 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaZero Gomoku
Sep 04, 2023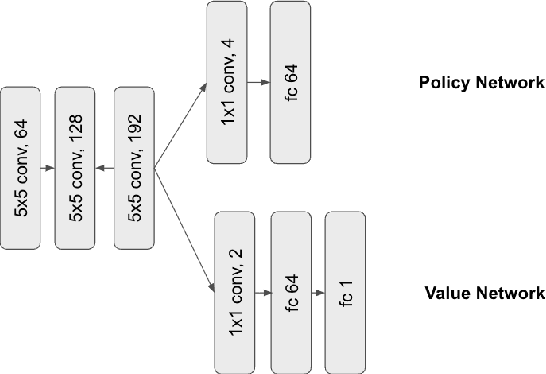
In the past few years, AlphaZero's exceptional capability in mastering intricate board games has garnered considerable interest. Initially designed for the game of Go, this revolutionary algorithm merges deep learning techniques with the Monte Carlo tree search (MCTS) to surpass earlier top-tier methods. In our study, we broaden the use of AlphaZero to Gomoku, an age-old tactical board game also referred to as "Five in a Row." Intriguingly, Gomoku has innate challenges due to a bias towards the initial player, who has a theoretical advantage. To add value, we strive for a balanced game-play. Our tests demonstrate AlphaZero's versatility in adapting to games other than Go. MCTS has become a predominant algorithm for decision processes in intricate scenarios, especially board games. MCTS creates a search tree by examining potential future actions and uses random sampling to predict possible results. By leveraging the best of both worlds, the AlphaZero technique fuses deep learning from Reinforcement Learning with the balancing act of MCTS, establishing a fresh standard in game-playing AI. Its triumph is notably evident in board games such as Go, chess, and shogi.