 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening
May 19, 2026Evaluating large language models (LLMs) on natural-language logical reasoning is essential because rule-governed tasks require conclusions to follow strictly from stated premises. Many existing logical-reasoning benchmarks are generated by templating natural-language items from sampled formulas, provide only coarse or unaudited formal annotations, and are now quickly saturated by frontier reasoning models. We present LLMEval-Logic, a Chinese logical reasoning benchmark built from realistic situational scenarios. Its pipeline forward-authors and expert-audits natural-language items together with their reference formalizations, verifies annotated answers with Z3, constructs expert rubrics for natural-to-formal grading, and hardens selected items through a closed-loop adversarial workflow. The benchmark is released in two paired subsets: a 246-item Base subset shipped with 1,400 expert-developed rubric atoms, and a 190-item Hard subset with 938 multi-step sub-questions over closed model spaces. Evaluating 14 frontier LLMs on LLMEval-Logic reveals substantial gaps in current models: the best model reaches only 37.5% Hard Item Accuracy, and even with reference symbols the highest joint Z3+Rubric formalization score among evaluated models reaches only 60.16%. Our benchmark is publicly available at https://github.com/llmeval/LLMEval-Logic.
Pseudo-Stereo Inputs: A Solution to the Occlusion Challenge in Self-Supervised Stereo Matching
Oct 03, 2024



Self-supervised stereo matching holds great promise for application and research due to its independence from expensive labeled data. However, direct self-supervised stereo matching paradigms based on photometric loss functions have consistently struggled with performance issues due to the occlusion challenge. The crux of the occlusion challenge lies in the fact that the positions of occluded pixels consistently align with the epipolar search direction defined by the input stereo images, leading to persistent information loss and erroneous feedback at fixed locations during self-supervised training. In this work, we propose a simple yet highly effective pseudo-stereo inputs strategy to address the core occlusion challenge. This strategy decouples the input and feedback images, compelling the network to probabilistically sample information from both sides of the occluding objects. As a result, the persistent lack of information in the aforementioned fixed occlusion areas is mitigated. Building upon this, we further address feedback conflicts and overfitting issues arising from the strategy. By integrating these components, our method achieves stable and significant performance improvements compared to existing methods. Quantitative experiments are conducted to evaluate the performance. Qualitative experiments further demonstrate accurate disparity inference even at occluded regions. These results demonstrate a significant advancement over previous methods in the field of direct self-supervised stereo matching based on photometric loss. The proposed pseudo-stereo inputs strategy, due to its simplicity and effectiveness, has the potential to serve as a new paradigm for direct self-supervised stereo matching. Code is available at https://github.com/qrzyang/Pseudo-Stereo.
Graph Neural Networks in EEG-based Emotion Recognition: A Survey
Feb 02, 2024



Compared to other modalities, EEG-based emotion recognition can intuitively respond to the emotional patterns in the human brain and, therefore, has become one of the most concerning tasks in the brain-computer interfaces field. Since dependencies within brain regions are closely related to emotion, a significant trend is to develop Graph Neural Networks (GNNs) for EEG-based emotion recognition. However, brain region dependencies in emotional EEG have physiological bases that distinguish GNNs in this field from those in other time series fields. Besides, there is neither a comprehensive review nor guidance for constructing GNNs in EEG-based emotion recognition. In the survey, our categorization reveals the commonalities and differences of existing approaches under a unified framework of graph construction. We analyze and categorize methods from three stages in the framework to provide clear guidance on constructing GNNs in EEG-based emotion recognition. In addition, we discuss several open challenges and future directions, such as Temporal full-connected graph and Graph condensation.
Semantic Connectivity-Driven Pseudo-labeling for Cross-domain Segmentation
Dec 11, 2023



Presently, self-training stands as a prevailing approach in cross-domain semantic segmentation, enhancing model efficacy by training with pixels assigned with reliable pseudo-labels. However, we find two critical limitations in this paradigm. (1) The majority of reliable pixels exhibit a speckle-shaped pattern and are primarily located in the central semantic region. This presents challenges for the model in accurately learning semantics. (2) Category noise in speckle pixels is difficult to locate and correct, leading to error accumulation in self-training. To address these limitations, we propose a novel approach called Semantic Connectivity-driven pseudo-labeling (SeCo). This approach formulates pseudo-labels at the connectivity level and thus can facilitate learning structured and low-noise semantics. Specifically, SeCo comprises two key components: Pixel Semantic Aggregation (PSA) and Semantic Connectivity Correction (SCC). Initially, PSA divides semantics into 'stuff' and 'things' categories and aggregates speckled pseudo-labels into semantic connectivity through efficient interaction with the Segment Anything Model (SAM). This enables us not only to obtain accurate boundaries but also simplifies noise localization. Subsequently, SCC introduces a simple connectivity classification task, which enables locating and correcting connectivity noise with the guidance of loss distribution. Extensive experiments demonstrate that SeCo can be flexibly applied to various cross-domain semantic segmentation tasks, including traditional unsupervised, source-free, and black-box domain adaptation, significantly improving the performance of existing state-of-the-art methods. The code is available at https://github.com/DZhaoXd/SeCo.
Electrocardiogram Classification and Visual Diagnosis of Atrial Fibrillation with DenseECG
Jan 19, 2021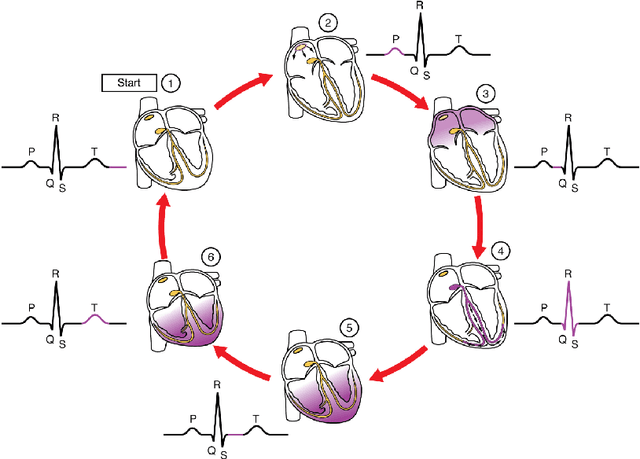
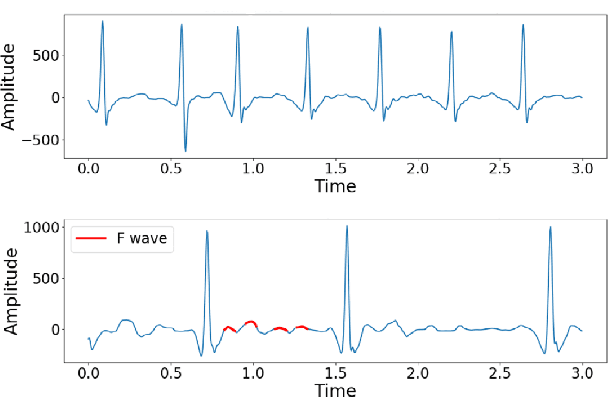
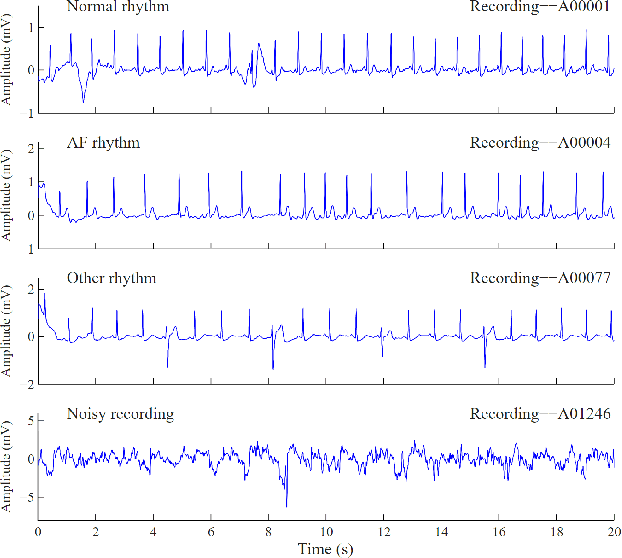
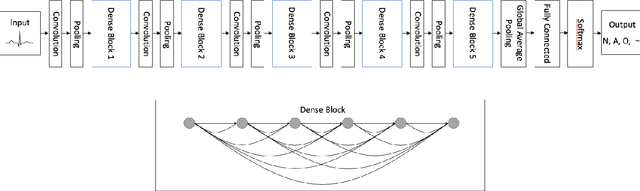
Atrial Fibrillation (AF) is a common cardiac arrhythmia affecting a large number of people around the world. If left undetected, it will develop into chronic disability or even early mortality. However, patients who have this problem can barely feel its presence, especially in its early stage. A non-invasive, automatic, and effective detection method is therefore needed to help early detection so that medical intervention can be implemented in time to prevent its progression. Electrocardiogram (ECG), which records the electrical activities of the heart, has been widely used for detecting the presence of AF. However, due to the subtle patterns of AF, the performance of detection models have largely depended on complicated data pre-processing and expertly engineered features. In our work, we developed DenseECG, an end-to-end model based on 5 layers 1D densely connected convolutional neural network. We trained our model using the publicly available dataset from 2017 PhysioNet Computing in Cardiology(CinC) Challenge containing 8528 single-lead ECG recordings of short-term heart rhythms (9-61s). Our trained model was able to outperform the other state-of-the-art AF detection models on this dataset without complicated data pre-processing and expert-supervised feature engineering.
Mental Task Classification Using Electroencephalogram Signal
Oct 02, 2019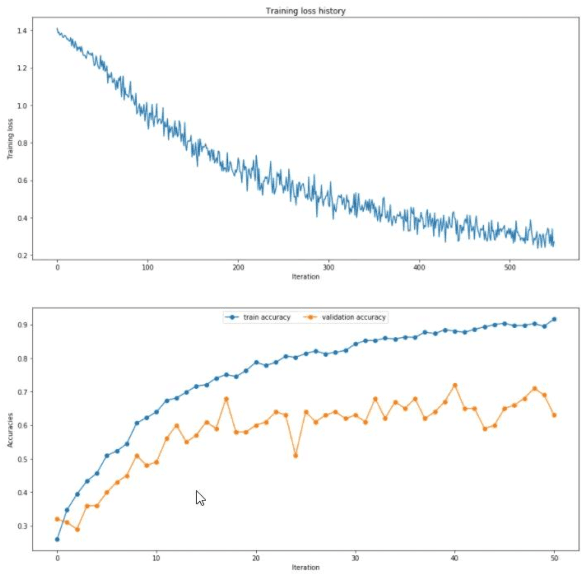
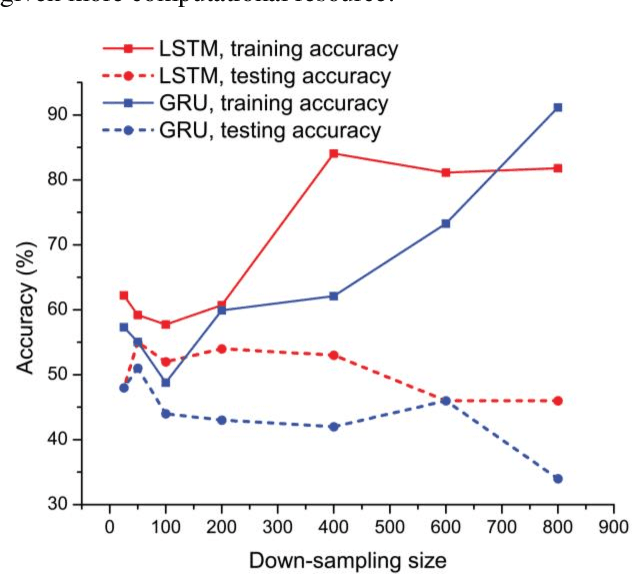
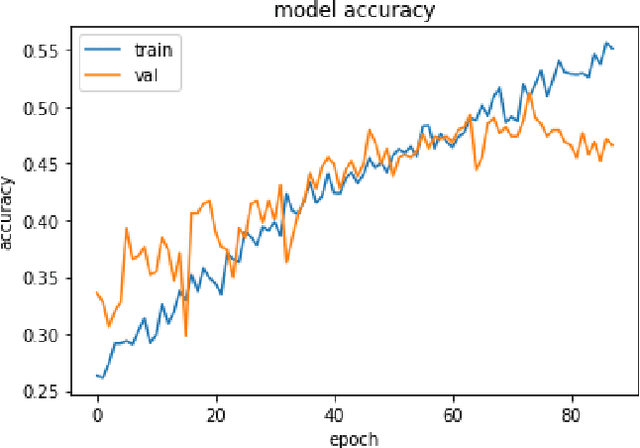
This paper studies the classification problem on electroencephalogram (EEG) data of mental tasks, using standard architecture of three-layer CNN, stacked LSTM, stacked GRU. We further propose a novel classifier - a mixed LSTM model with a CNN decoder. A hyperparameter optimization on CNN shows validation accuracy of 72% and testing accuracy of 62%. The stacked LSTM and GRU models with FFT preprocessing and downsampling on data achieve 55% and 51% testing accuracy respectively. As for the mixed LSTM model with CNN decoder, validation accuracy of 75% and testing accuracy of 70% are obtained. We believe the mixed model is more robust and accurate than both CNN and LSTM individually, by using the CNN layer as a decoder for following LSTM layers. The code is completed in the framework of Pytorch and Keras. Results and code can be found at https://github.com/theyou21/BigProject.