the wavelet encoder using approximation and detail subimages in the wavelet-transform domain. The effectiveness of Res-WCAE is evaluated against several state-of-the-art denoising methods, and the experimental results demonstrate that Res-WCAE outperforms these methods, particularly for heavily degraded fingerprint images in the presence of high levels of noise. Overall, Res-WCAE shows promise as a solution to the challenges faced by biometric authentication systems in compact IoT devices.
Futuristic Variations and Analysis in Fundus Images Corresponding to Biological Traits
Feb 08, 2023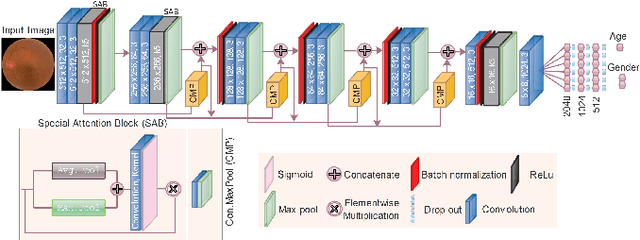
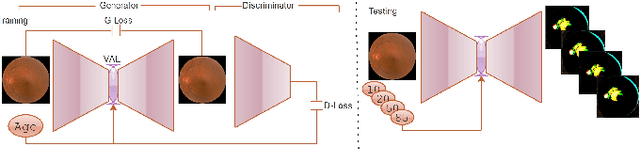
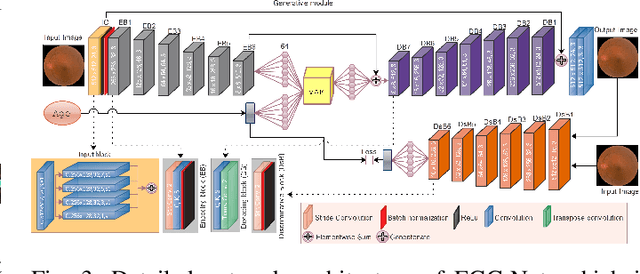

Fundus image captures rear of an eye, and which has been studied for the diseases identification, classification, segmentation, generation, and biological traits association using handcrafted, conventional, and deep learning methods. In biological traits estimation, most of the studies have been carried out for the age prediction and gender classification with convincing results. However, the current study utilizes the cutting-edge deep learning (DL) algorithms to estimate biological traits in terms of age and gender together with associating traits to retinal visuals. For the traits association, our study embeds aging as the label information into the proposed DL model to learn knowledge about the effected regions with aging. Our proposed DL models, named FAG-Net and FGC-Net, correspondingly estimate biological traits (age and gender) and generates fundus images. FAG-Net can generate multiple variants of an input fundus image given a list of ages as conditions. Our study analyzes fundus images and their corresponding association with biological traits, and predicts of possible spreading of ocular disease on fundus images given age as condition to the generative model. Our proposed models outperform the randomly selected state of-the-art DL models.