 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrBERT: Unveiling the Potential of Masked Language Modeling Decoder in BERT pretraining
Jan 29, 2024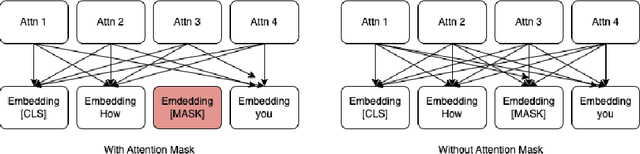

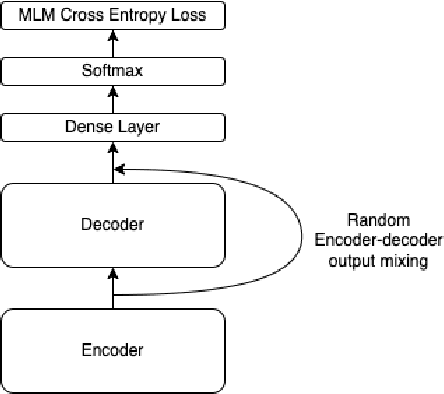
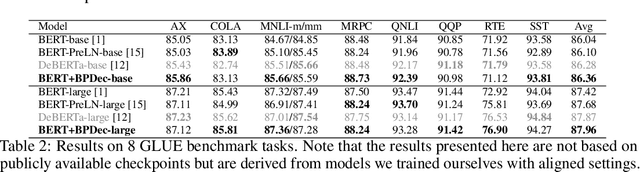
BERT (Bidirectional Encoder Representations from Transformers) has revolutionized the field of natural language processing through its exceptional performance on numerous tasks. Yet, the majority of researchers have mainly concentrated on enhancements related to the model structure, such as relative position embedding and more efficient attention mechanisms. Others have delved into pretraining tricks associated with Masked Language Modeling, including whole word masking. DeBERTa introduced an enhanced decoder adapted for BERT's encoder model for pretraining, proving to be highly effective. We argue that the design and research around enhanced masked language modeling decoders have been underappreciated. In this paper, we propose several designs of enhanced decoders and introduce DrBERT (Decoder-refined BERT), a novel method for modeling training. Typically, a pretrained BERT model is fine-tuned for specific Natural Language Understanding (NLU) tasks. In our approach, we utilize the original BERT model as the encoder, making only changes to the decoder without altering the encoder. This approach does not necessitate extensive modifications to the model's architecture and can be seamlessly integrated into existing fine-tuning pipelines and services, offering an efficient and effective enhancement strategy. Compared to other methods, while we also incur a moderate training cost for the decoder during the pretraining process, our approach does not introduce additional training costs during the fine-tuning phase. We test multiple enhanced decoder structures after pretraining and evaluate their performance on the GLUE benchmark. Our results demonstrate that DrBERT, having only undergone subtle refinements to the model structure during pretraining, significantly enhances model performance without escalating the inference time and serving budget.
A Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.
AlphaZero Gomoku
Sep 04, 2023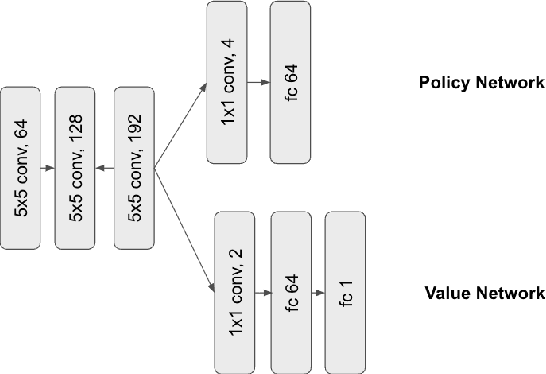
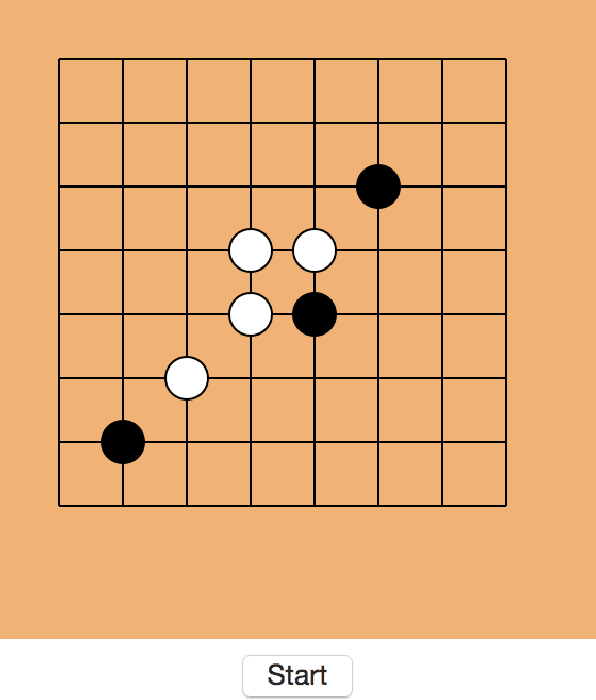
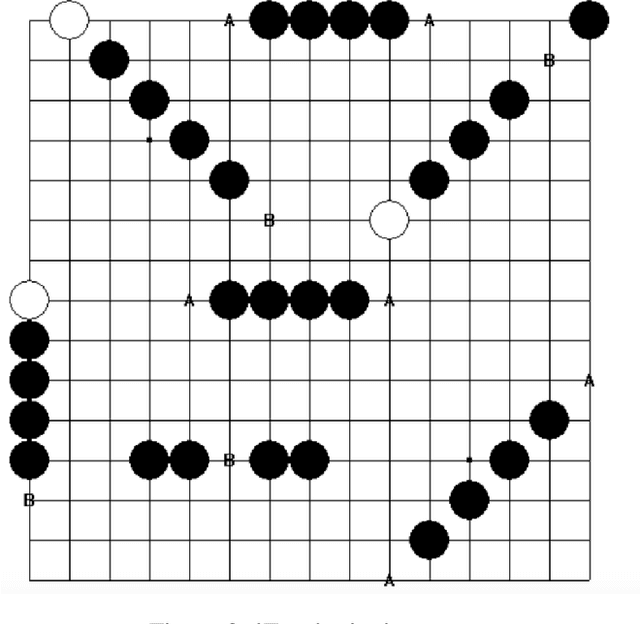
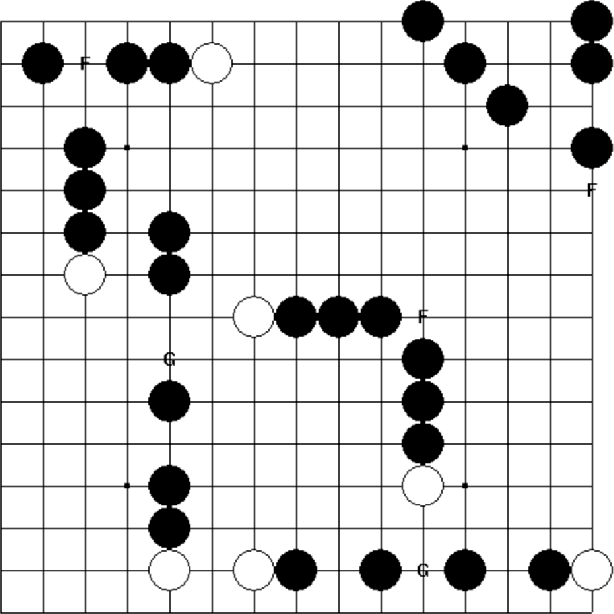
In the past few years, AlphaZero's exceptional capability in mastering intricate board games has garnered considerable interest. Initially designed for the game of Go, this revolutionary algorithm merges deep learning techniques with the Monte Carlo tree search (MCTS) to surpass earlier top-tier methods. In our study, we broaden the use of AlphaZero to Gomoku, an age-old tactical board game also referred to as "Five in a Row." Intriguingly, Gomoku has innate challenges due to a bias towards the initial player, who has a theoretical advantage. To add value, we strive for a balanced game-play. Our tests demonstrate AlphaZero's versatility in adapting to games other than Go. MCTS has become a predominant algorithm for decision processes in intricate scenarios, especially board games. MCTS creates a search tree by examining potential future actions and uses random sampling to predict possible results. By leveraging the best of both worlds, the AlphaZero technique fuses deep learning from Reinforcement Learning with the balancing act of MCTS, establishing a fresh standard in game-playing AI. Its triumph is notably evident in board games such as Go, chess, and shogi.
MiAMix: Enhancing Image Classification through a Multi-stage Augmented Mixed Sample Data Augmentation Method
Aug 15, 2023
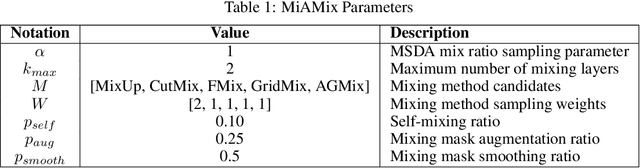
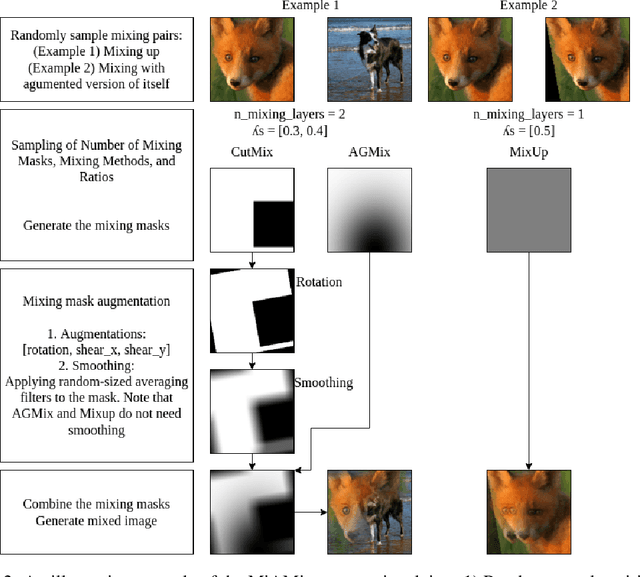
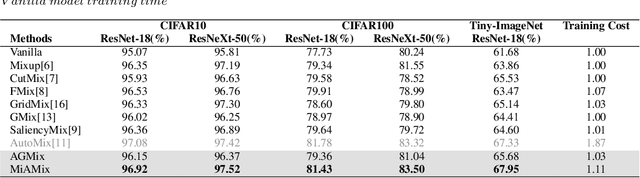
Despite substantial progress in the field of deep learning, overfitting persists as a critical challenge, and data augmentation has emerged as a particularly promising approach due to its capacity to enhance model generalization in various computer vision tasks. While various strategies have been proposed, Mixed Sample Data Augmentation (MSDA) has shown great potential for enhancing model performance and generalization. We introduce a novel mixup method called MiAMix, which stands for Multi-stage Augmented Mixup. MiAMix integrates image augmentation into the mixup framework, utilizes multiple diversified mixing methods concurrently, and improves the mixing method by randomly selecting mixing mask augmentation methods. Recent methods utilize saliency information and the MiAMix is designed for computational efficiency as well, reducing additional overhead and offering easy integration into existing training pipelines. We comprehensively evaluate MiaMix using four image benchmarks and pitting it against current state-of-the-art mixed sample data augmentation techniques to demonstrate that MIAMix improves performance without heavy computational overhead.
Cross-Attribute Matrix Factorization Model with Shared User Embedding
Aug 14, 2023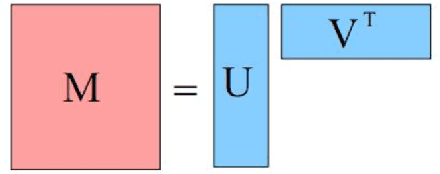
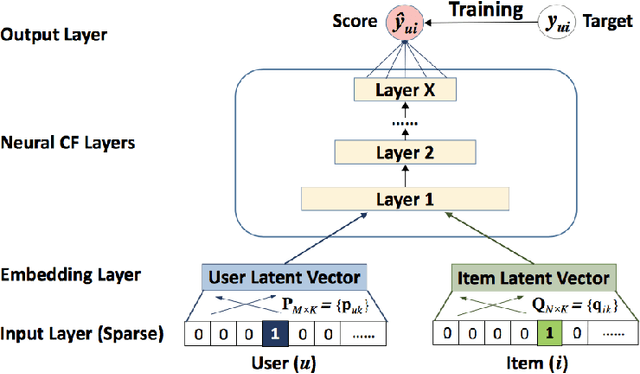
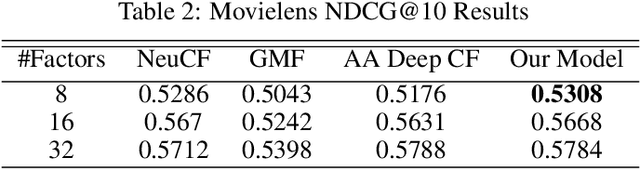
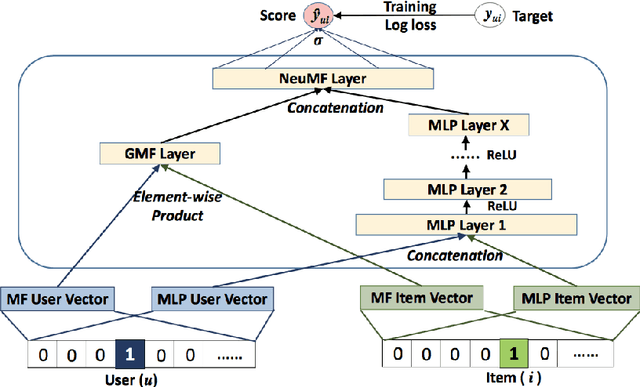
Over the past few years, deep learning has firmly established its prowess across various domains, including computer vision, speech recognition, and natural language processing. Motivated by its outstanding success, researchers have been directing their efforts towards applying deep learning techniques to recommender systems. Neural collaborative filtering (NCF) and Neural Matrix Factorization (NeuMF) refreshes the traditional inner product in matrix factorization with a neural architecture capable of learning complex and data-driven functions. While these models effectively capture user-item interactions, they overlook the specific attributes of both users and items. This can lead to robustness issues, especially for items and users that belong to the "long tail". Such challenges are commonly recognized in recommender systems as a part of the cold-start problem. A direct and intuitive approach to address this issue is by leveraging the features and attributes of the items and users themselves. In this paper, we introduce a refined NeuMF model that considers not only the interaction between users and items, but also acrossing associated attributes. Moreover, our proposed architecture features a shared user embedding, seamlessly integrating with user embeddings to imporve the robustness and effectively address the cold-start problem. Rigorous experiments on both the Movielens and Pinterest datasets demonstrate the superiority of our Cross-Attribute Matrix Factorization model, particularly in scenarios characterized by higher dataset sparsity.
ResWCAE: Biometric Pattern Image Denoising Using Residual Wavelet-Conditioned Autoencoder
Jul 23, 2023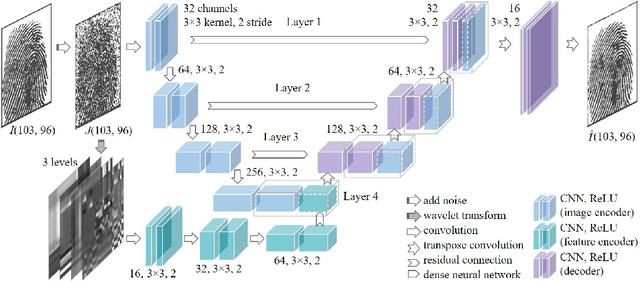
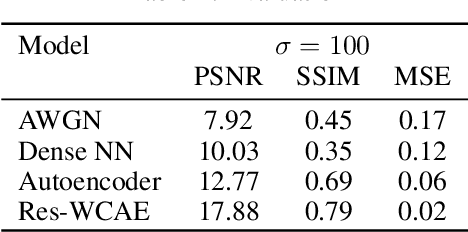
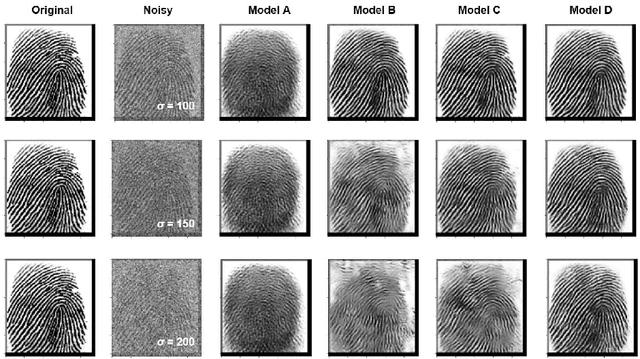
The utilization of biometric authentication with pattern images is increasingly popular in compact Internet of Things (IoT) devices. However, the reliability of such systems can be compromised by image quality issues, particularly in the presence of high levels of noise. While state-of-the-art deep learning algorithms designed for generic image denoising have shown promise, their large number of parameters and lack of optimization for unique biometric pattern retrieval make them unsuitable for these devices and scenarios. In response to these challenges, this paper proposes a lightweight and robust deep learning architecture, the Residual Wavelet-Conditioned Convolutional Autoencoder (Res-WCAE) with a Kullback-Leibler divergence (KLD) regularization, designed specifically for fingerprint image denoising. Res-WCAE comprises two encoders - an image encoder and a wavelet encoder - and one decoder. Residual connections between the image encoder and decoder are leveraged to preserve fine-grained spatial features, where the bottleneck layer conditioned on the compressed representation of features obtained from the wavelet encoder using approximation and detail subimages in the wavelet-transform domain. The effectiveness of Res-WCAE is evaluated against several state-of-the-art denoising methods, and the experimental results demonstrate that Res-WCAE outperforms these methods, particularly for heavily degraded fingerprint images in the presence of high levels of noise. Overall, Res-WCAE shows promise as a solution to the challenges faced by biometric authentication systems in compact IoT devices.
Vibration Signal Denoising Using Deep Learning
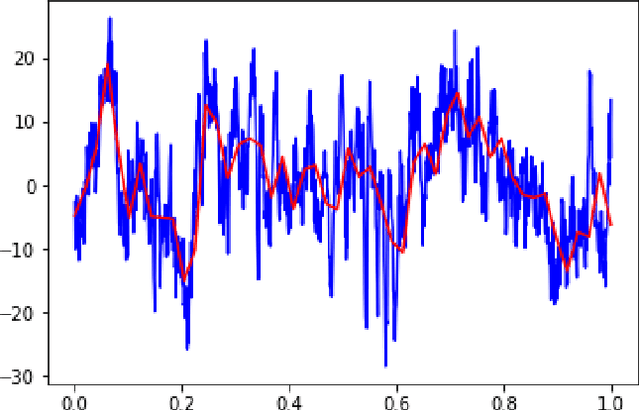
Mar 11, 2023Structure vibration signals induced by footsteps are widely used for tasks like occupant identification, localization, human activity inference, structure health monitoring and so on. The vibration signals are collected as time series with amplitude values. However, the collected signals are always noisy in practice due to the influence of environmental noise, electromagnetic interference and other factors. The presence of noise affects the process of signal analysis, thus affecting the accuracy and error of the final tasks. In this paper, we mainly explore the denoising methods for footstep-induced vibration signals. We have considered different kinds of noise including stationary noises such as gaussian noises and non-stationary noises such as item-dropping vibration noise and music noises.
A Multi-Variate Triple-Regression Forecasting Algorithm for Long-Term Customized Allergy Season Prediction
May 10, 2020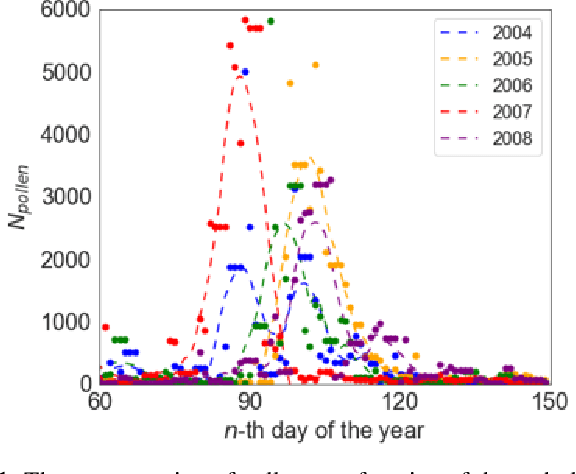
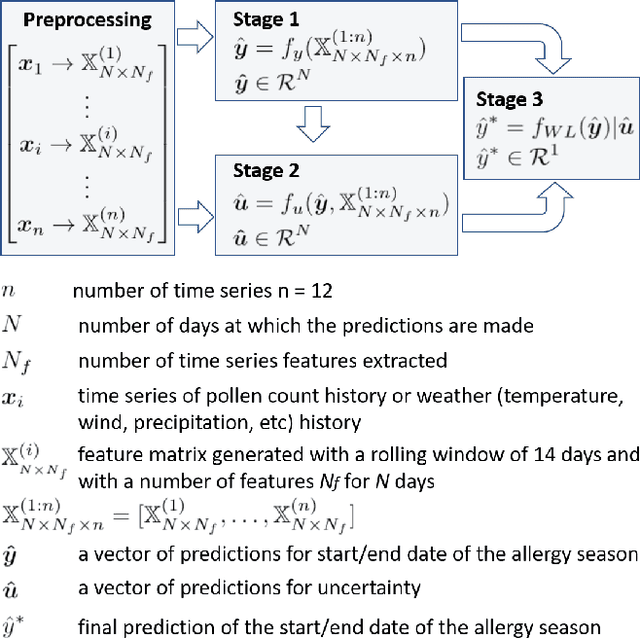
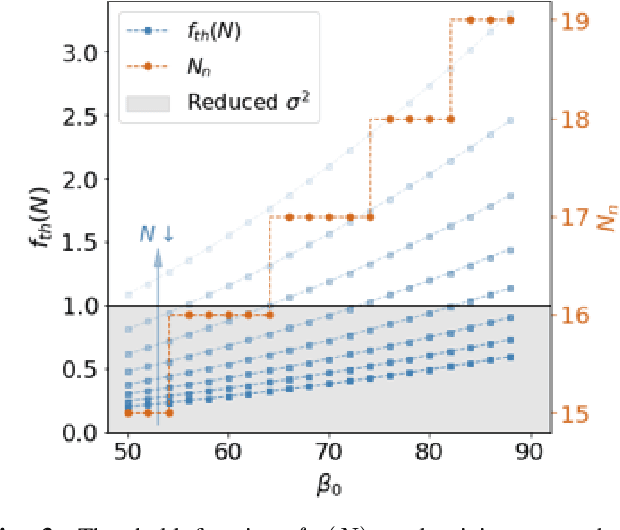
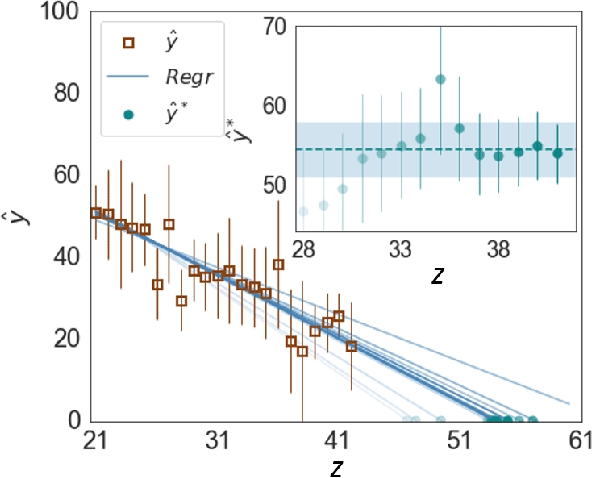
In this paper, we propose a novel multi-variate algorithm using a triple-regression methodology to predict the airborne-pollen allergy season that can be customized for each patient in the long term. To improve the prediction accuracy, we first perform a pre-processing to integrate the historical data of pollen concentration and various inferential signals from other covariates such as the meteorological data. We then propose a novel algorithm which encompasses three-stage regressions: in Stage 1, a regression model to predict the start/end date of a airborne-pollen allergy season is trained from a feature matrix extracted from 12 time series of the covariates with a rolling window; in Stage 2, a regression model to predict the corresponding uncertainty is trained based on the feature matrix and the prediction result from Stage 1; in Stage 3, a weighted linear regression model is built upon prediction results from Stage 1 and 2. It is observed and proved that Stage 3 contributes to the improved forecasting accuracy and the reduced uncertainty of the multi-variate triple-regression algorithm. Based on different allergy sensitivity level, the triggering concentration of the pollen - the definition of the allergy season can be customized individually. In our backtesting, a mean absolute error (MAE) of 4.7 days was achieved using the algorithm. We conclude that this algorithm could be applicable in both generic and long-term forecasting problems.
Mental Task Classification Using Electroencephalogram Signal
Oct 02, 2019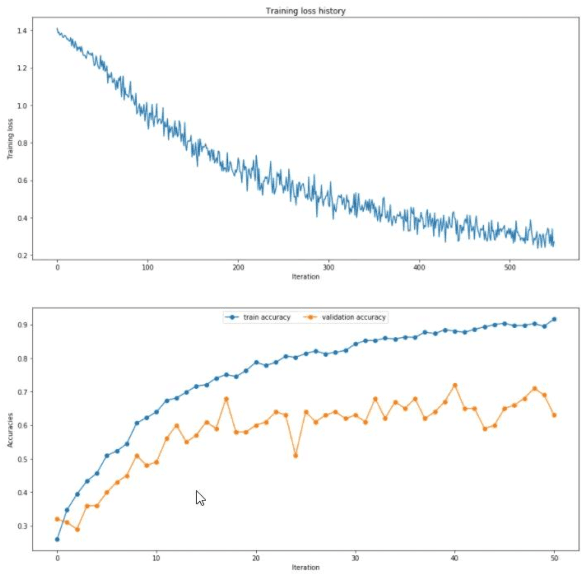
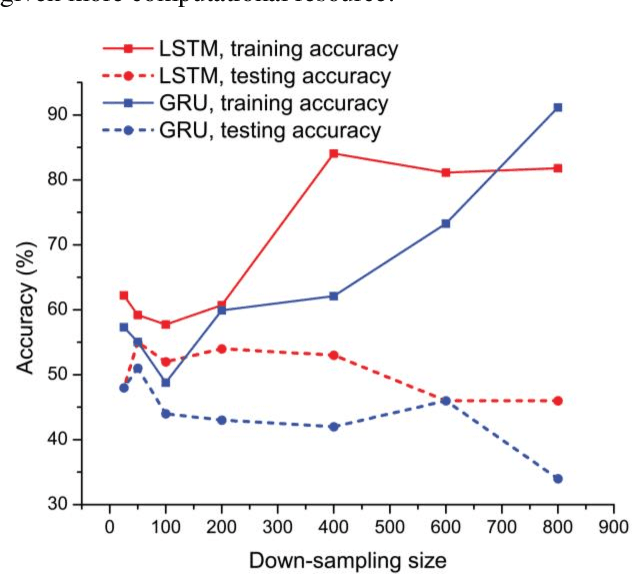
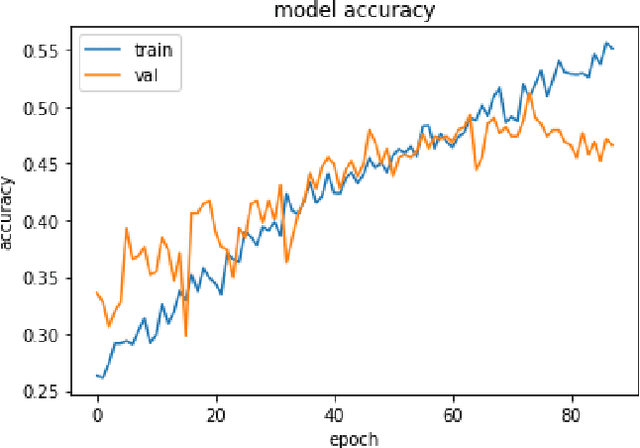
This paper studies the classification problem on electroencephalogram (EEG) data of mental tasks, using standard architecture of three-layer CNN, stacked LSTM, stacked GRU. We further propose a novel classifier - a mixed LSTM model with a CNN decoder. A hyperparameter optimization on CNN shows validation accuracy of 72% and testing accuracy of 62%. The stacked LSTM and GRU models with FFT preprocessing and downsampling on data achieve 55% and 51% testing accuracy respectively. As for the mixed LSTM model with CNN decoder, validation accuracy of 75% and testing accuracy of 70% are obtained. We believe the mixed model is more robust and accurate than both CNN and LSTM individually, by using the CNN layer as a decoder for following LSTM layers. The code is completed in the framework of Pytorch and Keras. Results and code can be found at https://github.com/theyou21/BigProject.